







背景
随着深度学习技术的发展,深度学习技术也逐渐从学术研究的方向转向了实践应用的方向,这不仅对深度模型的准确率有了较高的需求,也对深度模型的推理速度有了越来越高的需求。
目前深度模型的推理引擎按照实现方式大体分为两类:
解释型推理引擎:一般包含一个模型解析器和一个模型解释器,一些推理引擎可能还包含一个模型优化器。模型解析器负责读取和解析模型文件,并将其转换为适用于解释器处理的内存格式;模型优化器负责将原始模型变换为等价的、但具有更快的推理速度的模型;模型解释器分析内存格式的模型并接受模型的输入数据,然后根据模型的结构依次执行相应的模型内部的算子,最后产生模型的输出。
编译型推理引擎:一般包含一个模型解析器和一个模型编译器。模型解析器的作用与解释型推理引擎相同;模型编译器负责将模型编译为计算设备(CPU、GPU 等)可直接处理的机器码,并且可能在编译的过程中应用各种优化方法来提高生成的机器码的效率。由于机器码的模型可以直接被计算设备处理而无需额外的解释器的参与,其消除了解释器调度的开销。此外,相对于解释型推理引擎,由于生成机器码的过程更加靠底层,编译器有更多的优化机会以达到更高的执行效率。
由于现在业界对于推理引擎的执行速度有了更高的需求,编译型推理引擎也逐渐成为高速推理引擎的发展方向。目编译型推理引擎有 Apache TVM、oneDNN、PlaidML、TensorFlow XLA、TensorFlow Runtime 等。
为了便于优化,一般来说推理引擎会把模型转换为中间表示,然后对中间表示进行优化和变换,最终生成目标模型(对于解释型推理引擎)或目标机器码(对于编译型推理引擎)。此外,除了深度学习领域,在很早以前编程语言领域就引入了中间表示来做优化和变换。而新的编程语言层出不穷,因此就出现了各种各样的中间表示:
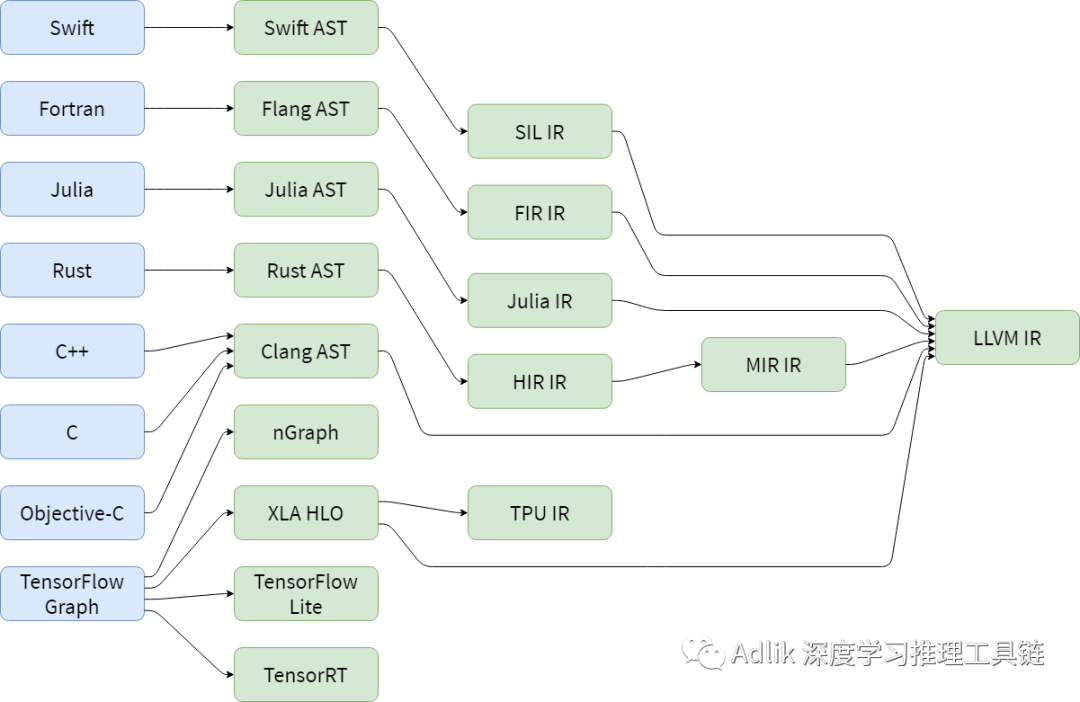
不同的推理引擎或者编译器都会有自己的中间表示和优化方案,而每种中间表示和优化方案可能都需要从头实现,最终可能会导致软件的碎片化和重复的开发工作。
MLIR 简介
MLIR(Multi-Level Intermediate Representation)是一种新型的用于构建可复用和可扩展的编译器的框架。MLIR 旨在解决软件碎片化、改善异构硬件的编译、降低构建领域特定编译器的成本,以及帮助将现有的编译器连接到一起。
MLIR 旨在成为一种在统一的基础架构中支持多种不同需求的混合中间表示,例如:
表示数据流图(例如在 TensorFlow 中)的能力,包括动态性状、用户可扩展的算子生态系统、TensorFlow 变量等。
在这些图中进行优化和变换(例如在 Grappler 中)。
适合优化的形式的机器学习算子内核的表示。
能够承载跨内核的高性能计算风格的循环优化(融合、循环交换、分块等),并能够变换数据的内存布局。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1704
1704











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











