






LSQ 是一种有效的低比特量化算法
对于深度神经网络,模型的权重一般都用浮点数表示,如 32-bit 浮点数(float32)。推理的时候,如果也采用这种数值类型,会消耗较大的内存空间和计算资源。在不影响模型准确率的情况下,模型采用其他简单数值类型,能显著缩小对计算资源的需求和推理时延,这对于资源受限设备来说尤其重要。
从量化的比特数来区分,常用的量化技术有 8-bit 量化( INT8 量化)、4-bit 量化( INT4 量化)、二值化、三值化量化等,这些都可以统称为低比特量化。INT8 量化已比较成熟,目前推理引擎、硬件普遍支持 INT8 量化,且已有很多研究证明了对模型的激励和权重进行 8-bit 量化,能做到基本没有太大的精度损失。虽然 INT4 量化技术尚不成熟,目前只有少数的硬件支持,如 NVIDIA T4,A100,H100,并且目前还没有推理引擎能支持 INT4 量化,但是 INT4 量化是未来模型优化的发展方向,特别是在大模型的压缩上——随着模型的增大,内存和计算资源都变得越来越珍贵,它们是模型是否能应用在移动设备和边缘设备上的重要瓶颈。INT4 量化正好能更好的解决上述问题。
和 INT8 量化相比,INT4 量化有着无以伦比的优势。INT4 量化除了能把模型对内存和带宽的需求进一步减小一半,还能带来显著的推理加速。如 NVIDIA 对 ResNet-50v1.5 进行了 INT4 量化,能在精度最多下降1%的情况下,在NVIDIA T4上实现59%的推理加速[1],具体的推理速度见下图。
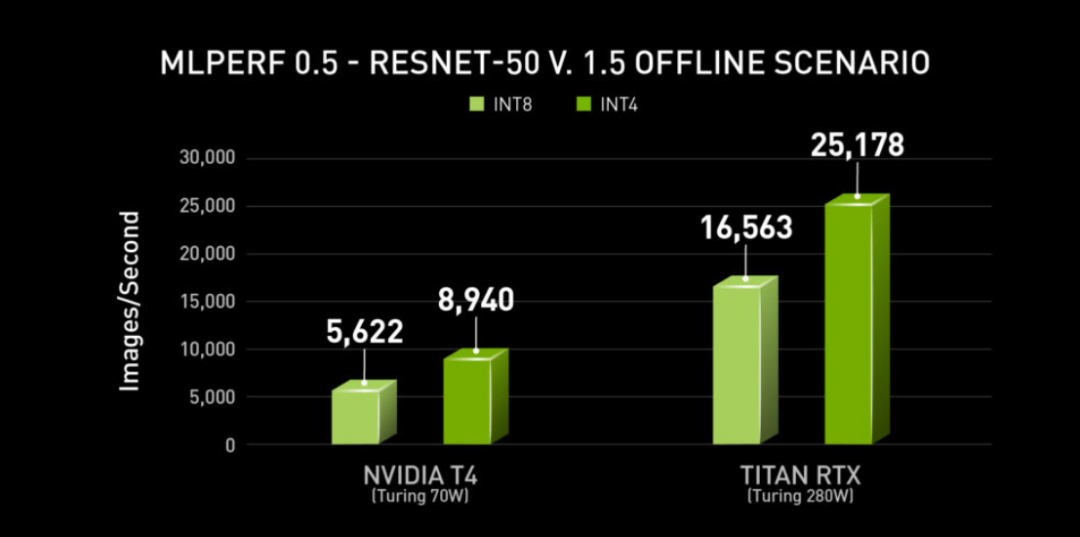
虽然目前支持 INT4 的硬件设备屈指可数,如 NVIDIA T4、NVIDIA A100、寒武纪的思元 370 加速卡、Xilinx 的 Zynq-7000 SoC 等,并且没有成熟的推理引擎支持 INT4 量化,但是 INT4 量化带来的模型压缩和推理加速能力一直吸引着学术界,许多研究者对其进行了探索:如 HAWQ-V3[2] 使用 QAT 进行全整型 INT4 量化,ResNet50 的精度和未量化的模型相比,下降了 3.4%。BRECQ[3] 采用了一种 PTQ 的量化方法,它从二阶误差着眼,利用神经网络中基本的 block 结构,进行逐 block 的 AdaRound 重构,通过该算法,ResNet50 在 INT4 下,精度下降了 2.2%。IBM 提出的 LSQ [4]是一种改进的 QAT 算法,除了对网络中算子的权重进行训练,对量化参数 step size 也进行训练。通过 LSQ,ResNet50 在 INT4 下,精度仅下降了0.2%。几种算法对比,我们发现 LSQ 算法对低精度量化(8-bit以下)有较好的效果。
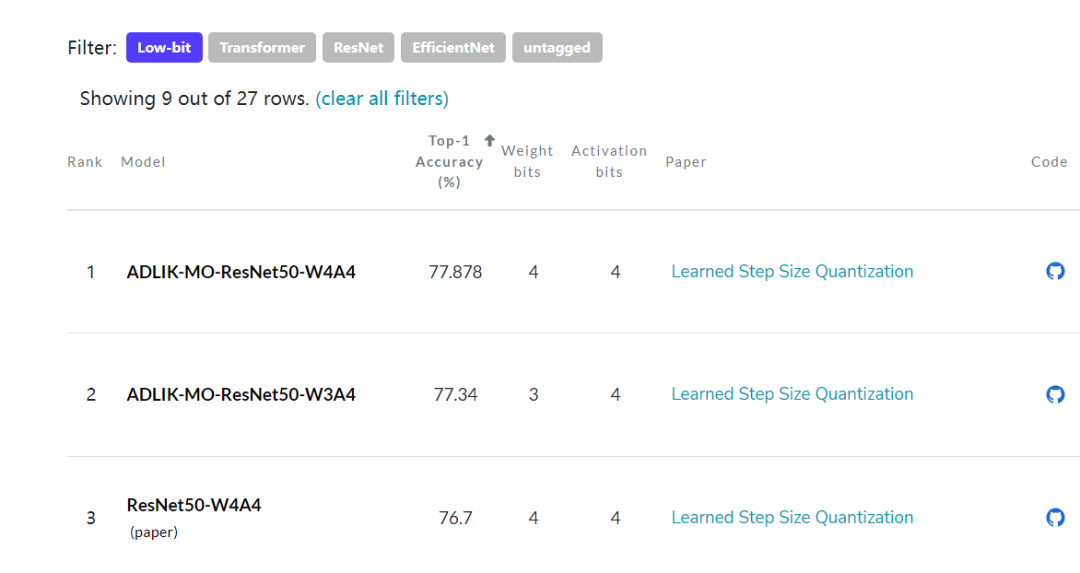
我们在 Adlik 的 model_optimizer 中实现了 LSQ 算法,配合蒸馏技术,对 ResNet50 进行 INT4 量化,最终精度可以达到 77.878% ,比 32-bit 的原始模型(精度 76.13%)还高了 1.778%。通过 Adlik 优化的 ResNet50-W4A4 比 paperswithcode quantization SOTA 榜单中的 ResNet50-W4A4 模型精度高 1.178%,取得了低比特量化排名第一的好成绩[5]。
