






★1.java常见的引用类型
强:普通的变量引用
软:内存够时,GC不会主动删除,内存不够时,GC会删除
弱:一旦执行GC就会被删除
虚:用了感觉没用
★2.JDK1.8新特性
- lambda表达式(极大简化了匿名内部类的创建,促进函数式编程的风格)
- 函数式接口(只能有一个抽象方法的接口 )
- 日期时间的新API(LocalDate,LocalTime,LocalDateTime等)
- StreamAPI(提供了一种声明式、高效且易于并行化的集合数据处理方式 )
- Optional类(处理Null值,防止空指针异常)
- 方法引用(更为简洁的lambda表达式,可以直接引用现有方法和构造函数 )
- 接口的默认方法和静态方法(可以包含默认方法,允许在接口中提供方法的具体实现,而无需强制实现类去覆盖它 ; 可以包含静态方法,增强接口的功能性)
★3.JAVA异常
1.运行时异常(Running Exception)在程序中可以不进行显示处理的异常(ArithmeticException[运算异常] ClassCastException[类型转换异常] IndexOutOfBoundsException[下标越界异常] NullPointerException[空指针异常] IllegalArgumentException[非法参数异常] )
2.检查时异常(Checked Exception)必须显示处理,不然程序不允许代码编译运行.(FileNotFoundException [文件未找到异常] MalformedURLException[错误的URL异常] IOException [I/O异常] SQLException [Sql异常])
3.错误(Error) 系统级别的错误,程序无法处理,会立刻停止运行(OutOfMemoryError[堆空间溢出] StackOverflowError[栈空间溢出],断言错误,JVM内部错误)
★4.双亲委派
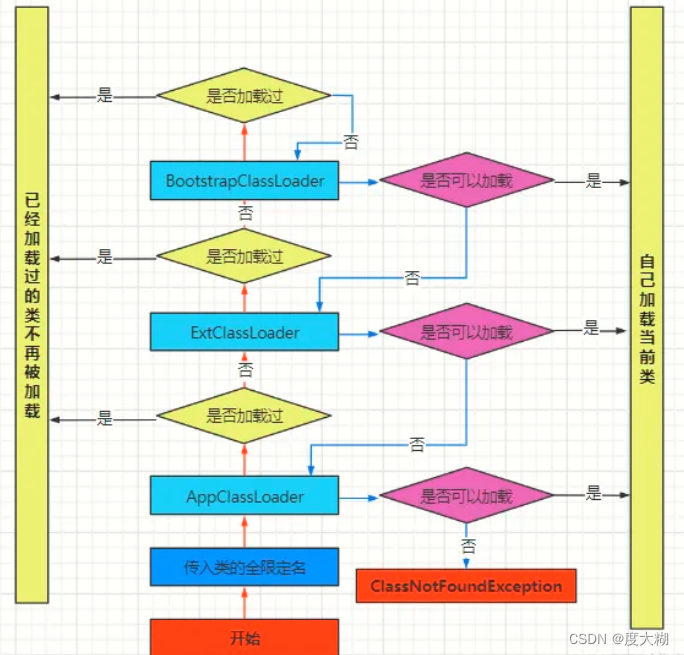
1.启动类加载器(Bootstrap ClassLoader):即根类加载器,负责加载Java虚拟机核心类库,如java.lang.Object等。
2.扩展类加载器(Ext ClassLoader):加载Java扩展类库,如javax或java.util等。
3.应用程序类加载器(Application Class Loader):即系统类加载器,负责搜索应用程序的类路径并加载。
4.自定义类加载器:开发人员可以根据需要实现的类加载器。
为什么需要双亲委派?
避免类的重复加载 ; 保证安全性(例如java.lang.String,这个类只会加载根类加载器的,避免被覆写)
★5.深拷贝和浅拷贝?
浅拷贝:对象属性(包含String),复制地址指针;非对象属性复制值。
深拷贝:对象属性直接new一个新的对象。(复制的对象是完全独立的)
★6.设计模式——单例模式?
