







前言
1、现有视觉语言导航方法的梳理:
(1)增强跨模态对齐的方法:通过增强文本指令和视觉感知之间的跨模态对齐来提高代理导航性能;
(2)收集更多环境信息的方法:a)设计了一个探索模块,使智能体在面临模糊指令时能够积极探索和收集环境信息;b)允许代理通过四个自我监督的辅助任务感知更多的语义信息;c)设计了视觉编码器来提取场景和物体信息;d)将来自相邻视图的视觉信息合并到当前视图中,以更好地将视觉感知与指令相匹配;e)在数据集中添加地标和动作标签,以提供多峰对齐信息。
(3)数据增强的方法:a)合成新指令的说话者模型,生成新环境来模拟看不见的环境是提高模型泛化能力;b)随机丢弃现有环境的视觉特征来生成新环境;c)重新组装现有环境以创建新环境;d)改变当前环境的整体风格和对象的外观和类,以生成新的环境。
(4)预训练的方法:对编码器进行预训练,以提取视觉和指令的联合表示。
(5)图的方法:a)利用图来建模场景、对象和方向线索之间的关系;b)使用图表来保存关于访问视点的信息,使代理能够访问其历史感知。
(6)其他方法:a)通过循环函数维护历史跨模态信息;b)通过分层视觉变换器对过去的观察进行编码,以获得有效的历史细节;c)两个全局评分函数来计算波束搜索轨迹的可比评分。
2、目前主流的视觉语言导航方法存在的缺陷:
(1)主流方法采用模仿学习(IL)让代理人模仿老师的行为。训练后的模型会过度拟合标记的动作,并学习松散的视觉语言匹配,导致泛化能力差。
3、本工作的主要贡献:
(1)提出DISH方法,将复杂的导航任务被分解为潜在的内在子目标,并通过层次结构逐步解决;
(2)提出了一种内在的子目标驱动的注意力机制。worker可以专注于子目标相关的指令和视觉观察,以便在较小的状态空间中进行动作预测;
(3)设计了一种新的HAD,将历史信息纳入子目标判别中,并为worker提供内在奖励,以缓解奖励稀疏性。
一、强化学习基础
1.1 强化学习基础
强化学习RL专注于解决决策问题。在RL中,代理通过与环境交互来学习,以最大化累积奖励。在RL问题中,环境通常被建模为由元组(S,A,P,R,γ)定义的马尔可夫决策过程(MDP)。
(1)在每个时间步t,代理观察当前状态 ,并根据策略
选择动作
。在执行动作
后,代理从环境中获得奖励
,并根据状态转换函数
进入下一个状态
;
(2)RL的最终目标是发现一个最优策略 ∗,以最大化预期的折扣累积奖励
,其中
是时间步长计数因子;
