






本文章主要是提出了使用蒙特卡洛树搜索来探索app。这样会得到很多条正确或不正确的轨迹,而作者的方法允许模型从无论正确与否的轨迹中来学习。同时本文还使用了强化学习的知识。这下触及知识盲区了,恶补一下:
DPO学习:
比如说,面前有两个老虎机,两个老虎机出奖励的概率和大小都不一样,我们肯定是选择期望最高的那个。但是我们事先不知道那个期望更高,因此要多次尝试,将尝试的结果的平均数作为对“选择这个老虎机”的价值估计。这个就叫做“行动价值的估计表达式”,也就是价值函数。
相应的,我们也就可以得到策略函数。比如说使用贪心做法,一直选择价值函数更大的那个,就是一种方法。可以看到,每次我们做出选择,我们都会得到一个新的价值,这个价值就可以对我们之前的价值函数进行修改,也就有可能修改我们将来的做法。当然纯贪婪的做法一般是不好的,我们可以选择每次做决定的时候有i的概率发神经,选别的,这样也可以更新另一个的价值函数.
当然这个是最基本的强化学习算法,可以及时得到奖励,也不存在多个状态(永远是两个老虎机,概率分布永远不会变)
下面是更新价值函数的公式(还是用之前的那个做平均的方法)
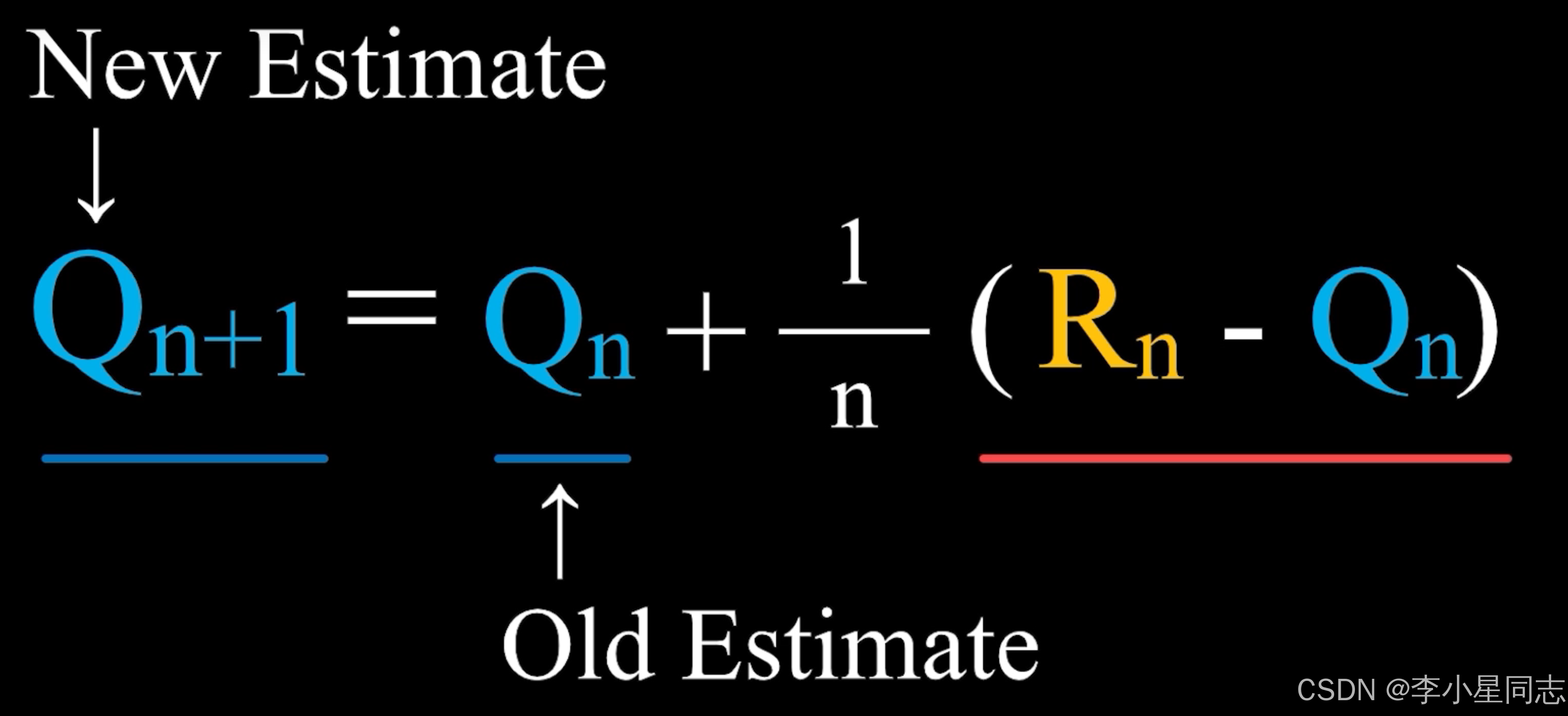
可以看到,可以通过奖励预测误差来更新价值估计。平均法中的步长是1/n,当然我们也可以手动修改。:
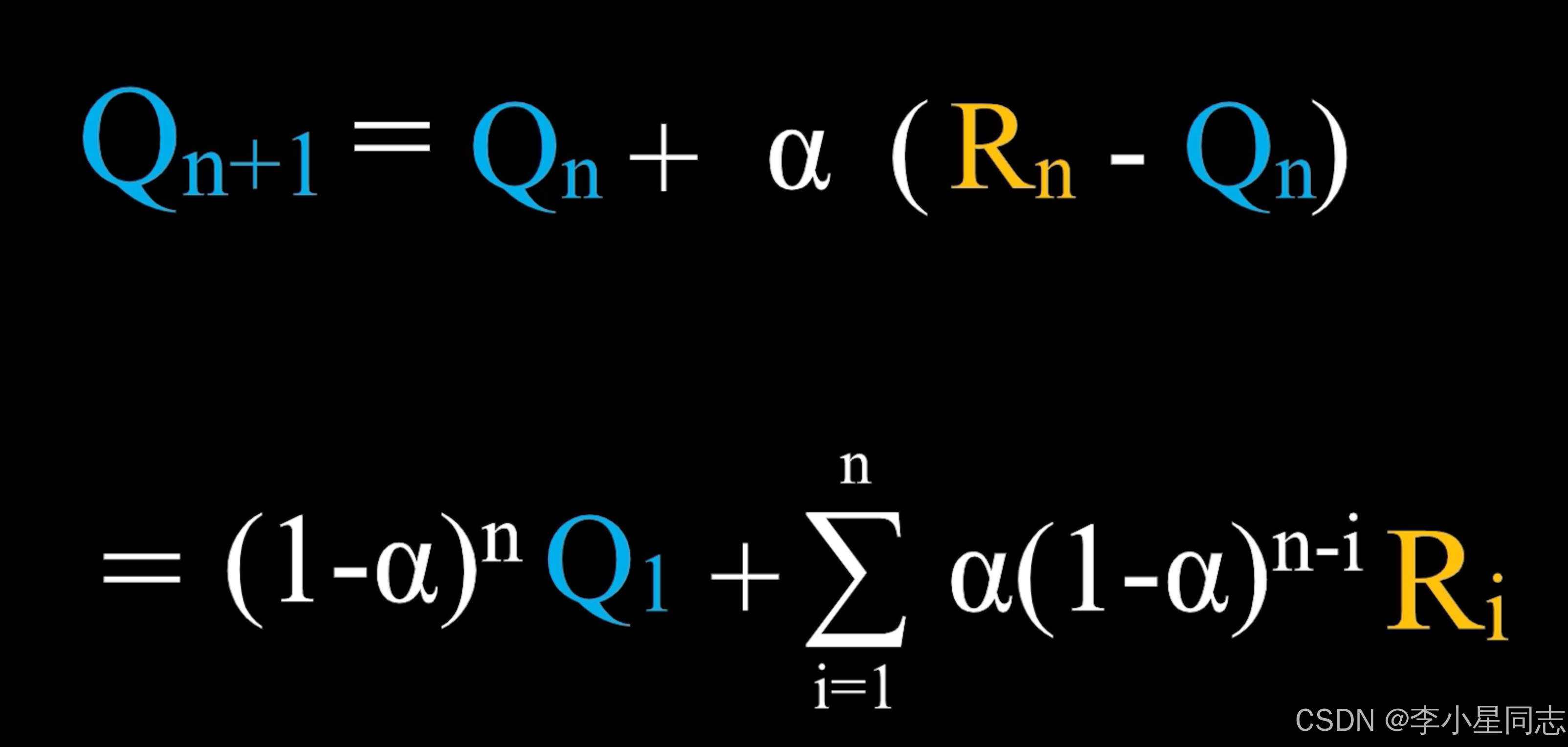
改成加权平均,这样对最近的改变更敏感。
那么,假如遇到了有多个状态,有延迟奖励的问题怎么办呢?
