







按照 CPU 功能升级迭代的顺序,CPU 的工作模式有实模式、保护模式、长模式
1. 实模式,早期 CPU 是为了支持单道程序运行而实现的,单道程序能掌控计算机所有的资源,早期的软件规模不大,内存资源也很少,所以实模式极其简单,仅支持 16 位地址空间,分段的内存模型,对指令不加限制地运行,对内存没有保护隔离作用。
2. 保护模式,随着多道程序的出现,就需要操作系统了。内存需求量不断增加,所以 CPU 实现了保护模式以支持这些需求。保护模式包含特权级,对指令及其访问的资源进行控制,对内存段与段之间的访问进行严格检查,没有权限的绝不放行,对中断的响应也要进行严格的权限检查,扩展了 CPU 寄存器位宽,使之能够寻址 32 位的内存地址空间和处理 32 位的数据,从而 CPU 的性能大大提高。
3. 长模式,又名 AMD64 模式,最早由 AMD 公司制定。由于软件对 CPU 性能需求永无止境,所以长模式在保护模式的基础上,把寄存器扩展到 64 位同时增加了一些寄存器,使 CPU 具有了能处理 64 位数据和寻址 64 位的内存地址空间的能力。长模式弱化段模式管理,只保留了权限级别的检查,忽略了段基址和段长度,而地址的检查则交给了 MMU。
从一个多程序并发的场景说起
设想一下,如果一台计算机的内存中只运行一个程序 A,这种方式正好用前面 CPU 的实模式来运行,因为程序 A 的地址在链接时就可以确定,例如从内存地址 0x8000 开始,每次运行程序 A 都装入内存 0x8000 地址处开始运行,没有其它程序干扰。
现在改变一下,内存中又放一道程序 B,程序 A 和程序 B 各自运行一秒钟,如此循环,直到其中之一结束。这个新场景下就会产生一些问题,当然这里我们只关心内存相关的这几个核心问题。
1. 谁来保证程序 A 跟程序 B 没有内存地址的冲突?换句话说,就是程序 A、B 各自放在什么内存地址,这个问题是由 A、B 程序协商,还是由操作系统决定。
2. 怎样保证程序 A 跟程序 B 不会互相读写各自的内存空间?这个问题相对简单,用保护模式就能解决。
3. 如何解决内存容量问题?程序 A 和程序 B,在不断开发迭代中程序代码占用的空间会越来越大,导致内存装不下。
4. 还要考虑一个扩展后的复杂情况,如果不只程序 A、B,还可能有程序 C、D、E、F、G……它们分别由不同的公司开发,而每台计算机的内存容量不同。这时候,又对我们的内存方案有怎样的影响呢?
要想完美地解决以上最核心的 4 个问题,一个较好的方案是:让所有的程序都各自享有一个从 0 开始到最大地址的空间,这个地址空间是独立的,是该程序私有的,其它程序既看不到,也不能访问该地址空间,这个地址空间和其它程序无关,和具体的计算机也无关。事实上,计算机科学家们早就这么做了,这个方案就是虚拟地址
虚拟地址
我们用 objdump 工具反汇编一下 Hello World 二进制文件,就会得到如下的代码片段
00000000000004e8 <_init>:
4e8: 48 83 ec 08 sub $0x8,%rsp
4ec: 48 8b 05 f5 0a 20 00 mov 0x200af5(%rip),%rax # 200fe8 <__gmon_start__>
4f3: 48 85 c0 test %rax,%rax
4f6: 74 02 je 4fa <_init+0x12>
4f8: ff d0 callq *%rax
4fa: 48 83 c4 08 add $0x8,%rsp
4fe: c3 retq 上述代码中,左边第一列数据就是虚拟地址,第三列中是程序指令,如:“mov 0x200af5(%rip),%rax,je 4fa,callq *%rax”指令中的数据都是虚拟地址。
事实上,所有的应用程序开始的部分都是这样的。这正是因为每个应用程序的虚拟地址空间都是相同且独立的。那么这个地址是由谁产生的呢?