饿汉式:始终用这一个对象,提前实例化一个对象,不论是否用(会占用空间)
懒汉式:通过DCL(双重检验),只有在需要时才会实例化一个对象,最好加上volatile。(DCL:两次判定,第一次非空判定是否加锁(Synchronization),第二次非空判定是否创建对象,防止其他线程多次创建对象)。
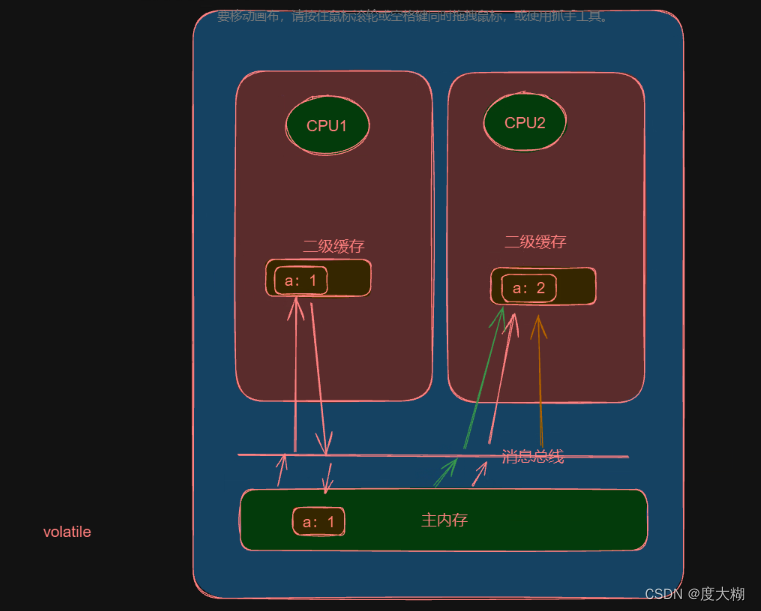
★7.详细解释一下Volatile?
保证多线程可见性,确保其他线程操作的数据永远是最新的(极端情况下:当数据已经放入寄存器中,那么其操作的数据就是错误的),极端情况下无法保证原子性。
禁止指令重排,避免在对象未实例化数据便将地址传给其他线程。
★8.有没有用过存储过程?
了解存储过程,他是数据库预编译的SQL代码段,能够进行复杂的运算或数据库操作,进行返回值甚至返回结果集。但我们实际是禁止使用的,因为让数据库进行运算之类的会大大增加的压力,我们让Redis做缓存从,使用K8S,Nginx等都是为了减轻数据库压力,所以是禁止使用存储过程的,这和我们开发的目的相悖的。
★9.Comparable和Comparator区别?
- 类包不同:java.lang.Comparable java.util.Comparator
- 比较逻辑不同: Comparable是内部比较器 Comparator是外部比较器
- 排序规则数量不同:Comparable唯一字段排序 Comparator可以多个字段排序
- 排序方法不同: Comparable实现ComparaTo(T t) Comparator实现Compara(T t1,T t2)
- Collections.sort()中使用不同:一个参数默认是Comparable排序; 如果要用Comparator,则还需传一个Comparator外部排序
★10.JWT身份认证?
JWT的优势有哪些?
无状态:JWT本身包含身份验证的所有信息,所以我们服务器不需要储存Session。减轻服务器压力,增加可拓展性
避免CSRF攻击(跨站请求伪造):CSRF攻击需要依赖Cookie,但JWT身份验证不需要Cookie,所以避免了CSRF攻击。(我们也通过创建一个XSS过滤器,来过滤请求中存在XSS攻击风险的可疑字符串)
适合移动端:使用Session验证需要将Cookie存在服务端,而JWT则是存储在客户端就可以使用,而且还能够跨语言
单点登录友好:JWT会保存在客户端,适合用于单点登录,也不会出现Cookie常见的跨域问题
为什么使用双Token?如何实现?