(3)预期的折扣累积奖励可以通过动作值函数和状态值函数
来估计,它们被定义为:
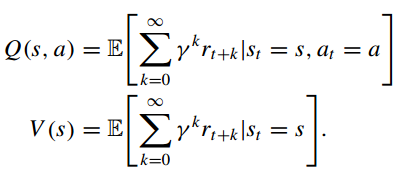
1.2 A2C算法
优势行动者批判(A2C)算法是强化学习的一个方法,结合了基于值的方法和策略梯度方法,以在具有高维动作空间的环境中实现有效和高效的学习:
(1)由确定策略 的actor和提供值函数
的critic组成;
(2)使用优势函数 来更新actor和critic;
(3)为了减少训练参数, 通常由时间差(TD)误差
估计:
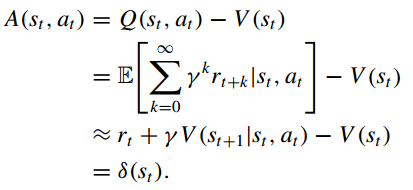
actor的梯度:
![]()
其中 表示行动者的参数,
是策略引起的状态动作分布,
是预期的累积奖励。
critic的梯度:
![]()
其中 表示critic的参数。
A2C算法迭代地更新actor和critic,直到收敛。通过学习这两个梯度函数,A2C可以有效地平衡探索和开发,从而实现更快的收敛和更好的性能。
1.3 分层强化学习
在分层强化学习HRL中,代理学习在多个抽象级别执行任务,每个级别由单独的策略表示。较高抽象级别的策略负责选择子目标,而较低级别的策略则负责实现这些子目标。总体目标是学习一个层次结构的策略,以最大限度地提高层次结构各级的累积奖励。
经典HRL方法主要有两类:基于选择和基于子目标:
(1)基于选择:低级代理学习一组技能,然后,上层代理调用这些技能来解决下游任务;
(2)基于子目标:在基于子目标的方法中,上层代理生成子目标,下层代理根据内部驱动完成子目标。
在本工作中,主要采用基于子目标的HRL,HRL和VLN具有强对齐性,原因如下:
(1)HRL采用多层次结构来学习不同层次的政策,增强其解决复杂问题的能力;
(2)在VLN任务中,代理逐步完成复杂指令的每个部分,最终完成整个导航任务。
二、模型整体框架
2.1 任务描述
在VLN任务中,代理需要按照自然语言指令执行一系列动作以到达目的地:
(1)在每个时间步 ,代理从环境中观察全景视图
和
个可导航视点
。具体来说,
由36个单一视图
组成。每个单独的视图
是一个RGB图像
。
(2)代理还可以访问每个单个视图的方向,其中
和
分别是航向角和仰角。代理需要根据自然语言指令
从可导航的航路点选择一个动作。
2.2 DISH的整体框架
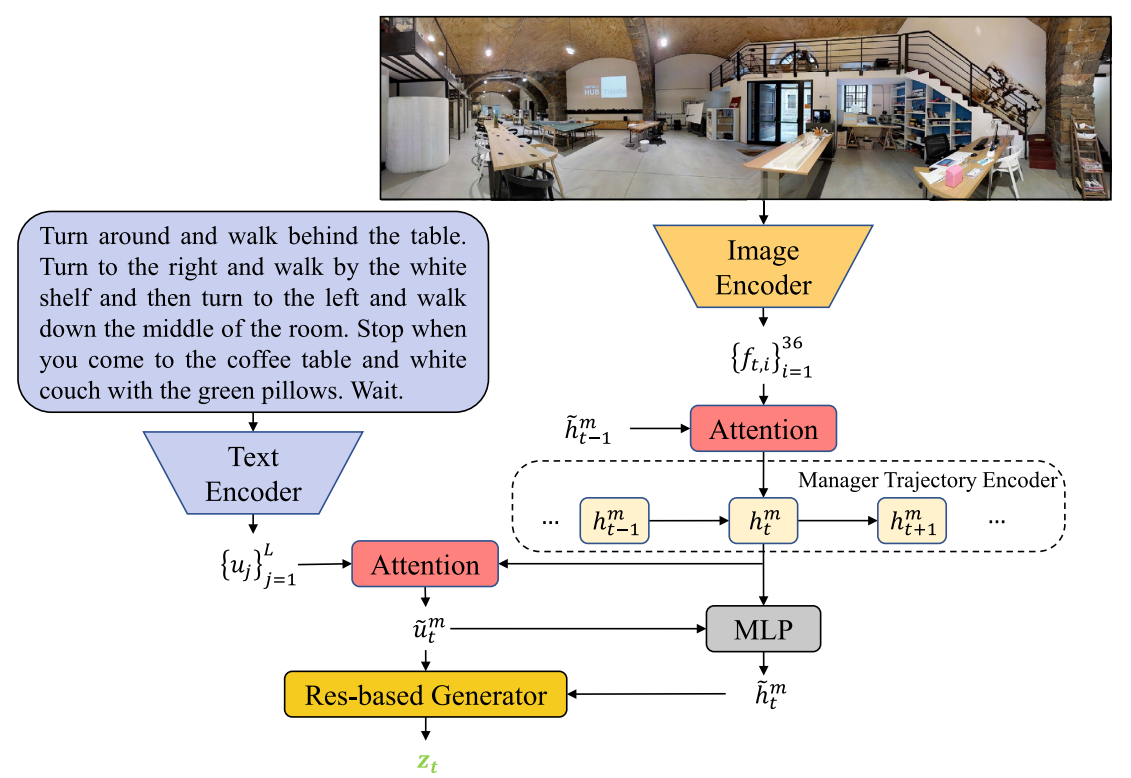
模型的整体框架如下图所示:
