







官方文档
基本属性
显示详细
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四'],
"语文": [89, 77]
})
d1.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 2 entries, 0 to 1
Data columns (total 2 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 姓名 2 non-null object
1 语文 2 non-null int64
dtypes: int64(1), object(1)
memory usage: 160.0+ bytes
行总数
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四','赵五'],
"语文": [89, 77,55]
})
len(d1.values) #一共有3行
列总数
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四','赵五'],
"语文": [89, 77,55]
})
len(d1.columns) #一共有2列
获取列名
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四','赵五'],
"语文": [89, 77,55]
})
d1.columns #返回一个列表 ['姓名', '语文']
增
新增DataFrame
现实情况下,数据来源一般是网页JSON,CSV文件等,不会手工输入一个字典.
使用字典新增
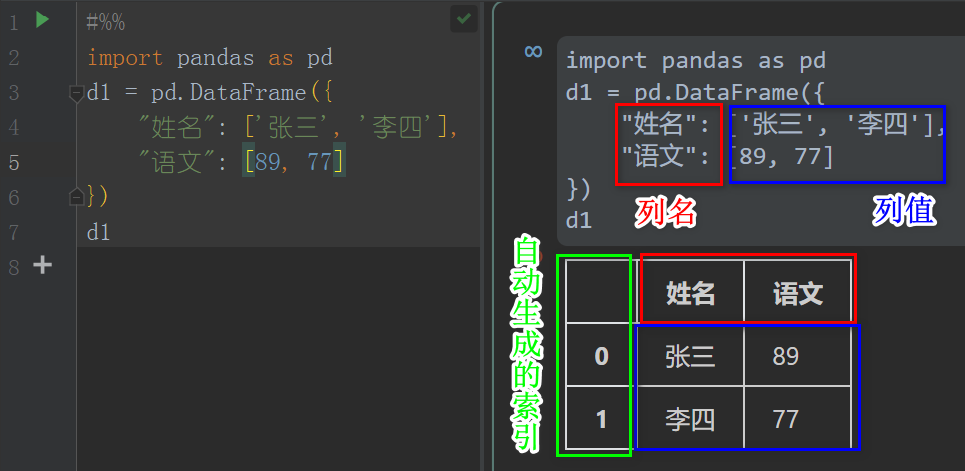
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四'],
"语文": [89, 77]