为了提高系统的安全性和稳定性,双Token的实现避免了JWT的不可控问题(即注销等情况下JWT依然可用)和JWT的续签问题。
用户登录时前端传账户和密码 ——→ 后端验证并生成 访问令牌Access Token(短Token)和 刷新令牌Refresh Token(长Token) 并储存在客户端pinia中 ——→在访问受保护的资源时会在header中携带Access Token并进行验证,在短Token过期时会去访问验证Refresh Token,如果未过期则生成一个新的Access Token和Refresh Token存储在Pinia并重新进行请求原接口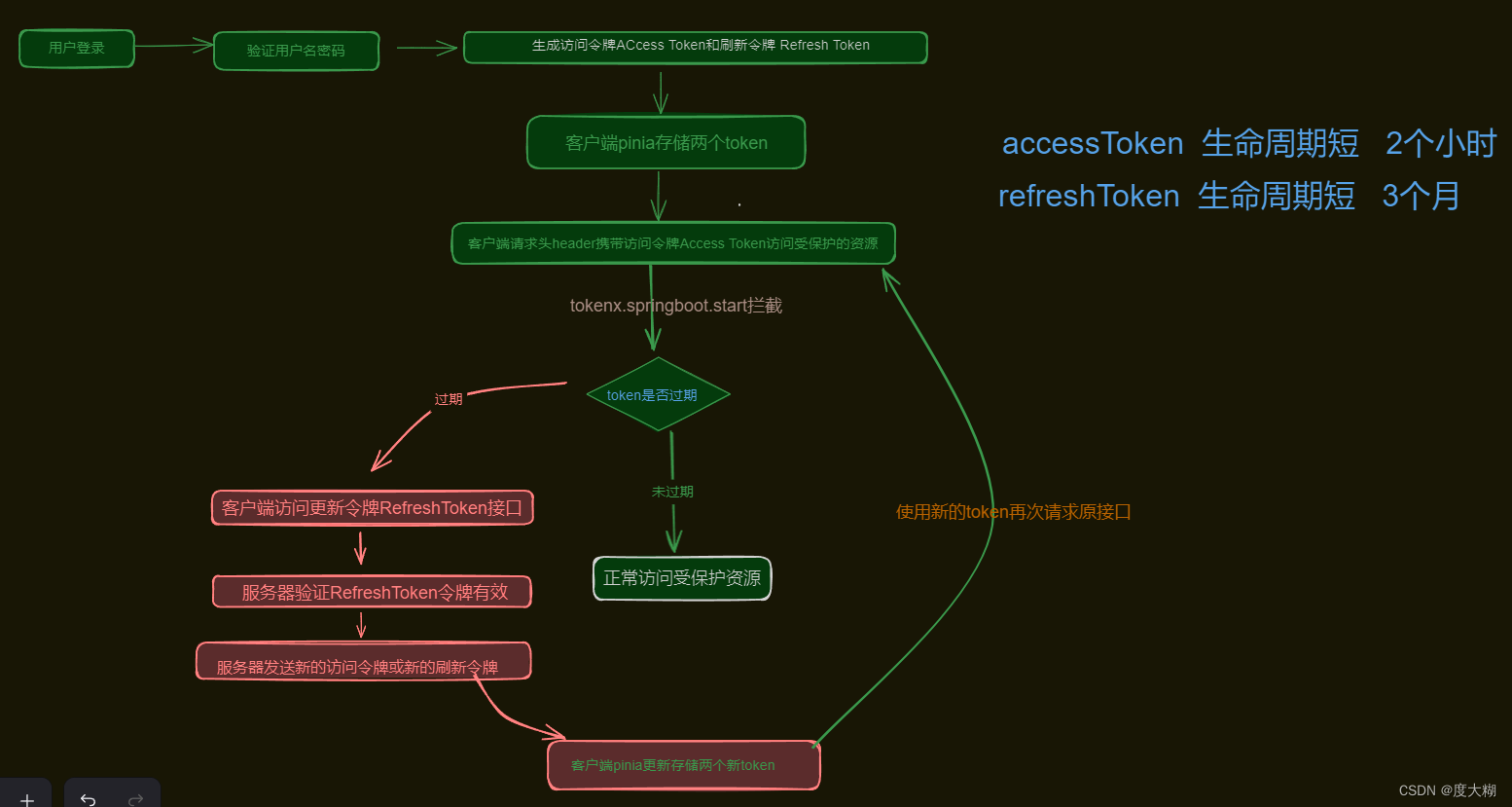
★11.谈一下你对高并发的理解和应对方式?
高并发就是指系统在短时间内应对大量访问的能力,是衡量系统稳定性的重要评估,像电商类的活动时,就需要要求系统有应对高并发能力。
①读写分离 ②Spring Cloud Sentinel [哨兵](主要作用:限流、熔断、降级) ③K8S 部署应用 [可以动态扩展副本] ④用nginx作负载均衡 ⑤Redis作缓存层 ⑥mysql数据库用集群 ⑦Lua脚本减少对数据库的请求
★12.什么是线程死锁?死锁如何产生?如何避免线程死锁?
假设线程 A 持有资源 X,并等待资源 Y,而线程 B 持有资源 Y,并等待资源 X,这时候就会出现死锁。 (线程死锁是指由于两个或者多个线程互相持有对方所需要的资源,导致这些线程处于等待状态,无法前往执行。)
如何产生?
