




 本文探讨了MLIR中的代码生成流程,特别是针对深度学习框架如TensorFlow的编译过程。文章分析了几种常见的编译管线,如TensorFlowKernelGenerator、IREECompiler以及PolyhedralCompiler,并讨论了LinalgDialect在编译管线中的核心地位。
本文探讨了MLIR中的代码生成流程,特别是针对深度学习框架如TensorFlow的编译过程。文章分析了几种常见的编译管线,如TensorFlowKernelGenerator、IREECompiler以及PolyhedralCompiler,并讨论了LinalgDialect在编译管线中的核心地位。
文章目录
前言
最近学习了 MLIR 的 Toy Tutorial,并且整理了两篇相关博客。
在我的第二篇博客较为详细地介绍了 Toy语言 接入 MLIR,经过多次 pass,最后 lower 成 LLVM IR的流程。但 Toy 接入 MLIR 流程本质上还是高级语言的转换流程,对于深度学习框架接入 MLIR 后的 CodeGen 描述较少。
本文主要以 tensorflow 为例,介绍了其接入 MLIR 后的 CodeGen 过程,以及简要分析了一些现在常用的 CodeGen pipeline。本文是本人在结合博客(Codegen Dialect Overview - MLIR - LLVM Discussion Forums)以及相关资料而写成,主体内容来源于翻译。
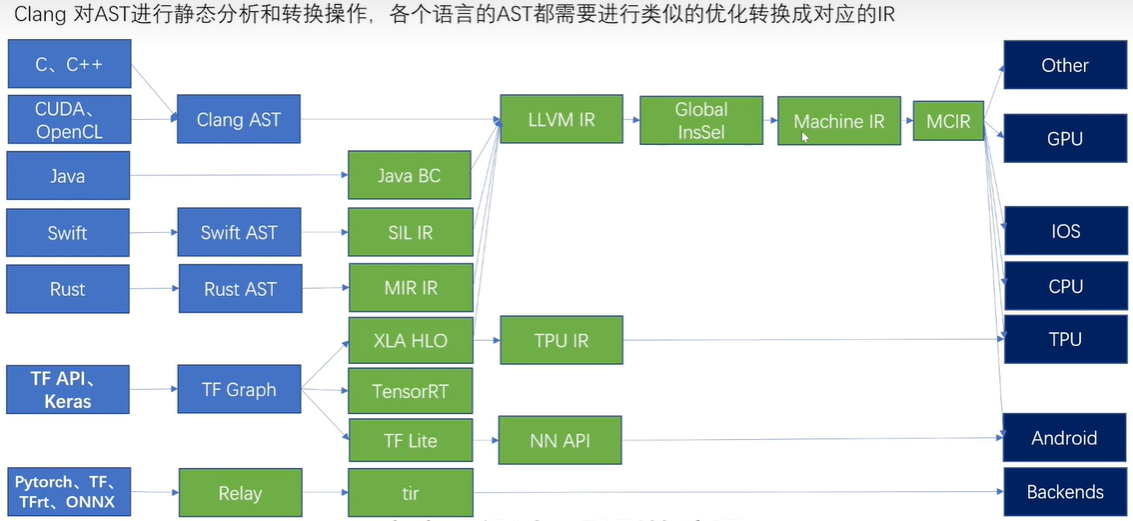
现状
Classification
MLIR 中与代码生成相关的 dialects 大致可以沿着两个轴进行分解:tensor/buffer 和 payload/structure。
dialect 在 tensor/buffer 轴上的分解可以体现出它主要的数据抽象形式,要么是 ML 框架中的 tensor,要么是传统低级编译器预期的 memory buffer。tensors 被视为不一定与内存相关联的不可变值 (immutable values),也就是说,对 tensor 的操作通常不会产生副作用 (side effect)。此类操作之间的数据流可以使用基于 SSA(static single assignment) 格式的用户自定义链(use-definition chains )进行表达。这使得张量操作的重写变得更加简易可行,也是为什么 MLIR 能称为 ML 程序的强大转换工具。另一方面,buffer 是可变的,可能会受到混叠的影响(多个对象可能指向同样的底层存储位置)。这种情况下,数据流只能依据额外的依赖关系和别名分析(aliasing analyses)来提取。tensor 抽象和 buffer 抽象之间的转换由 bufferization 过程来实现,该过程会逐步将两类抽象关联起来,并最终完成替换。一些 dialects(如Linalg和Standard)既有对 tensor 的操作,也有对 buffer 的操作,甚至 Linalg Dialect 中的一些操作可以同时对 tensor 和 buffer 进行处理。
