







 本文介绍了IBM的LSQ(Learned Step Size Quantization)和高通的LSQ+,它们是深度学习量化训练中的方法,通过将量化参数step size和zero point纳入训练过程,实现更精确的量化。LSQ利用可微量化参数进行训练,而LSQ+进一步将zero point作为训练参数,适用于非对称量化。实验表明,这些方法在低比特量化下仍能保持较好精度。
本文介绍了IBM的LSQ(Learned Step Size Quantization)和高通的LSQ+,它们是深度学习量化训练中的方法,通过将量化参数step size和zero point纳入训练过程,实现更精确的量化。LSQ利用可微量化参数进行训练,而LSQ+进一步将zero point作为训练参数,适用于非对称量化。实验表明,这些方法在低比特量化下仍能保持较好精度。
(本文首发于公众号,没事来逛逛)
有读者让我讲一下 LSQ (Learned Step Size Quantization) 这篇论文,刚好我自己在实践中有用到,是一个挺实用的算法,因此这篇文章简单介绍一下。阅读这篇文章需要了解量化训练的基本过程,可以参考我之前的系列教程。
LSQ 是 IBM 在 2020 年发表的一篇文章,从题目意思也可以看出,文章是把量化参数 step size (也叫 scale) 也当作参数进行训练。这种把量化参数也进行求导训练的技巧也叫作可微量化参数。在这之后,高通也发表了增强版的 LSQ+,把另一个量化参数 zero point 也进行训练,从而把 LSQ 推广到非对称量化中。
这篇文章就把 LSQ 和 LSQ+ 放在一起介绍了。由于两篇文章的公式符号不统一,为了防止符号错乱,统一使用 LSQ 论文中的符号进行表述。
普通量化训练
在量化训练中需要加入伪量化节点 (Fake Quantize),这些节点做的事情就是把输入的 float 数据量化一遍后,再反量化回 float,以此来模拟量化误差,同时在反向传播的时候,发挥 STE 的功能,把导数回传到前面的层。
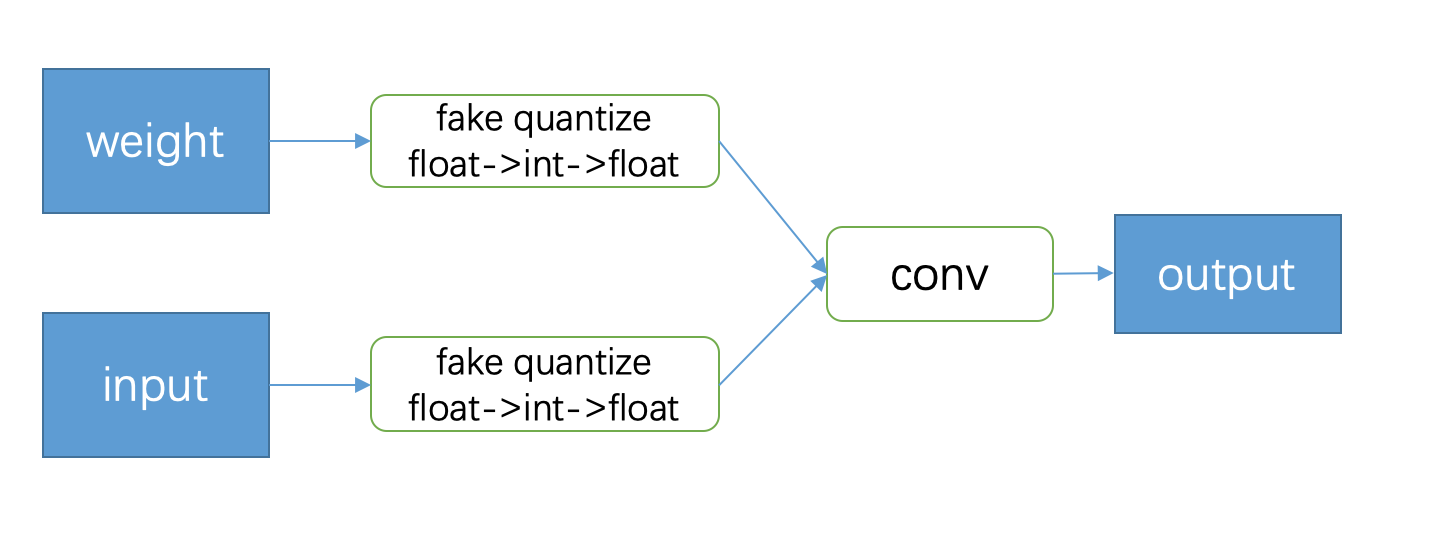
Fake Quantize 的过程可以总结成以下公式 (为了方便讲解 LSQ,这里采用 LSQ 中的对称量化的方式):
v ‾ = r o u n d ( c l i p ( v / s , − Q N , Q P ) ) v ^ = v ‾ × s (1) \begin{aligned} \overline v&=round(clip(v/s, -Q_N,Q_P)) \\ \hat v&=\overline v \times s \tag{1} \end{aligned} vv^=round(clip(v/s,−QN,QP))=v×s(1)
其中, v v v 是 float 的输入, v ‾ \overline v v 是量化后的数据 (仍然使用 float 来存储,但数值由于做了 round 操作,因此是整数), v ^ \hat v v^ 是反量化的结果。 − Q N -Q_N −QN 和 Q P Q_P QP 分别是量化数值的最小值和最大值 (在对称量化中, Q N Q_N QN、 Q P Q_P QP 通常是相等的), s s s 是量化参数。
由于 round 操作会带来误差,因此 v ^ \hat v v^ 和 v v v 之间存在量化误差,这些误差反应到 loss 上会产生梯度,这样就可以反向传播进行学习。每次更新 weight 后,我们会得到新的 float 的数值范围,然后重新估计量化参数 s s s:
s = ∣ v ∣ m a x Q P (3) s=\frac{|v|_{max}}{Q_P} \tag{3} s=QP∣v∣max(3)
之后,开始新一次迭代训练。
LSQ
可以看到,上面这个过程的量化参数都是根据每一轮的权重计算出来的,而整个网络在训练的过程中只会更新权重的数值。
LSQ 想做的,就是把这里的 s s s 也放到网络的训练当中,而不是通过权重来计算。
也就是说,每次反向传播的时候,需要对 s s s 求导进行更新。
这个导数可以这样计算:把 (1) 式统一一下得到:
v ^ = r o u n d ( c l i p ( v / s , − Q N , Q P ) ) × s = { − Q N × s v / s < = − Q N r o
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2029
2029

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