})
d1
使用列表新增
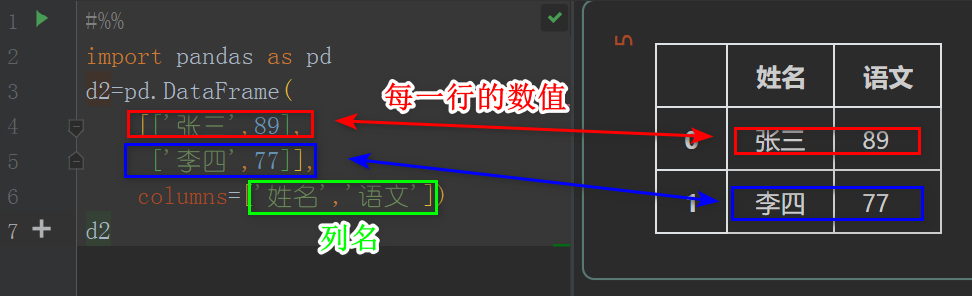
import pandas as pd
d2=pd.DataFrame(
[['张三',89],
['李四',77]],
columns=['姓名','语文'])
d2
新增列
在最后新增一列
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55]
})
d1['数学']=[56,98,45]
d1
在任意位置插入一列
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55]
})
d1.insert(loc=1, column='数学', value=[77, 88, 0])
d1

插入多列(只能在最后)
第一种方法是遍历一个字典,循环调用insert()
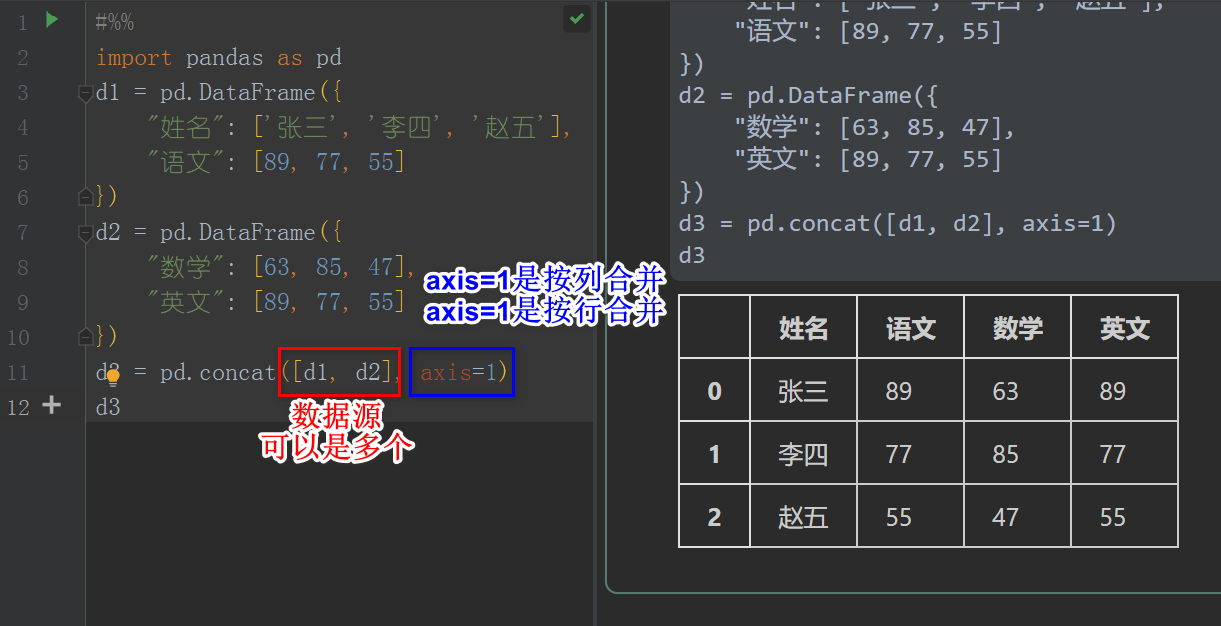
第二种方法是把要插入的列,转到DataFrame,再用pd.concat()合并,这里的合并是不考虑匹配的.考虑匹配的方法在后面介绍.
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55]
})
d2 = pd.DataFrame({
"数学": [63, 85, 47],
"英文": [89, 77, 55]
})
d3 = pd.concat([d1, d2], axis=1)
d3
新增行
在最后新增一行
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55]
})
d1.loc[len(d1.values)]=['林九',99]
d1
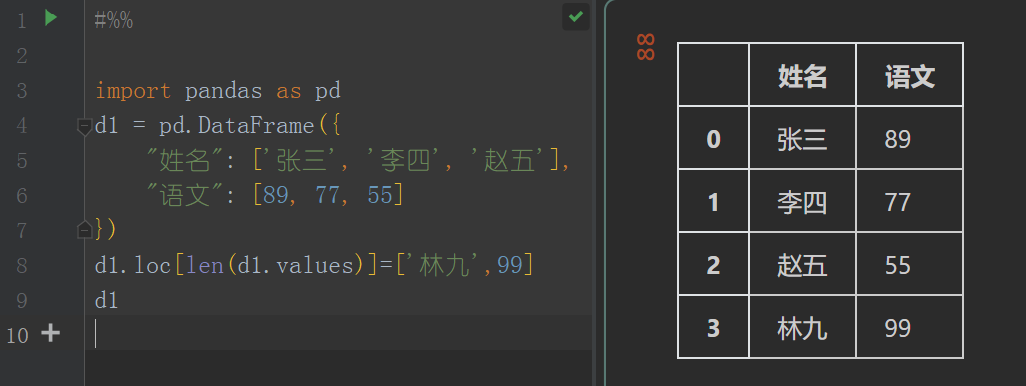
这里使用 loc[行标识] 来操作,他会先在原有 行标识 里查找,如果没有就新增一行,如果有,就改定这一行.
