







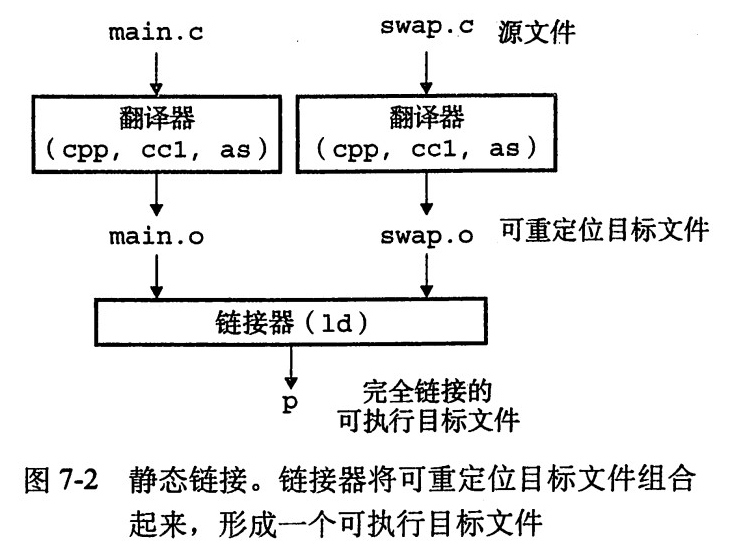
整个编译过程分为两大步:
1).编译 :把文本形式的源代码翻译成机器语言,并形成目标文件
2)连接 :把目标文件 操作系统的启动代码和库文件组织起来形成可执行程序
1.编译
细分为3个阶段:
1.1)编译预处理
预处理又称为预编译,是做些代码文本替换工作。编译器执行预处理指令(以#开头,例如#include),这个过程会得到不包含#指令的.i文件。这个过程会拷贝#include 包含的文件代码,进行#define 宏定义的替换 , 处理条件编译指令 (#ifndef #ifdef #endif)等。
有一些#开头的命令并不是在编译预处理阶段替换,如#pragma lib /link 是在链接阶段
源文件(.cpp) 预处理之后文件(.i)
1.2)编译
通过预编译输出的.i文件中,只有常量:数字、字符串、变量的定义,以及c语言的关键字:main、if、else、for、while等。这阶段要做的工作主要是,通过语法分析和词法分析,确定所有指令是否符合规则,之后翻译成汇编代码。
这个过程将.i文件转化位.s文件。
1.3) 汇编
汇编过程就是把汇编语言翻译成目标机器指令的过程,生成二进制可重定位的目标文件(.obj .o等)。目标文件中存放的也就是与源程序等效的目标的机器语言代码。
目标文件由段组成,通常至少有两个段:
.text:包换主要程序的指令。该段是可读和可执行的,一般不可写
.data .rodata:存放程序用到的全局变量或静态数据。可读、可写、可执行。
这个过程将.s文件转化成.o文件。
2.链接过程
链接是将各种代码和数据部分收集起来并组合成为一个单一文件的过程,这个文件可被加载(货被拷贝)到存储器并执行。
链接的时机
- 编译时,也就是在源代码被翻译成机器代码时
- 加载时,也就是在程序被加载器加载到存储器并执行时
- 运行时,由应用程序执行
2.1 静态链接
静态链接器以一组可重定位目标文件和命令行参数作为输入,生成一个完全链接的可以加载和运行的可执行目标文件作为输出。输入的可重定位目标文件由各种不同的代码和数据节(section)组成。指令在一个节中,初始化的全局变量在另一个节中,而未初始化的变量又在另外一个节中。