我们用井字棋来演示怎么做。
下面这个是状态-动作的价值估计公式

St代表状态,At代表采取的行动,这么做就是在更新这个St下At行动的预期奖励。
上下是两种不同的方法,上面这种使用了实际上最后的价值与预期的估计的差值来计算,而下面这种方法使用的是实际上t步的价值与接下来的估计减去之前估计的价值来得到误差,用来更新新的预期估计。下面这种方法不需要把事情都做完了再更新,上面这种需要。
相应的我们可以写出状态价值公式
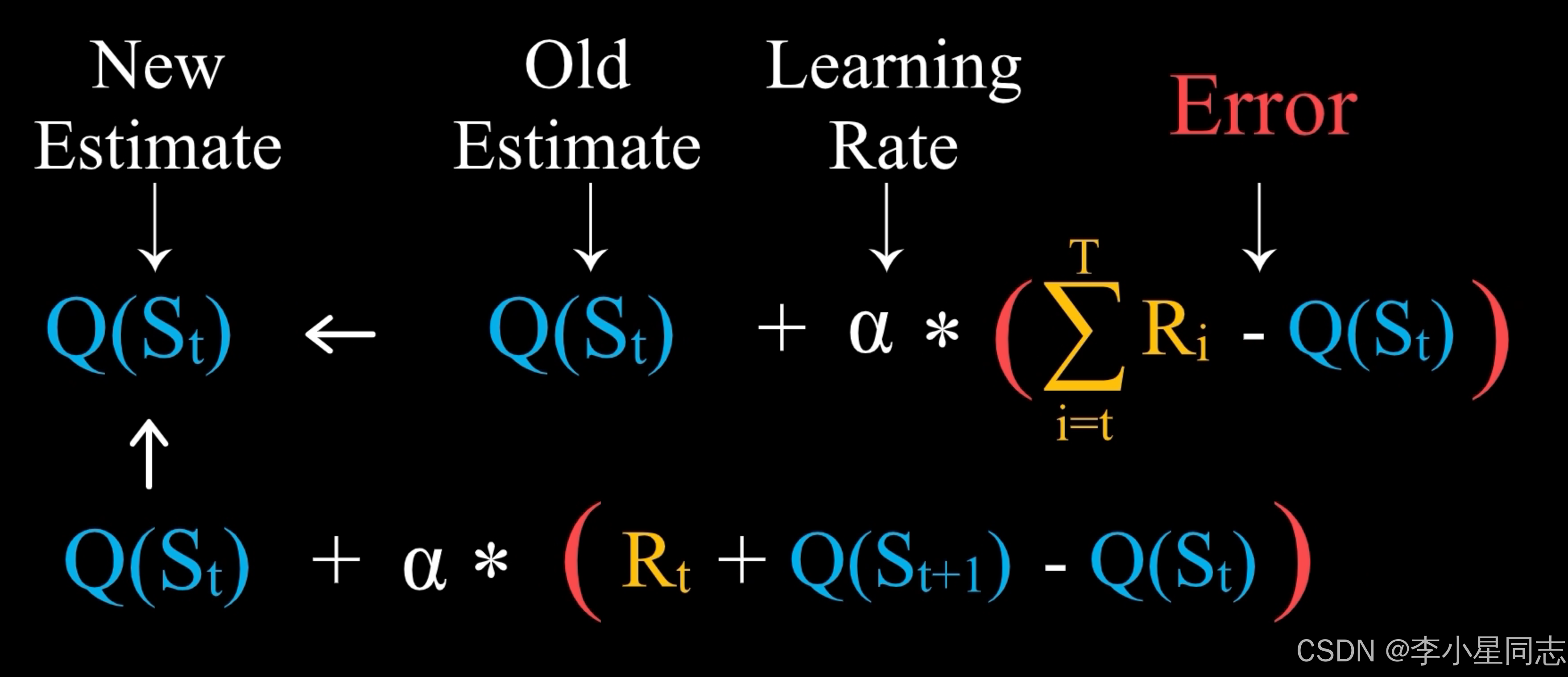
一开始的时候这些Q可能都是0或者别的什么随便取的数。通过不断地尝试,我们可以通过最后得到的结果不断地更新这些Q。这样,Q可以记录下在什么样的状态下,是用什么样的动作大概是什么样的价值,这样系统就会更倾向于进行这样的行动。当然,使用原始贪心策略的话也可能会一直采用同一种行动。