在任意位置插入一行
import numpy as np
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55],
})
d2 = pd.DataFrame(np.insert(d1.values, 2, values=['林九',56], axis=0))
d2
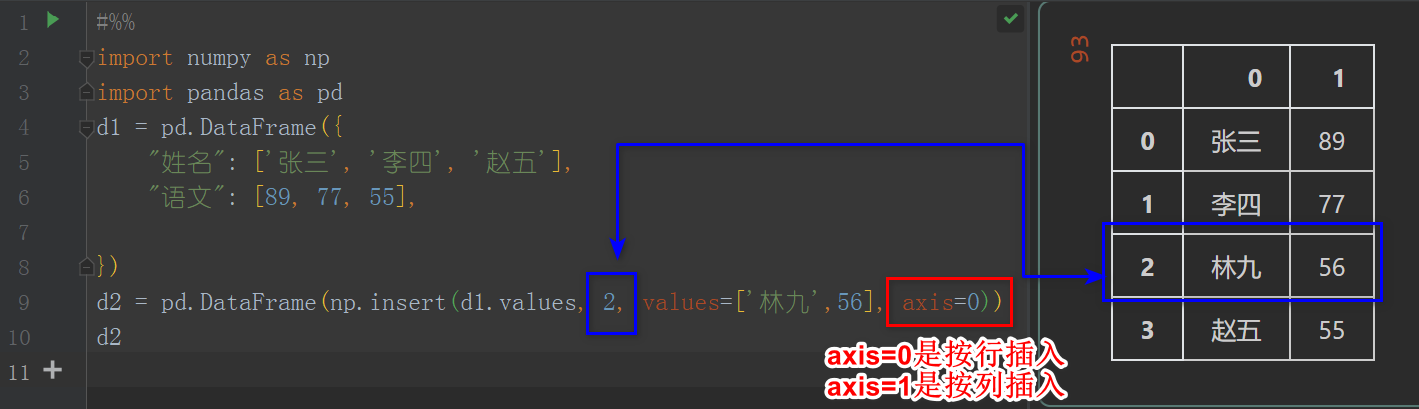
这里是先把DataFrame的值转换成numpy对象,再用numpy.insert()进行插入操作.
插入多行
第一种方法是像插入一行哪样,但传入的值是一个列表,列表里装多行数据.
import numpy as np
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五'],
"语文": [89, 77, 55],
})