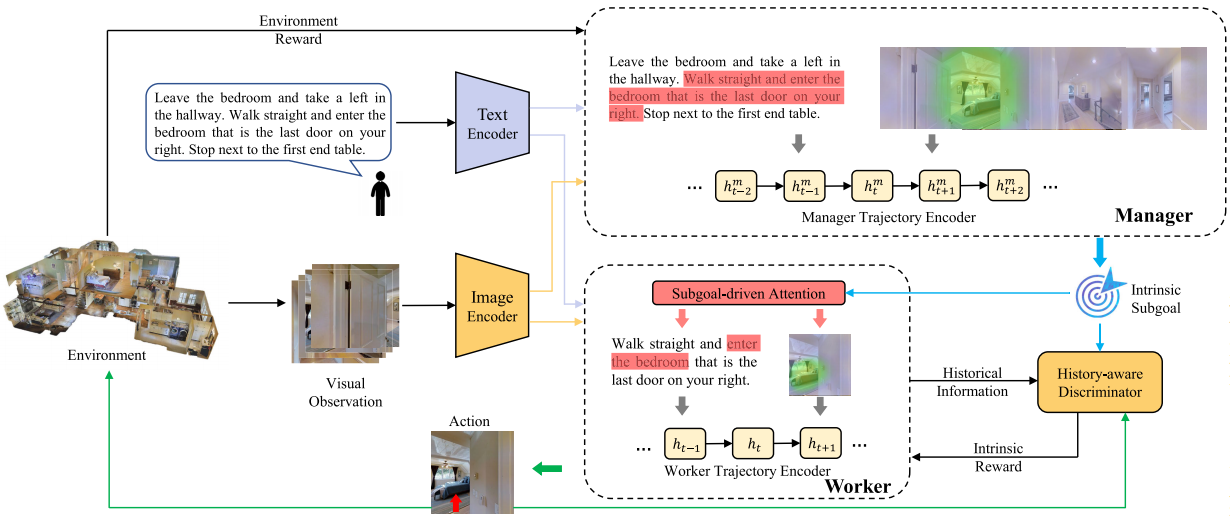
DISH由manager和worker
组成。主要工作流程如下:
(1)manager将复杂的导航任务分解为简单的内在子目标,并将其传达给worker;
(2)通过子目标驱动的注意力,worker可以在较小的状态空间内预测行动;
(3)随后,HAD分析代理的轨迹,以确定worker是否实现了子目标,并相应地提供内在奖励;
(4)通过不断完成manager提供的子目标,代理最终到达目标视点。
假设事件长度为 ,manager每
步产生一个内禀子目标
,worker预测
步完成子目标
。在形式上定义如下:
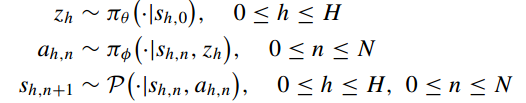
其中![]() ,
, 和
表示第
个manager时间步内的第N个状态和动作。
在整个决策过程中,将完成当前子目标 的最终状态
作为初始状态
来预测下一个子目标
。此设置允许代理为预测下一个子目标提供良好的初始状态,保持子目标的连续性。
三、难点
3.1 学习策略
3.1.1 manager学习策略
每当manager产生一个子目标 时,它都会通过将接下来
个步骤的环境奖励相加来获得奖励
。manager的目标是使预期的折扣累积奖励最大化。
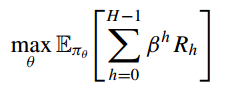
其中 ,
![]() 。具体的环境奖励规则如下:
。具体的环境奖励规则如下:
(1)当代理执行“停止”动作时,如果代理在距离目的地3米以内,则获得+2奖励,否则将获得-2惩罚;
(2)在每一个不间断的时间步,代理都会根据其到目的地的距离的变化获得奖励。如果代理更接近目的地,它将获得+1奖励,否则将获得-1惩罚。
3.1.2 worker学习策略
基于managerMDP,定义一个新的元MDP:
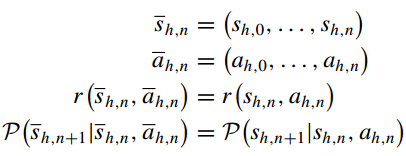
worker元MDP策略:
(1)worker的动作和状态包含从worker收到新的子目标 开始的历史信息。将状态-动作对
表示为子轨迹;
(2)在每个时间步,worker将子轨迹和子目标作为输入,来预测下一个动作;
(3)将子目标转换为这个新MDP上的子轨迹,希望根据生成的子轨迹推断出相应的子目标;
(4)将推断的子目标与原始子目标进行比较,可以向员工提供内在奖励(HAD的功能);
(5)worker的目标是给定子轨迹 的情况下最小化子目标