可以看到强化学习和深度学习区别还是很大的,没有那些熟悉的东西,成堆的参数,有的只是Q,也就是记录着价值的这个函数,这个函数其实就是决定了系统下一步采用某个动作的概率。假如有某一步取得了真实奖励,导致这一步产生的那些过程的Q就会上升,下一次被选中的概率就会更大。
上面这种方法被称为Qlearning方法。一句话总结,就是每次交互后,智能体根据新的奖励 rt+1r_{t+1}rt+1 和下一状态的最大预期奖励调整当前状态行动对的 Q 值,逐渐使 Q 值逼近真实的最优值。注意Qlearning是只会使用预期奖励最大的那个来做预测的。:
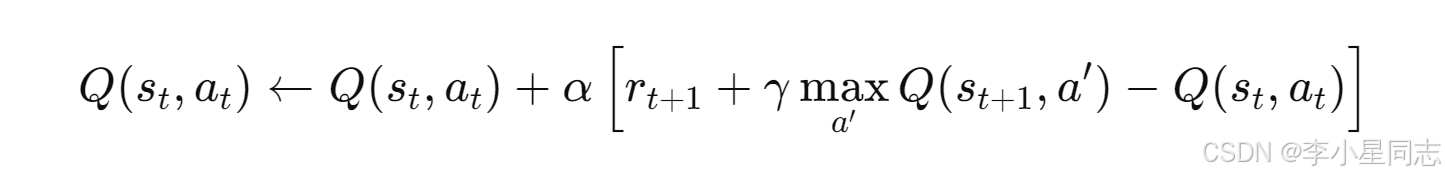
sarsa方法就不一样了:
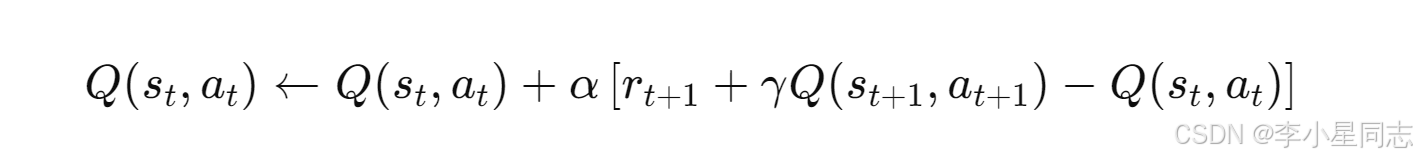
它会真的去做一个,然后根据接下来的结果来更新Q
sarsa可以调整修改Q的时间。它可以在完成一步之后立刻修改Q,也可以多走几步,依靠多步的信息再修改之前的Q。你甚至可以把任务都完成了,再去修改Q.