答案是链接器,其实我们开发软件经过编译步骤后,就需要链接成可执行文件才可以运行,而链接器的主要工作就是把多个代码模块组装在一起,并解决模块之间的引用,即处理程序代码间的地址引用,形成程序运行的静态内存空间视图。
只不过这个地址是虚拟而统一的,而根据操作系统的不同,这个虚拟地址空间的定义也许不同,应用软件开发人员无需关心,由开发工具链给自动处理了。由于这虚拟地址是独立且统一的,所以各个公司开发的各个应用完全不用担心自己的内存空间被占用和改写。
虚拟地址到物理地址的转换
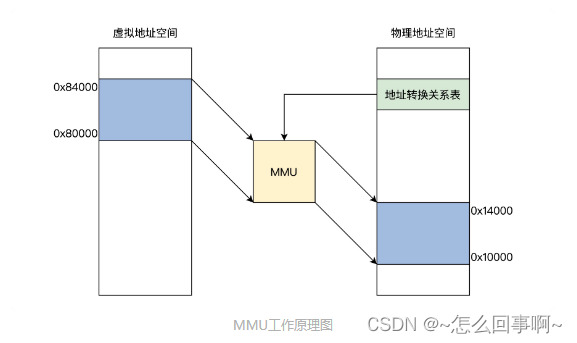
明白了虚拟地址和物理地址之后,我们发现虚拟地址必须转换成物理地址,这样程序才能正常执行。要转换就必须要转换机构,它相当于一个函数:p=f(v),输入虚拟地址 v,输出物理地址 p。那么要怎么实现这个函数呢?
用软件方式实现太低效,用硬件实现没有灵活性,最终就用了软硬件结合的方式实现,它就是 MMU(内存管理单元)。MMU 可以接受软件给出的地址对应关系数据,进行地址转换。我们先来看看逻辑上的 MMU 工作原理框架图。如下图所示:
Cache与内存
CPU 大多数时间在执行相同的指令或者与此相邻的指令。这就是大名鼎鼎的程序局部性原理。
Cache让我们重新回到前面的场景中,回到程序的局部性原理,它告诉我们:CPU 大多数时间在访问相同或者与此相邻的地址。那么,我们立马就可以想到用一块小而快的储存器,放在 CPU 和内存之间,就可以利用程序的局部性原理来缓解 CPU 和内存之间的性能瓶颈(cpu要数据的速度远远快于内存取数据的速度)。这块小而快的储存器就是 Cache,即高速缓存。
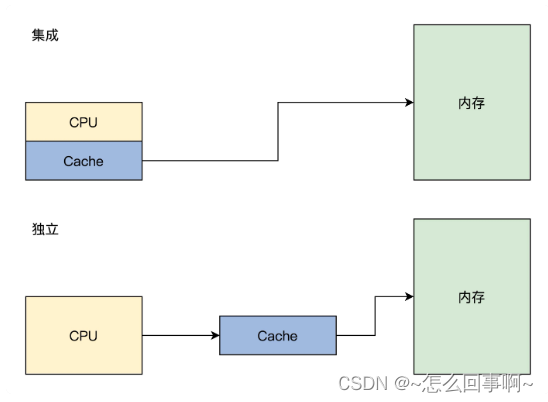
Cache 中存放了内存中的一部分数据,CPU 在访问内存时要先访问 Cache,若 Cache 中有需要的数据就直接从 Cache 中取出,若没有则需要从内存中读取数据,并同时把这块数据放入 Cache 中。但是由于程序的局部性原理,在一段时间内,CPU 总是能从 Cache 中读取到自己想要的数据。Cache 可以集成在 CPU 内部,也可以做成独立的芯片放在总线上,现在 x86 CPU 和 ARM CPU 都是集成在 CPU 内部的。其逻辑结构如下图所示。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