LSQ 算法原理
假设需要量化的数据是 ,量化器的 step size 为 ,量化的正负级别分别用 和 表示。量化器量化的结果是 , 是 的已量化表示 。LSQ 的量化器按照公式(1),公式(2)进行量化:
公式中, 表示输入数据为 的情况下, 如果 在 和 之间,返回 ;如果 小于 ,返回 ;如果 大于 ,返回 。 表示对 进行四舍五入到最近的整数。如果用 比特进行编码,对无符号数,有;对有符号数,有 。
对于 min-max 对称量化,量化参数 是在每次 weight 更新后,计算得到的:
LSQ 算法改变了这一做法,把量化器的参数 纳入可训练的参数,通过梯度下降的方式对其进行更新,即 量化参数 是通过训练得到,而非通过简单的计算获得。在每次反向传播的时候,对 求导进行参数更新,计算过程如下:
由公式(1),(2),可以得到:
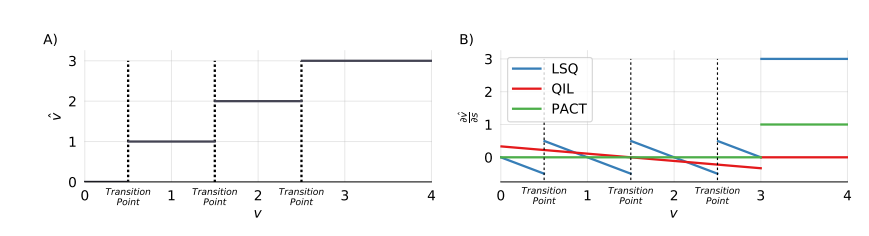
对 求导得到: 其中, 这里,是 STE 得到,把公式(6)代入到公式(5),可以得到论文中的公式: 公式(7)绘制成图 B),说明 LSQ 在量化状态的过度点(transition point)的位置,梯度会发生很大的变化,可见LSQ算法对 和每个过渡点之间的距离是敏感的,见下图 B)中蓝色的线,同时也可以看出相比于 QIL 和 PACT,LSQ 在计算梯度方面更加合理。这也符合下图 A):假设把量化范围固定在 [0, 3] 区间,(即 )。图 A) 表示量化前的 和反量化后的 之间的映射关系,这里采用四舍五入的原则,从图中可以看出,在 0.5 这个地方 (图中第一道虚线), 会从 0 突变到 1 ,这会带来巨大的量化误差,这从另一方面也体现在图 B)在 transition point 处梯度的变化上。
LSQ 除了把作为可训练参数,在计算的梯度的时候,还需要注意其参数更新的幅度和权重参数更新的幅度是成比例的,这有助于训练更好的收敛。这个 ratio 定义如下:
近似为1, 其中 表示 的 范数。这可以通过对 的梯度进行调整,乘以一个缩放因子 gradient scale 实现。下面对算法的初始化和 的梯度调整进行说明:每一层的权重和激活有其各自的 ,用 float32 表示, 初始化为 ,权重用其初始值进行计算,激活用第一个 batch 的数据进行计算。为了在训练过程中更好的收敛,需要对 的梯度进行调整,乘以一个gradient scale,记做 。对权重, , 表示一层中权重的个数。对激活, , 表示一层激活中特征的个数。
Adlik LSQ 的低比特量化实践
Adlik 中通过继承 torch.quantization.FakeQuantizeBase,实现了 LearnableFakeQuantize 类,通过 torch fx QAT 插入 FakeQuantize 的方式,来完成 LSQ 算法。通过探索, ResNet50 模型在 INT4 量化时,采用 LSQ 算法,并结合蒸馏,能取得非常好的效果。大致过程分为 2 步:
