







前言
Google于2020年提出的Vision Transformer(ViT)在计算机视觉领域大放异彩,但其对图像分类的适应性进行了全局自注意力,通过计算一个标记和所有其他标记之间的关系,导致token数量的二次复杂性,使其不适合许多需要大量token进行密集预测或表示高分辨率图像的视觉问题。
本文介绍了一种名为 Swin Transformer 的新视觉 Transformer,由 Microsoft 研究团队于2021年提出,旨在解决传统 Transformer 模型在计算机视觉任务中的高计算复杂度问题。它基于ViT模型的思想,创新性的引入了分层架构和滑动窗口机制,让模型能够学习到跨窗口的信息,广泛应用于图像分类、目标检测、分割等视觉任务,已成为新一代的CV通用骨干。
本篇文章将深入探讨Swin Transformer(SwinT)的原理、架构,详细分析各模块的实现,并给出每个子模块以及Swin-T全部模型的代码注释。
一、模型整体框架
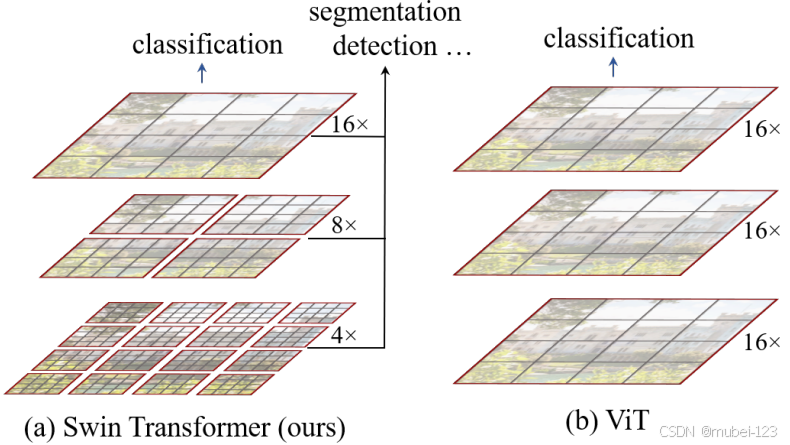
在正文开始之前,先来简单对比下Swin Transformer和Vision Transformer。如下图所示,左边是本文要讲的Swin Transformer,右边是之前讲的Vision Transformer。通过对比至少可以看出两点不同:
(1)Swin Transformer使用了类似卷积神经网络中的分层架构,这样的backbone有助于在此基础上构建目标检测,实例分割等任务。而之前的Vision Transformer一开始就直接16倍下采样,后面的特征图也是维持这个下采样率不变;
(2)Swin Transformer中使用了Windows Multi-Head Self-Attention(W-MSA)的概念,比如在4倍下采样和8倍下采样中,将特征图划分成了多个不相交的窗口(Window),并且Multi-Head Self-Attention只在每个窗口(Window)内进行。与Vision Transformer中直接对整个特征图进行Multi-Head Self-Attention相比,此方法能够减少计算量,尤其是在浅层特征图很大的时候。这样做虽然减少了计算量,但也会隔绝不同窗口之间的信息传递,在论文中作者又提出了 Shifted Windows Multi-Head Self-Attention(SW-MSA)的概念,通过此方法能够让信息在相邻的窗口中进行传递。
接下来,给出原论文中关于Swin Transformer(Swin-T)网络的架构图:
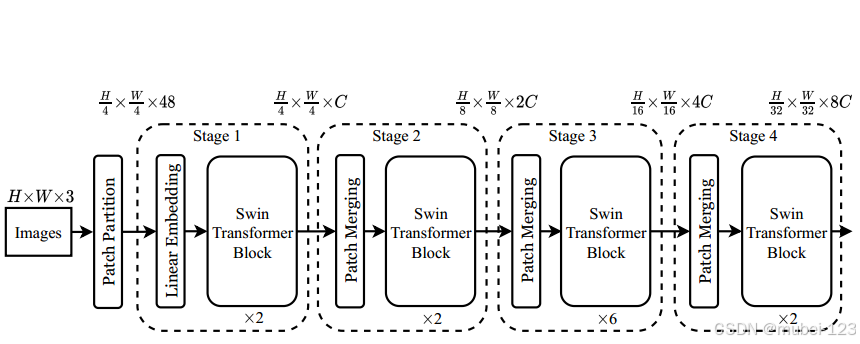
从架构图中可以看出,Swin-T主要由Patch Partition、Linear Embedding、Swin Transformer Block和Patch Merging组成:
(1)Patch Partition:此部分的主要作用是分块,在源码中和Linear Embedding一起通过一个卷积层实现;
(2)Linear Embedding:此部分的主要作用是对每个像素的channel数据做线性变换,在源码中和Patch Partition一起通过一个卷积层实现;
(3)Swin Transformer Block:此部分为Swin-T的核心,负责提取输入图片的特征向量,输入和输出的维度相同;
(4)Patch Merging:此部分的主要作用是进行下采样。
二、模型详解
2.1 Patch Partition