在修改Q的时候,很显然离最后那一步近的与结果关系大,离得远的关系小,那么Q的修改幅度也是一样,离的近的修改多,离得远的修改少。
当然,以上提到的方法都是传统方法,Q是比较死板的,像表格一样单纯的记录着状态和动作们的价值。要是状态和动作特别多怎么办?表格可记录不完。深度学习这时候就有大用了。也就是DQN(deep Qlearning)
我们用神经网络来代替Q,有误差那我们刚好可以求梯度,直接更新就好。
这与直接使用神经网络有啥区别?假如是直接使用神经网络,那可能是输入状态,然后由神经网络输出结果(下一步动作)。假如使用DQN,那就是将当前状态输入给神经网络,神经网络计算出所有动作对应的价值,价值高的选择概率高,价值低的选择概率低。
强化学习就差不多先了解到这里,接下来回到论文。
“为了实现这一目标,我们引入了Agent Q——一种结合了推理、搜索、自我批评和强化学习中几个关键概念的新方法。”
这论文缝合怪啊,好多没见过的方法。
我们在网页上部署了一个基于蒙特卡洛树搜索(MCTS)的搜索例程,以指导代理探索
“为了克服这一点,我们使用人工智能反馈(Bai等人,2022)和自我批评(Yuan等人,2024)来进一步提示LLM在每个节点提供自我评估反馈,这是一种中间奖励,有助于指导搜索步骤。”
通过这些反馈,模型探索的成功率会大大提升。但这一步需要别的模型,可能不是什么时候都能用。文章提出一种方法,就是先在线下按照蒙特卡洛树方法收集轨迹,成功或者失败的都用,然后用强化学习来训练模型。
一个问题:“用强化学习来训练模型”是怎么一回事?根据我之前的学习,强化学习和深度学习可是很不一样的。答案在此:
强化学习(Reinforcement Learning, RL)的大语言模型(Large Language Models, LLMs)与普通的LLMs的核心区别在于训练方法的不同。以下是强化学习大语言模型(RL-LM)的工作原理以及与普通大语言模型的区别:
工作原理:
-
普通大语言模型(LLMs): 普通的大语言模型使用的主要训练方式是监督学习(Supervised Learning)。它们通过大量的标注数据进行训练,模型从中学习词汇、语法、句子结构以及上下文关系。具体来说,模型根据输入预测下一个词,目标是最大化模型生成文本与真实文本之间的相似度。这种方法通常只依赖于历史数据,而不涉及到任何反馈循环。
-
强化学习大语言模型(RL-LM): 强化学习的语言模型在基础的语言模型之上,加入了强化学习过程。该过程通过与环境互动,获得反馈(通常是奖励信号)来优化模型的行为。强化学习训练的关键步骤包括:
-
初始模型生成:首先,模型通过传统的监督学习训练,获得基本的语言生成能力。
-
互动与反馈:在强化学习阶段,模型会与环境(通常是用户、任务或模拟环境)进行交互,每个生成的响应都会得到一个反馈。这个反馈可以是来自人工的评价(如用户打分)或由自动化系统生成的奖励信号。例如,如果模型的输出符合某些预期目标,就会给出正向奖励,否则给出负向奖励。
-
策略优化:模型根据反馈信号调整自己的策略(即生成文本的方式),通过多次试探和调整,使得模型逐渐学会如何生成更符合目标(如更有帮助、更安全、更有效等)的文本。
-
RLHF(Reinforcement Learning from Human Feedback):一种常见的方式是从人类反馈中学习强化学习(RLHF),即通过人类对模型输出的评价(如选择更好的答案、标注有害内容等)作为奖励信号,来优化模型的行为。
-
强化学习语言模型与普通大语言模型的区别:
-
训练方式的不同:
- 普通LLMs 主要依赖于监督学习,通过大量标注数据的对比学习来优化模型的参数。这些模型的输出仅仅根据先前的训练数据进行预测,没有额外的反馈机制。