d2 = pd.DataFrame(np.insert(d1.values, 2, values=[['林九',56],['张五',78]], axis=0))
d2
删
删除一列或多列
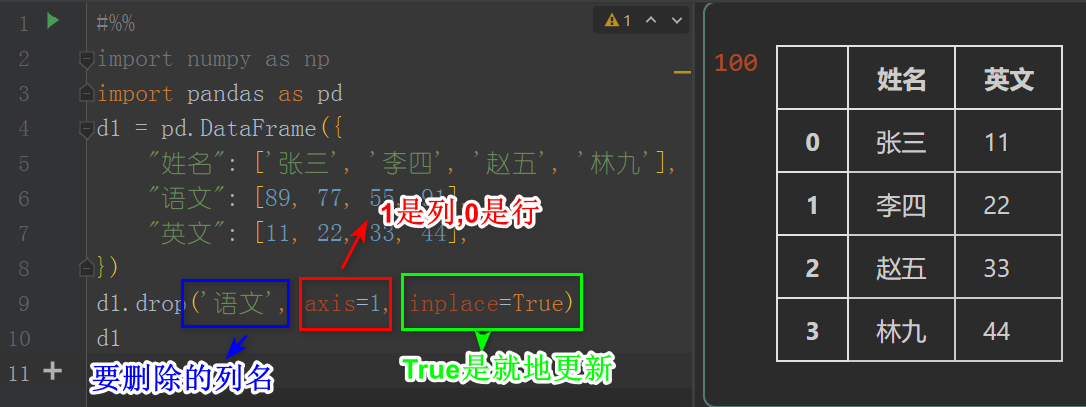
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英文": [11, 22, 33, 44],
})
d1.drop('语文', axis=1, inplace=True)
d1
删除一行或多行
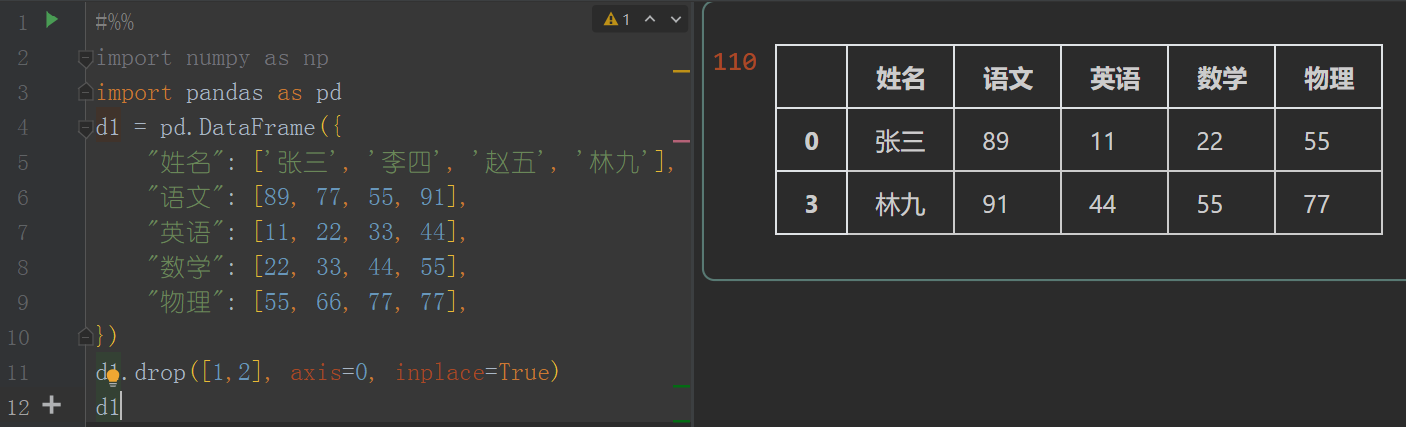
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
d1.drop([1,2], axis=0, inplace=True)
d1
改和查
使用loc和iloc可以对DataFrame进行切片.
他是双向属性:可写也可读
在等号左边就是改