此部分的主要作用是将输入的图片做切块处理,即每4x4个相邻的像素为一个Patch,然后在channel方向展平(flatten)。假设输入的是RGB三通道图片,那么每个patch就有4x4=16个像素,然后每个像素有R、G、B三个值所以展平后是16x3=48,所以通过Patch Partition后图像形状由 [H, W, 3]变成了 [H/4, W/4, 48]。此步骤在源码中通过一个卷积层实现。
2.2 Linear Embedding
在经过Patch Partition层后,输入的图像形状变为[H/4, W/4, 48],然后通过Linear Embeding层对每个像素的channel数据做线性变换,由48变成C,即图像shape再由 [H/4, W/4, 48]变成 [H/4, W/4, C],此步骤在源码中通过一个卷积层实现。
2.3 Swin Transformer Block
给出Swin Transformer Block的框架图:
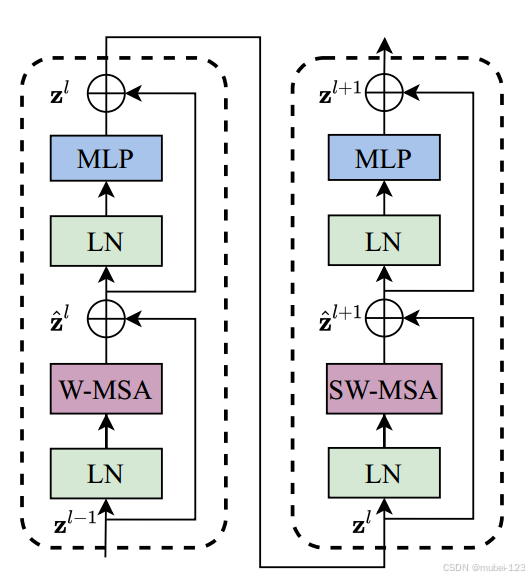
可以看出,Swin Transformer Block与Vision Transformer Block很相似,不同之处只有两点:
(1)Swin Transformer Block将标准多头自注意力模块 (MSA) 替换为基于移位窗口的多头自注意力模块 (W-MSA / SW-MSA);
(2)Swin Transformer Block有两种结构,这两种结构的不同之处仅在于一个使用了W-MSA结构,一个使用了SW-MSA结构。而且这两个结构是成对使用的,先使用一个W-MSA结构再使用一个SW-MSA结构,所以堆叠Swin Transformer Block的次数都是偶数。
下面,我们只对W-MSA 和 SW-MSA进行讲解,其他模块详见ViT原理详解,此处不再赘述:
2.3.1 W-MSA
引入 W-MSA 模块是为了减少计算量。如下图所示,左侧使用的是普通的多头注意力(MSA)模块,对于特征图中的每个像素(或称作token)需要和所有的像素计算自注意力。但在使用W-MSA模块时,首先将特征图按照MxM(例子中的M=2)大小划分成一个个窗口,然后单独对每个窗口内部进行自注意力计算。
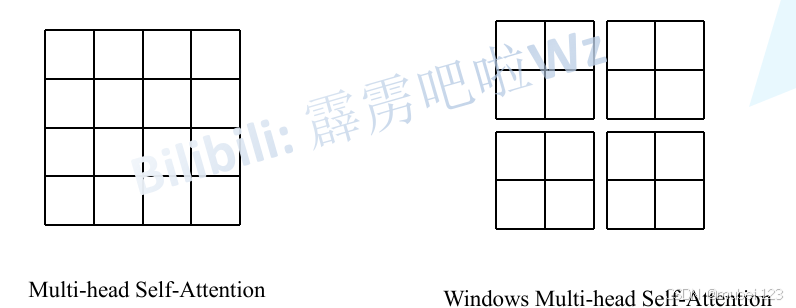
两者的计算量具体差多少呢?原论文中给出下面两个公式,这里忽略了Softmax的计算复杂度:
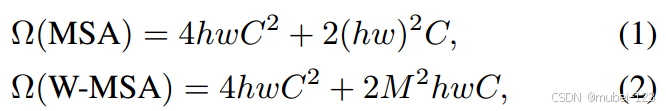
下面给出计算过程:
(1)MSA
对于特征图中的每个像素(或称作token),都要通过, 生成对应的Q,K以及V。这里假设Q, K和V的向量长度与特征图的深度C保持一致。那么对应所有像素生成Q的过程如下式:
根据矩阵运算的计算量公式可以得到生成Q的计算量为,同理K和V的计算量也是
,加起来就是
;
接下来Q和相乘,计算量为
:
接下来忽略除以以及softmax的计算量,乘以V,计算量为
:
最后拼接多头部分,计算量为:
总共加起来是
(2)W-MSA
对于W-MSA模块,首先要将特征图划分到一个个窗口中,假设每个窗口的宽高都是M,那么总共会得到个窗口,然后在每个窗口内使用多头注意力模块。带入公式,可以得到总的计算量为:
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 6207
6207

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