为了构造可执行文件,链接器必须完成两个任务:符号解析,重定位
- 符号解析 目标文件定义和引用符号。符号解析的目的是将每个符号引用刚好和一个符号定义联系起来。
- 重定位 编译器和汇编器生成从地址0开始的饿代码和数据节。链接器通过把每个符号定义与一个存储器位置联系起来,然后修改所有对这些符号的引用,使得它们指向这个存储器位置,从而重定位这些节。
链接器的一些基本事实:目标文件纯粹是字节块的集合。这些块中,有些包含程序代码,有些则包含程序数据,而其他的则包含指导链接器和加载器的数据结构。链接器将这些块连接起来,确定被连接块的运行时位置,并且修改代码和数据块中的各种位置。链接器和汇编器已经完成了大部分工作。
目标文件纯粹是字节快的集合。这些块中,有些包含程序代码,有些则包含程序数据,而其他的则包括指导链接器和加载器的数据结构。链接器将这些块链接起来,确定被连接块的运行时位置,并且修改代码和数据块中的各种位置。链接器对目标机器了解甚少。产生目标文件的编译器和汇编器已经完成了大部分工作。
2.2 目标文件
1.三种形式
- 可重定位目标文件。包含二进制代码和数据,其形式可以在编译时与其他可重定位目标文件合并起来,创建一个可执行目标文件。
- 可执行目标文件。包含二进制代码和数据,其形式可以被直接拷贝到存储器并执行。
- 共享目标文件。一种特殊类型的可重定位目标文件,可以在加载或者运行地被动态地加载到存储器并链接。
编译器和汇编器生成可重定位目标文件(包括共享目标文件)。链接器生成可执行目标文件。从技术上来说,一个目标模块就是一个字节序列,而一个目标文件就是一个存放在磁盘文件中的目标模块。
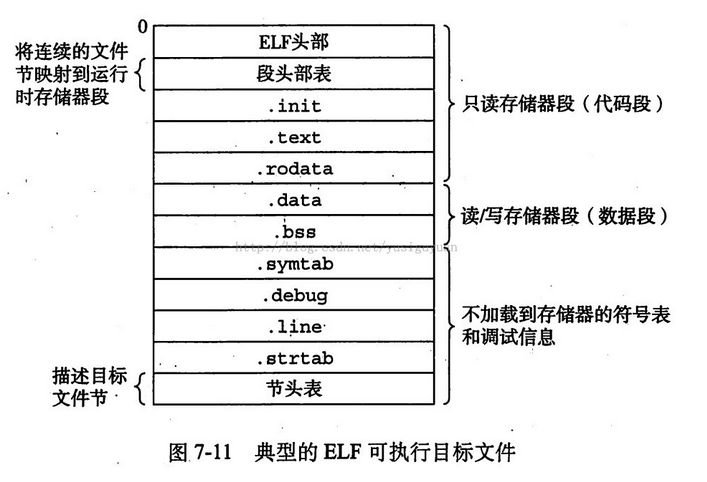
2.3 可重定位目标文件
一个典型的ELF可重定位目标文件的格式。ELF头(ELF header)以一个16字节的序列开始,这个序列描述了生成该文件的系统的字的大小和字节顺序。ELF头剩下的部分包含帮助链接器语法分析和解释目标文件的信息。其中包括ELF头的大小、目标文件的类型(如可重定位、可执行或是共享的)、机器类型(如IA32)、节头部表的文件偏移,以及节头部表中的条目大小和数量。不同的节的位置和大小是由节头部表描述的,其中目标文件中每个节都有一个固定大小的条目。