在等号右边就是查
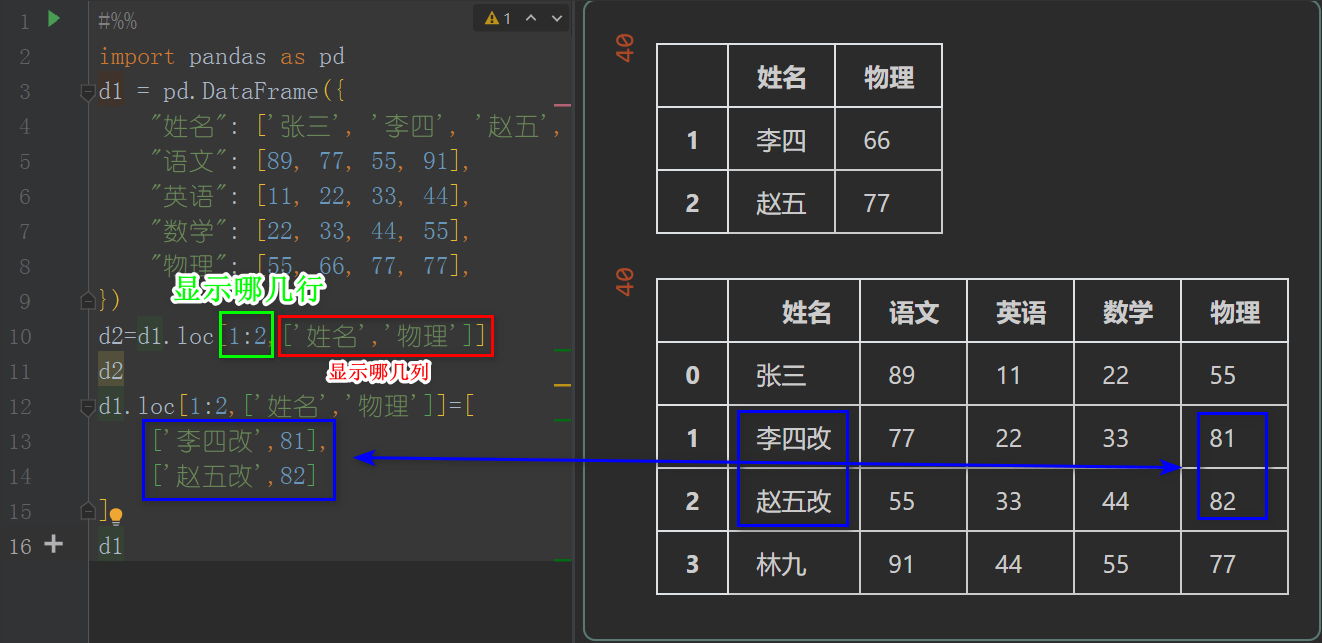
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
d2=d1.loc[1:2,['姓名','物理']]
d2
d1.loc[1:2,['姓名','物理']]=[
['李四改',81],
['赵五改',82]
]
d1
loc和iloc的重要参数
loc[行范围,列范围]
iloc[行范围,列范围]
行范围和列范围的表示方法
行范围以索引为参考值
列范围是以列名为参考值
loc在行范围可以使用数字和文本来定位(根据索引的数据类型),列范围必须使用文本来定位
iloc在行和列范围全是使用数字来定位
定位参数可以是:
单个
一个数字或一个文本
连续范围
数字冒号数字
文本冒号文本
不连续的范围
传入一个列表
[数字,数字]
[文本,文本]
loc详解
loc是使用文本标签来进行切片