- RL-LM 则使用强化学习,不仅仅依赖于预先标注的数据,还通过不断的交互与反馈信号来调整模型。它可以通过奖励机制来持续优化模型的生成行为。
-
反馈回路的引入:
- 普通LLMs的学习过程是静态的,一旦训练完成,模型的行为不会改变。
- RL-LM通过引入反馈机制,模型能够在交互过程中持续学习和改进。模型生成的输出会影响接下来如何优化模型,这意味着它能够在任务中表现得越来越好。
-
目标优化不同:
- 普通LLMs的目标是最大化训练数据中预测的准确性,主要关注的是语言的流畅性和语法正确性。
- RL-LM的目标是通过奖励信号来优化行为,因此除了生成语言之外,还可以针对特定任务进行优化,比如生成更有帮助的回答、更符合安全标准的内容或避免产生有害输出。
-
应用场景的不同:
- 普通LLMs更适合一般性的语言任务,比如翻译、文本生成等。
- RL-LM则更适合需要持续优化和调整的任务,比如对话系统、智能助理或其他需要与用户持续互动的应用,因为它可以根据用户反馈不断改进。
总结:
强化学习的大语言模型通过反馈机制(尤其是人类反馈)对其生成的文本进行优化,使其能够在特定任务中表现得更好。而普通的大语言模型则依赖静态数据进行训练,不具备根据反馈进行动态调整的能力。因此,强化学习的大语言模型通常更具灵活性,能够更好地适应复杂的任务和动态环境。
这是gpt给出的答复。可以看到,这种大语言模型一开始也是常规训练。进入强化学习阶段后,模型可以获取人类的评价(也就是奖励)来更新自己。假如有一类答复模式容易得到奖励,模型之后就会倾向于这样回答。
那模型具体是怎么向着“得到更多奖励的方向”发展的呢?:
虽然大语言模型的初始训练阶段没有使用强化学习,但它们可以结合人类反馈强化学习(RLHF, Reinforcement Learning from Human Feedback) 来进一步优化生成的质量和对用户偏好的匹配。RLHF 是通过将强化学习应用到语言模型的生成上,帮助模型更好地符合人类的偏好。这种训练方式引入了策略、值函数等强化学习中的概念。
在 RLHF 框架中,流程大致如下:
-
监督预训练(Supervised Pretraining): 这是大语言模型最初的训练方式,即通过大规模标注数据来学习上下文和输出之间的关系。
-
奖励模型(Reward Model): 接着,引入人类反馈。通常人类会对模型生成的多个候选文本进行打分,形成一个用于区分“好的”输出和“不好的”输出的奖励模型。这个奖励模型会为不同的文本生成提供评分,即为模型的行为提供奖励信号。
-
强化学习策略更新: 在得到奖励模型后,可以使用强化学习的方法来优化语言模型的生成。这个过程类似于传统的强化学习场景,即模型通过调整生成策略,使得生成的文本能够最大化奖励模型提供的奖励。
在这个过程中,策略 和 值函数 概念可以被引入:
-
策略:在 RLHF 中,策略是指模型在生成文本时,如何在每一步选择词汇。策略可以理解为一个在某个给定上下文状态下生成词的分布 π(a∣s)\pi(a | s)π(a∣s),这里的状态 sss 是当前的上下文,行动 aaa 是接下来生成的词。
-
值函数:类似于强化学习中的值函数,值函数 V(s)V(s)V(s) 可以用于估计在给定上下文状态下生成某个序列的期望奖励。换句话说,值函数估计模型从当前状态生成文本后,未来可能获得的累积奖励。
3. 使用强化学习(RLHF)进行策略更新
在RLHF中,使用强化学习算法来调整语言模型的参数,使得它的输出更加符合奖励模型的评价。一个典型的强化学习算法是PPO(Proximal Policy Optimization),它广泛用于大语言模型的策略优化。