1. 互斥条件:一个资源一次只能被一个线程持有,如果其他线程想要获取该资源,就必须等待该线程释放该资源。
2. 保持条件:一个线程请求资源时,如果已经持有了其他资源,就可以保持对这些资源的控制,直到满足所有资源的要求才释放。
3. 不剥夺条件:已经分配的资源不能被其他线程剥夺,只能由持有资源的线程释放。
4. 环路等待条件:多个线程形成一种循环等待的关系,每个线程都在等待其他线程所持有的资源,从而导致死锁的产生。
必须同时满足
如何避免:
1. 尽量避免使用多个锁,尽量使用一个锁或者使用更加高级的锁,例如读写锁或者 ReentrantLock(可重入锁)。
2.减少锁的粒度, 确保同步代码块的执行时间尽可能短,这样可以减少线程等待时间,从而避免死锁的产生。
3. 使用尝试锁,通过 ReentrantLock.tryLock() 方法可以尝试获取锁,如果在规定时间内获取不到锁,则放弃锁。
4. 避免嵌套锁,如果需要使用多个锁,请确保它们的获取顺序是一致的,这样可以避免死锁
★13.Synchronized原理?
Synchronized 的原理是,它会使用对象的内置锁(也称为监视器锁)来实现同步
特点:
1. 互斥性:Synchronized 保证同一时刻只有一个线程可以获取锁,并且只有该线程可以执行同步代码块中的代码。
2. 可重入性:同一个线程可以多次获取同步锁而不会被阻塞,这样可以避免死锁的发生。
3. 独占性: 如果一个线程获得了对象的锁,则其他线程必须等待该线程释放锁之后才能获取锁。
4.缺点:非公平锁 ,当锁被释放后,任何一个线程都有机会竞争得到锁,这样做的目的是提高效率,但缺点是可能产生线程饥饿现象。
★14.HashMap底层原理
Jdk1.7是头插法(发生死循环:头插法+多线程并发+HashMap扩容+链表),Jdk1.8是尾插法(解决了死循环)
1.7是数组+链表,1.8是数组+链表+红黑树(数组长度大于64或节点到8个开启红黑树,节点低于6个关闭红黑树转为链表)
★15.ThreadLocal 是什么?有哪些使用场景?
线程级别的存储工具,是一个线程本地变量,它可以为每一个线程都创建一个私有的变量,每个线程只能获取到自己的变量,从而避免了线程安全问题。
原理:ThreadLocal的实现原理是在每个线程内部维护了一个哈希表 键是ThreadLocal实例,值是线程局部变量的副本 每个线程都可以通过 ThreadLocalMap 获取自己的变量,修改也不会影响到其他线程的变量。
ThreadLocal 的使用场景比较广泛,一般适用于以下情况:
1. 需要保存线程的上下文信息,例如 用户信息,通过token解析出来的用户id等 ;
2. 需要对线程的局部变量进行隔离,避免线程安全问题; LocalDate LocalDateTime
3. 需要在跨类跨方法使用同一个变量,同时又不希望使用全局变量的情况;
4. 需要避免传递参数的繁琐,例如在 Spring 框架中使用的事务管理。
★16.Bean的生命周期?
1.实例化:当容器启动时,根据配置文件和注解等方式创建Bean对象的实例,放入容器管理
2.属性赋值:容器在创建Bean实例后,会对其进行属性注入,如构造函数注入,setter方法注入,自动注入等实现
3.初始化:在Bean实例全部属性赋值完成后,容器会回调其初始化方法如init()方法
4.使用:在Bean实例初始化后,可以通过容器获取Bean对象并使用
5.销毁:当容器关闭后,会回调Bean的销毁方法,如destory()方法
★17.线程池从创建到销毁中间经历了以下几个状态:
1. 初始状态:线程池被创建时,里面并没有任何线程。此时线程池的状态为初始状态。
2. 运行状态:当向线程池中提交任务后,线程池中的线程开始执行任务,此时线程池的状态为运行状态。
3. 阻塞状态:当线程池中的任务队列已满,无法再接受新的任务时,线程池会进入阻塞状态,等待任务队列中的任务被执行完毕后再接受新的任务。
4. 关闭状态:当调用线程池的shutdown()方法时,线程池会进入关闭状态,此时线程池不再接受新的任务,但会执行任务队列中的任务。
5. 停止状态:当调用线程池的shutdownNow()方法时,线程池会进入停止状态,此时线程池不再接受新的任务,并且会中断正在执行的任务。
6. 终止状态:当线程池中所有的任务都执行完毕后,线程池会进入终止状态,此时线程池中不再有任何线程。
★18.sleep()方法和wait()方法的异同点?
相同:sleep()方法和wait()方法都是使当前线程进入休眠状态。
不同:
所属类不同:sleep()方法属于Thread类的静态方法,而wait()方法属于Object类,进入timed_waiting(有限期休眠)。
唤醒方式不同:wait()方法只能根据notify()方法或者notifyAll()方法进行唤醒,进入waiting(无限期休眠)















 15万+
15万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