如果索引是数字类型,可使用数字来选择行范围
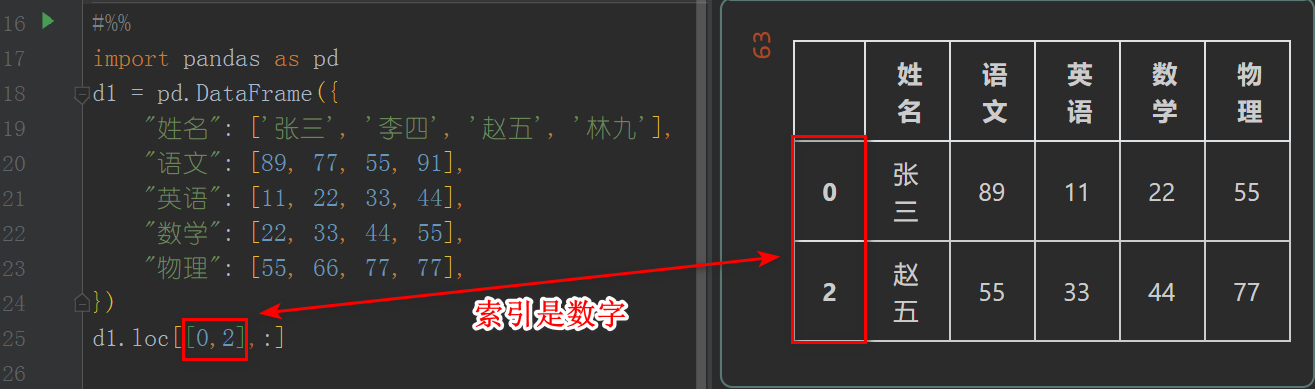
索引是数字类型
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
d1.loc[[0,2],:]
索引是文本类型
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
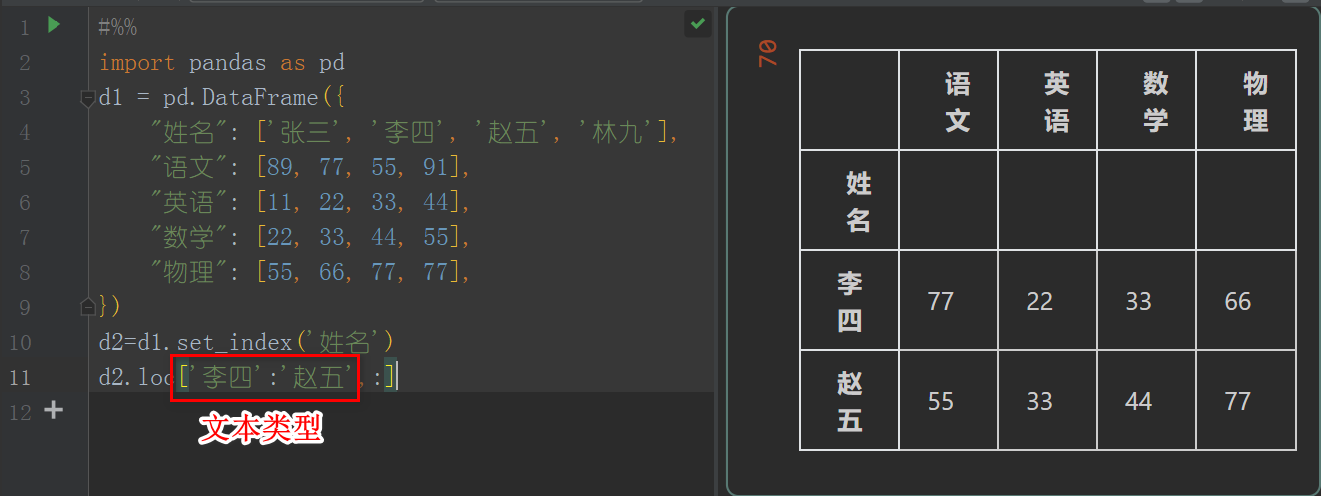
d2=d1.set_index('姓名')
d2.loc['李四':'赵五',:]
例子
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '林九'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
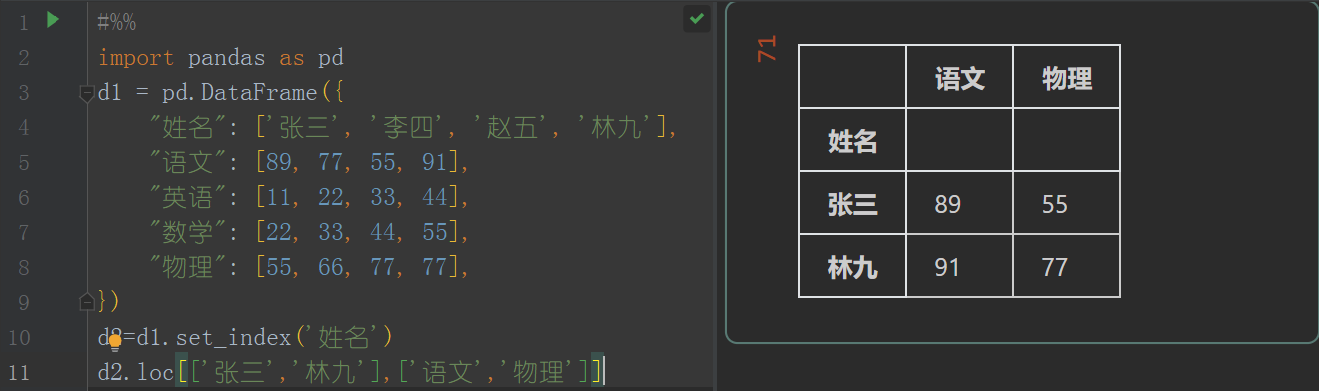