一个典型的ELF可重定位目标文件包含下面几个节:
- .text 已编译程序的机器代码
- .rodata 只读数据
- .data 已初始化的全局C变量。局部C变量在运行时保存在栈中,既不出现在.data节中 ,也不出现在.bss节中。
- .bass 未初始化的全局C变量。在目标文件中这个节不占据实际的空间,它仅仅是一个占位符。目标文件格式区分初始化和未初始化变量是为了空间效率:在目标文件中,未初始化变量不需要占据任何实际的磁盘空间。
- .symtab 一个符号表,它存放在程序中定义和引用的函数和全局变量的信息。每个可重定位目标文件在.symtab中都有一张符号表 。
- .rel.text 一个.text节中位置的列表,当链接器吧这个目标文件和其他文件结合时,需要修改这些位置。一般而言,任何调用外部函数或引用全局变量的指令都需要修改。另一方面,调用本地函数的指令则不需要修改。注意,可执行目标文件中并不需要重定位信息,因此通常省略,除非用户显示第指示链接器包含这些信息。
- .rel.data 被模块引用或定义的任何全局变量的重定位信息。一般而言,任何已初始化的全局变量,如果它的初始值是一个全局变量地址或者外部定义函数的地址,都需要被修改。
- .debug 一个调试符号表,其条目是程序总定义的局部变量和类型定义,程序中定义和引用的 全局变量,以及原始的C源文件。
- .line 原始C源文件中的行号和.text节中机器指令之间的映射。
- .strtab 一个字符串表,其内容包括.symtab和.debug节中的符号表,以及节头部中的节名字。
2.4 符号和符号表
每个可重定位目标模块m都有一个符号表,包含m所定义和引用的符号的信息。符号表产生在汇编阶段,符号表生成虚拟地址在链接阶段
在链接器的上下文中,有三种不同的符号:
- 由m定义并能被其他模块引用的全局符号
- 由其他模块定义并被模块m引用的全局符号
- 只被模块m引用的本地符号
例如:
main.cpp 内容 和sum.cpp 内容如下