dialect 在 payload/structure 轴上的分解可以体现出,它是描述应该执行怎样的操作(payload),还是描述应该如何执行(structure)。举例来说,在 Standard Dialect 中许多数学操作指定了要执行的计算(e.g., the arctangent, without further detail)。而 SCF Dialct 中定义了如何执行包含的计算(e.g., repeated until some runtime condition is met)。类似的,Async Dialect 表示适用于不同负载粒度(payload granularity)级别的通用执行模型。
dialect 在上述轴上的分解并不是二进制表示的,尤其对于那些更高的抽象级别。许多操作会多多少少都指定了结构(structure)。例如, vector dialect 的操作意味着 SIMD 执行模型。在编译过程中,“如何执行”的描述会越来越详细并且用用低级表述。同时,抽象堆栈的较低层级倾向于将structure操作和payload操作分开,以便在仅仅转换structure操作的同时,又保留对payload操作的抽象理解。
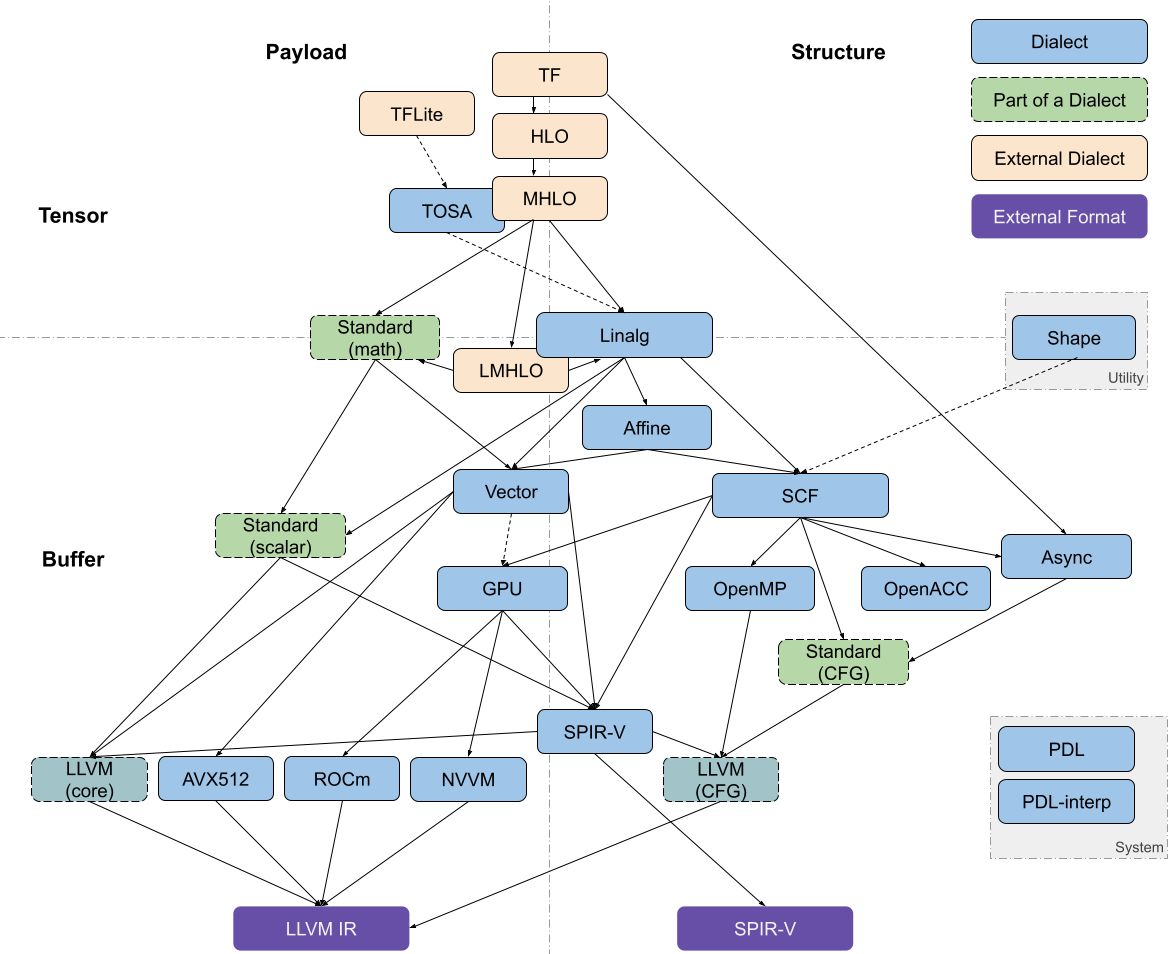
Dialects of Interest
MLIR 代码生成管道(code generation pipeline)需要经过一系列中间步骤,这个步骤的特点就是使用最近引入的 dialect,例如从高级别的 tensor 表示,到低级别(贴近硬件层面)的 buffer 表示。
dialects 可以根据其 feature 的抽象级别 粗略地组织到一个堆栈中。将较高级别的抽象表示 lower 到较低级别的抽象表示通常较为简单,但反过来就不是这样了。
在编译器一系列转换程序的过程中,越来越多的高层次的简明信息被打散,转换为低层次的细碎指令,这个过程被称为代码表示递降
lowerinng,与之相反的过程被称为代码表示递升raising。raising远比lowering困难,因为需要在庞杂的细节中找出宏观脉络。

大多数 pipeline 通过 Linalg Dialect 进入 in
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1176
1176

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