具体来说:
-
策略更新:PPO 会根据奖励模型提供的奖励信息,来更新语言模型的策略。策略不再是通过预测下一个词的对数似然来进行训练,而是通过奖励模型的反馈,调整生成词序列的概率分布。
-
策略梯度:语言模型在强化学习阶段的目标是通过策略梯度方法来调整参数。策略梯度的目标函数类似于传统强化学习,模型根据经验和人类反馈,调整参数以最大化期望的奖励。
PPO 的目标函数如下:
LCLIP(θ)=E^t[min(πθ(at∣st)πθold(at∣st)A^t,clip(πθ(at∣st)πθold(at∣st),1−ϵ,1+ϵ)A^t)]L^{CLIP}(\theta) = \hat{\mathbb{E}}_t \left[ \min\left( \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)} \hat{A}_t, \text{clip}\left( \frac{\pi_{\theta}(a_t | s_t)}{\pi_{\theta_{\text{old}}}(a_t | s_t)}, 1 - \epsilon, 1 + \epsilon \right) \hat{A}_t \right) \right]LCLIP(θ)=E^t[min(πθold(at∣st)πθ(at∣st)A^t,clip(πθold(at∣st)πθ(at∣st),1−ϵ,1+ϵ)A^t)]其中,πθ\pi_{\theta}πθ 是策略(即生成词的分布),AtA_tAt 是优势函数(表示某个行动比平均行动好多少)。
在这个优化过程中,语言模型的策略即根据上下文生成下一个词的方式被调整,以期生成的文本符合奖励模型的标准。
4. 为什么语言模型会涉及策略和值函数?
-
生成的序列结构:大语言模型生成文本的过程类似于一个马尔可夫决策过程(MDP),其中:
- 状态:当前生成的上下文或已生成的文本部分。
- 行动:模型选择的下一个词。
- 策略:模型基于当前状态选择下一个词的概率分布。
- 奖励:人类反馈或奖励模型为整个生成序列提供的评分。
-
策略更新目标:通过引入强化学习中的概念,如策略梯度、值函数,模型的目标不再是简单的生成训练集中的下一个词,而是生成能够得到更高人类评分的句子序列。这让模型的策略(即生成文本的方式)能够持续优化,符合用户或人类评估的预期。
-
长期奖励和序列生成:由于文本生成是一个多步决策过程,生成一段高质量的文本依赖于多个词的合理选择。使用值函数可以估计在某一时刻生成特定词汇后,未来继续生成文本的累积奖励。强化学习中的值函数和策略更新有助于在长序列生成中避免模型做出次优的决策。
总结
虽然大语言模型在基础训练时并没有直接使用强化学习中的策略或值函数的概念,但在引入**人类反馈强化学习(RLHF)**后,它们会使用强化学习的工具来优化生成的策略。在这种框架下,模型会根据奖励模型的反馈,通过值函数或策略更新调整生成机制,从而生成更加符合用户偏好的文本。因此,在这种情况下,大语言模型确实会使用到强化学习中的策略和值函数。
以上是gpt的回答。是不是可以这样理解:传统的大语言模型训练的时候,“标准答案”是数据集里下一个token是什么,而在强化学习的大语言模型里,“标准答案”是奖励模型给出的奖励最高的token。这让大语言模型从简单的“模仿数据”转向更注重生成“对用户更有用”或“更符合人类期望”的内容。
但是这时候我又想到一个问题:既然LLM也只是把奖励模型当成标准答案来训练,为啥不直接用奖励模型来生成文本?:
为什么不能只用奖励模型?