d2=d1.set_index('姓名')
d2.loc[['张三','林九'],['语文','物理']]
iloc详解
import pandas as pd
d1 = pd.DataFrame({
"姓名": ['张三', '李四', '赵五', '李四'],
"语文": [89, 77, 55, 91],
"英语": [11, 22, 33, 44],
"数学": [22, 33, 44, 55],
"物理": [55, 66, 77, 77],
})
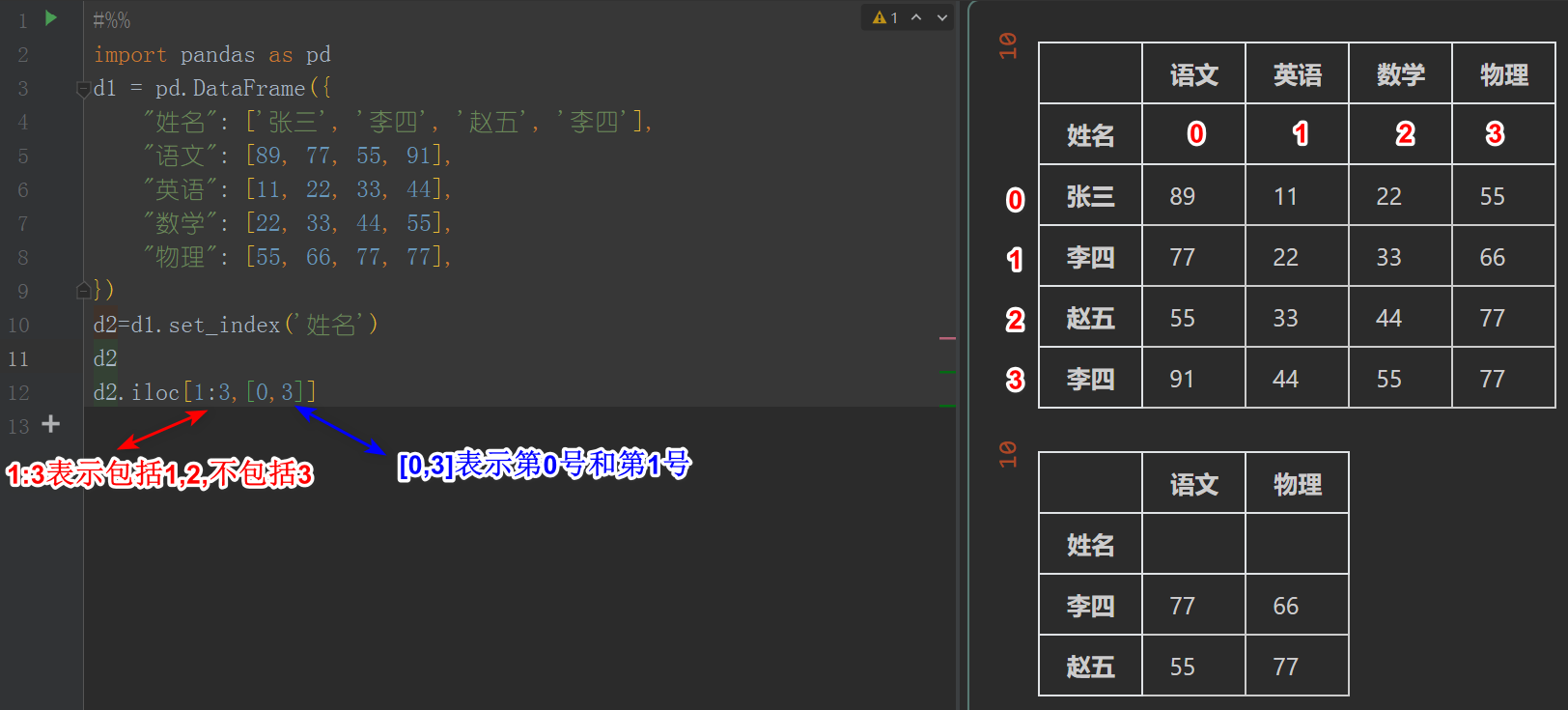
d2=d1.set_index('姓名')
d2.iloc[1:3,[0,3]]















 891
891











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