使用Timm库提供的预训练 ResNet50d 模型作为老师模型对 ResNet50 模型蒸馏 蒸馏后的 ResNet50 模型的精度可达到 80.754%,相比原始 ResNet50 模型,精度提高4%。
对蒸馏后的 ResNet50 模型(精度 80.754%)进行 W4A4 LSQ 量化,量化只对卷积和全连接层进行,除了第一层和最后一层是 INT8 量化,其余都是INT4 量化。在 LSQ 量化训练的同时,使用 ResNet50d 模型作为老师模型进行蒸馏,进一步提升量化精度。量化后模型精度为 77.878% 。该精度,比 32-bit 的全精度模型(76.13%)高了1.778%,比 paperswithcode 的quantization SOTA 榜单中的 ResNet50-W4A4 模型高了 1.178%,在该榜单中取得了排名第一的好成绩。为了验证低比特模型真正的推理精度,我们配合使用了自研的量化模拟器,进一步验证了低比特模型推理的准确性。此外,我们还对 ResNet50 进行了 W3A4 混合精度量化,也取得了非常好的效果。实验结果见下表:
| Model | Accuracy(%) |
|---|---|
| ResNet-50 W4A4[4] | 76.7 |
| Adlik-ResNet-50 W4A4 | 77.878 |
| Adlik-ResNet-50 W3A4 | 77.34 |
好了,有关LSQ的低比特量化就到这里了。期待大家继续支持和关注Adlik的Github仓库。

参考文献:
[1]https://developer.nvidia.com/blog/int4-for-ai-inference/ [2]Zhewei Yao, Zhen Dong et al., HAWQV3: Dyadic Neural Network Quantization. arXiv:2011.10680 [cs.CV], 2020.11 [3]Yuhang Li, Ruihao Gong et al., BRECQ: Pushing the Limit of Post-Training Quantization by Block Reconstruction. arXiv:2102.05426 [cs.LG], 2021.02 [4]Steven K. Esser, Jeffrey L. McKinstry et al., Learned Step Size Quantization. arXiv:1902.08153 [cs.LG], 2019.02 [5]https://paperswithcode.com/sota/quantization-on-imagenet?tag_filter=447 [6]https://zhuanlan.zhihu.com/p/396001177















 3090
3090











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