的熵。
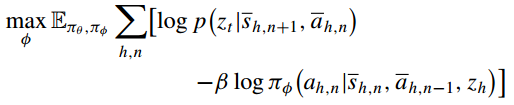
其中![]() ,
, 是权重因子。目标中的第一项确保我们可以在给定子轨迹的情况下识别相应的子目标。目标中的第二项使工人策略的熵最大化。这种最大化允许worker策略预测给定子目标的不同操作。每个子目标将覆盖更大的子轨迹空间,从而实现更好的泛化。
由于直接估计后验 很难,我们使用参数化后验
来近似它并得到一个下界。这种参数化允许我们通过最大化新目标来学习worker策略:
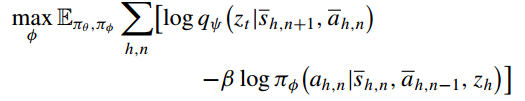
其中 是一个用于近似后验的鉴别器。给定采样子轨迹,通过最大化相应子目标的似然性来优化
。
鉴于VLN任务的复杂性,从头开始同时学习子目标生成和子目标完成是不稳定的。因此,添加环境奖励作为内在奖励的第三项,即 用内在奖励
来更新。
3.1.3 联合学习策略
manager和worker通过A2C算法进行联合训练。由于manager和worker之间的交互,选择了基于策略的RL算法。当worker被更新时,子目标将被转换为新的动作序列,manager将获得不同的奖励。
3.2 子目标生成器——manager
如下图所示:
子目标生成器工作步骤:
(1)经过双向LSTM文本编码器,得到文本特征;
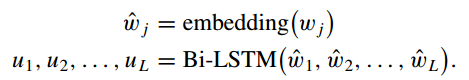
(2)经过预训练的ResNet-152提取每个视图 的图像特征
,结合方向特征
,得到视觉特征
。manager和worker共享文本和视觉特征;
(3)在每个时间步,manager为每个视觉特征 分配注意力权重,并计算视觉特征的加权和,得到注意力视觉特征
;
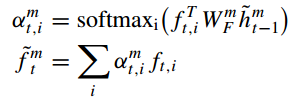
(4)manager轨迹编码器LSTM对生成的注意力视觉特征 和先前的隐藏状态
编码,得到当前轨迹隐藏状态
;
![]()
(3)manager为每个文本特征 分配注意力权重,计算文本特征的加权和,得到注意力文本特征
;
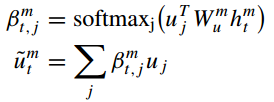
(6)将注意力文本特征和先前轨迹隐藏状态
组合后通过一个线性层,得到当前文本感知隐藏状态
;
![]()
(7)最后,将注意力文本特征和当前文本感知隐藏状态
输入到基于残差的生成器中,以生成子目标
:
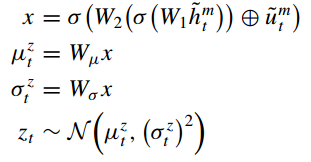
其中,生成子目标的具体流程如下:
a)将注意力文本特征 作为原始输入,并将文本感知隐藏状态
作为残差映射的补充来计算子目标信息
;b)用
分别推导出子目标的均值
和方差
;c)最后从正态分布
中采样
。
3.3 动作预测器——worker
如下图所示:
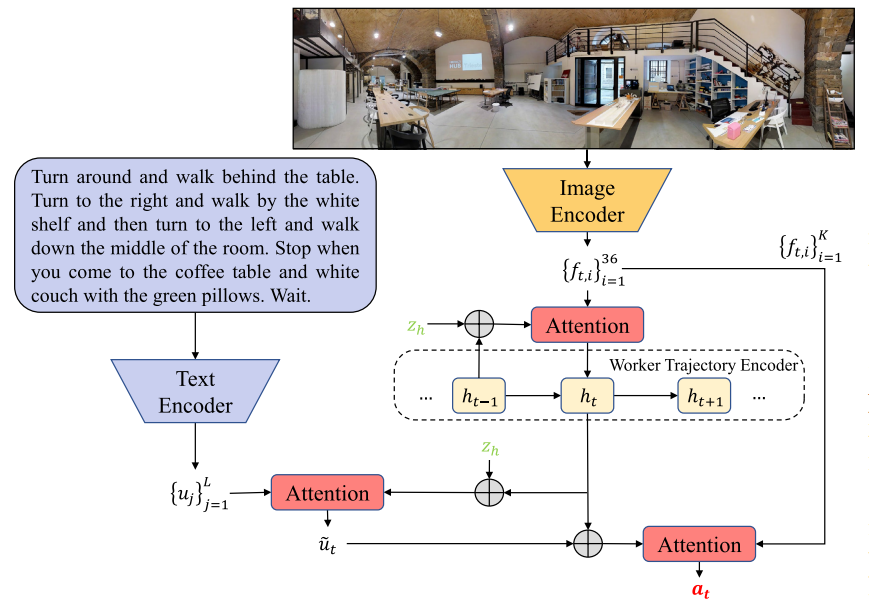
给定子目标,worker可以专注于与子目标相关的指令和视觉观察,以便在较小的状态空间中进行动作预测。我们为worker引入了一种内在的子目标驱动的注意力机制。
动作预测器工作步骤:
(1)在每个时间步 ,将前一隐藏状态
以及子目标
连接起来,计算
的注意力权重,然后得到加权的子目标相关视觉特征
;
![]()
![]()
(2)worker轨迹编码器LSTM对字母比奥相关视觉特征 和前一隐藏状态
的连接进行编码,获得当前的隐藏状态
;
![]()
(3)将当前隐藏状态 和子目标
连接起来,计算文本特征
的注意力权重,通过加权和得到子目标相关文本特征
;
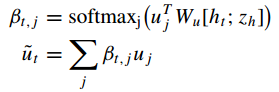
(4)将子目标相关文本特征 和当前隐藏状态
连接起来,计算其与每个可导航视点特征
的相似性,将所有可导航视点的相似性经过softmax,估计移动到第k个视点的概率:
![]()
3.4 鉴别器
如下图所示:
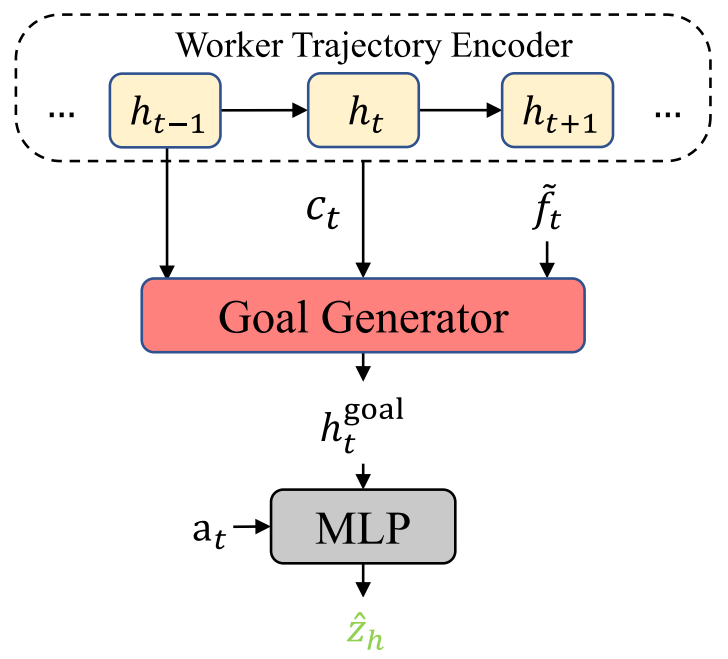
根据worker目标,鉴别器将子轨迹作为输入,预测相应的子目标,并为worker提供奖励。
(1)子轨迹可以分解为先前的子轨迹 和
、新预测的动作
和新的子目标相关视觉特征
;
(2)具体方法是首先使用目标生成器用 、
和
计算子目标隐藏状态
,然后将隐藏状态
与预测的动作
连接起来估计子目标:
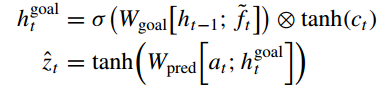
假设鉴别器的输出分布是零均值多元高斯分布,然后最大化后验概率等价于最大化具有L2正则化的负均方误差损失函数,即worker目标中的后验概率可以计算为。
四、总结
(1)强化学习中的奖励跟深度学习的损失函数有什么联系和区别?
(2)马尔可夫决策过程(MDP)能不能运用到teacher算法中?


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