g++ -c 只编译不链接,只生成目标文件

objdump -t main.o//输出目标文件的符号表
每一列的含义:
第一列:段内偏移
第二列:符号作用域 : local /global
第三列:符号类型
第四列:符号所在段(*UND*外部链接符号,未在本目标文件定义)
第五列:符号对应的对象占据的内存空间大小,没有实体对象大小为0,未定义的为0
第六列:符号名

其中main 定义在.text
data 是全局变量,且初始化定义在.data ,也就是m定义并能被其他模块引用的全局符号
gdata和sum函数是声明,因此是*UNG*,也就是由其他模块定义并被模块m引用的全局符号
第一列都是0x0 没有为符号分配虚拟地址,在链接阶段分配
在sum.o中

gdata 是出刷的全局变量 在 .data中;sum 函数在.text中
readelf -h 查看elf文件的头文件信息
可见目标文件的elf文件,其类型为REL(可重定位文件)。
objdump -s 显示全部Header信息,还显示他们对应的十六进制文件代码

查看二进制可重定向目标文件的汇编:
![]()
-g 带上调试信息
 可以看到符号地址未分配,用0填充;这也是obj文件无法运行的原因之一
可以看到符号地址未分配,用0填充;这也是obj文件无法运行的原因之一
2.5 符号解析
链接的步骤一:所有.o文件段的合并(.text .data .bss合并),符号表合并后,进行符号解析,所有对符号的引用(*UNG*)都要找到该符号定义的地方。经常见的报错:符号重定义(存在多个相同的)、符号未定义(找不到)
链接器如何解析多重定义的全局符号
在编译是,编译器向汇编器输出每个全局符号,或者是强或者是弱,而汇编器把这个信息隐含地编码在可重定位目标文件的符号表里。函数和已初始化的全局变量时强符号,未初始化的全局变量是弱符号。
根据强弱符号的定义,Unix链接器使用下面的规则来处理多重定义的符号:
- 规则1:不允许有多个强符号。
- 规则2:如果有一个强符号和多个弱符号,那么选择强符号。
- 规则3:如果有多个弱符号,那么从这些弱符号中任意选择一个。
链接器如何使用静态库来解析引用
在符号解析的阶段,链接器从左到右按照它们在编译器驱动程序命令行上出现的相同顺序来扫描可重定位目标文件和存档文件。在这次扫描中,链接器维持一个可重定位目标文件的集合E(这个集合中的文件会被合并起来形成可执行文件),一个未解析的符号(即引用了但是尚未定义的符号)集合U,以及一个在前面输入文件中已定义的符号集合D。初始时,E、U和D都是空的。
1.对于命令行上的每个输入文件f,链接器会判断f是一个目标文件还是一个存档文件。如果f是一个目标文件,那么链接器吧f添加到E, 修改U和D来反映f中的符号定义和引用,并继续下一个输入文件。
2.如果f是一个存档文件,那么链接器就尝试匹配U中未解析的符号和由存档文件成员定义的符号。如果某个存档文件成员m,定义了一个符号来解析U中的一个引用,那么就将m加到E中,并且链接器修改U和D来反映m中的符号定义和引用。对存档文件中所有的成员目标文件都反复进行这个过程,直到U和D都不再发生变化。在此时,任何不包含在E中的目标文件都简单地被丢弃,而链接器将继续处理下一个输入文件。
3.如果当链接器完成对命令行上输入文件的扫描后,U是非空的,那么链接器就好输出一个错误并终止。否则,它会合并和重定位E中的目标文件,从而构建输出的可执行文件。
这种算法会导致一些令人困扰的链接时错误,因为命令行上的库和目标文件的顺序非常重要。在命令行中,如果定义一个符号的库出现在引用这个符号的目标文件之前,那么引用就不能被解析,链接会失败。关于库的一般准则是将它们放在命令行的 结尾。
另一方面,如果库不是相互独立的,那么它们必须排序,使得对于每个被存档文件的成员外部引用的符号s,在命令行中至少有一个s的定义实在对s的引用之后的。
如果需要满足依赖需求,可以在命令行上重复库。
2.6 重定位
一旦链接器完成了符号解析这一步,它就是把代码中的每个符号引用和确定的一个符号定义(即它的一个输入目标模块中的一个符号表条目)联系起来。在此时,链接器就知道它的输入目标模块中的代码节和数据节的确切大小。现在就可以开始重定位了,在这个步骤中,将合并输入模块,并为每个符号分配运行时地址。
重定位有两步组成:
1.重定位节和符号定义。在这一步中,链接器将所有相同类型的节合并为同一类型的新的聚合节。然后,链接器将运行时存储器地址赋给新的聚合节,赋给输入模块定义的每个节,以及赋给输入模块定义的每个符号。当这一步完成时,程序中的每个指令和全局变量都有唯一的运行时存储器地址了。
2.重定位节中的符号引用。在这一步中,链接器修改代码节和数据节中对每个符号的引用,使得它们指向正确的运行时地址。为了执行这一步,链接器依赖于称为重定位条目的可重定位目标模块中的数据结构。
如:

链接后:所有的符号都有虚拟地址
 汇编中,全局变量和函数都有了地址
汇编中,全局变量和函数都有了地址
2.7 可执行目标文件
可执行目标文件的格式类似于可重定位目标文件的格式。ELF头部描述文件的总体格式。它还包括程序的入口点,也就是当程序运行时要执行的第一条指令的地址。.text 、.rodata和.data 节和可重定位目标文件中的节是相似的,除了这些节已经被重定位到它们最终的运行时存储器地址以外。.init节定义了一个小函数,叫做_init,程序的初始化代码会调用它。因为可执行文件是完全链接的(已被重定位了),所以它不再需要.rel节。
ELF可执行文件被设计得很容易加载到存储器,可执行文件的连续的片被映射到连续的存储器段。段头部表描述了这种映射关系。

看出可执行目标文件的文件类型是exec,入口地址是0x4000e8,即main的地址:

在可执行目标文件中存在 program header(段头部表),可执行目标文件中有 .text .data .bss .stack 等,执行时并不是都要加载到内存中;需要加载的段在program header中记录 load xx 在该a.out中,加载了.text 和.data
 加载到内存后,找到入口地址,开始执行指令;然后就是进程的虚拟地址空间
加载到内存后,找到入口地址,开始执行指令;然后就是进程的虚拟地址空间















 6761
6761











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