-
奖励模型不能生成词序列:奖励模型本质上是一个评估器,它只能根据给定的文本打分,无法根据上下文生成下一个词。如果你直接尝试使用奖励模型来生成文本,它根本没有能力从一个状态(当前生成的文本)推测或生成新的内容。生成任务仍然是 LLM 的工作。
-
奖励模型的评分机制有限:奖励模型的评分机制需要输入完整的序列才能有效打分,通常它只在已有文本上打分,而无法推断下一个最好的词是什么。奖励模型并没有上下文理解和生成语言的机制。
-
生成过程需要多样性:文本生成通常是一个多样性的过程,不能简单地依赖每次都选取打分最高的词。语言生成需要平衡内容的连贯性、自然性和创造性。如果你每次都生成奖励最高的词,结果可能会导致不自然、重复或者无意义的文本。
这样我们也可以大概知道,刚才的总结其实不尽准确。准确来讲奖励模型其实不能给出某个token的奖励是多少,他只能对一个序列进行评分。
引入奖励模型:人类反馈的强化学习阶段
在 RLHF 阶段,加入了奖励模型(Reward Model) 来帮助 LLM 生成更符合人类期望的文本。这个奖励模型根据人类反馈(如人类对生成文本的偏好或质量打分)来进行训练,能够为生成的文本打分。
- 奖励模型的输入:奖励模型接受 LLM 生成的完整文本作为输入。
- 奖励模型的输出:奖励模型输出一个奖励值 r,表示这段文本在某种标准(如符合性、流畅度、自然性)下的评分。
3. 强化学习中的 LLM 更新策略:使用奖励模型反馈调整参数
在强化学习阶段,大语言模型会根据奖励模型的反馈来调整其生成策略。这是通过强化学习中的策略梯度方法(如PPO)来实现的。
让我们详细解析这一过程:
a. 生成候选文本序列
在训练过程中,LLM会基于当前策略 πθ\pi_\thetaπθ 生成一些文本序列。这些文本序列是模型的生成结果(类似于随机采样),在某个给定的上下文 xxx 下,模型会生成多个候选的文本序列。每个序列都会有一个词汇生成的轨迹。
对于每个时刻 ttt,LLM 的生成策略是选择下一个词的概率分布:
πθ(at∣st)\pi_\theta(a_t | s_t)πθ(at∣st)
其中,sts_tst 是当前上下文状态,ata_tat 是生成的词(行动)。
b. 奖励模型给文本打分
奖励模型对 LLM 生成的每个完整文本序列给出一个奖励值 rrr。这个奖励值衡量整个序列的质量,但它并不能直接提供每一步具体生成词汇的反馈。
c. 回传奖励信号:优化整个生成过程
虽然奖励模型的评分是针对整个序列的,但 LLM 需要通过强化学习中的策略梯度方法,回溯整个生成过程来更新每个步骤的生成策略。这里引入了强化学习中的优势函数(Advantage Function) 和策略梯度来指导 LLM 如何调整参数。
策略梯度更新公式如下:
∇θJ(θ)=Eπθ[∇θlogπθ(at∣st)At]\nabla_{\theta} J(\theta) = \mathbb{E}_{\pi_{\theta}} \left[ \nabla_{\theta} \log \pi_{\theta}(a_t | s_t) A_t \right]∇θJ(θ)=Eπθ[∇θlogπθ(at∣st)At]
其中,AtA_tAt 是优势函数,表示在状态 sts_tst 选择行动 ata_tat 后,相对于平均策略的表现(也就是该词汇的生成好坏)。
- 如果优势函数 AtA_tAt 为正,意味着该步骤生成的词是好的,模型会增加它的概率。
- 如果优势函数 AtA_tAt 为负,意味着该步骤生成的词不理想,模型会减少它的概率。
可以看到最后这两句话就是解答困惑的核心了。首先让LLM正常输出文本,把结果分成一块一块交给奖励模型。奖励模型就会给评分啊,我们可以给评分算一个平均值,以此为标准看看哪些输出好,哪些坏。如果评分高于平均,那么LLM在这个阶段生成的token是比较好的,生成这些token(当然是在当前的状态下,就是上下文那些,和普通的LLM一样的)概率上升(就好像是把这些文本当成数据集里的“标准答案”来训练了一样),如果评分低于平均值,那么这些词就不好,LLM生成这些词的概率下降。
有了奖励模型,我们连数据集都不需要了,让模型自娱自乐就可以进行训练了,而且连起来还很有针对性,很符合用户要求,真是绝了。
以上是常规强化学习的介绍。这些强化学习有一个共同特点,那就是需要一个显示的奖励函数。能不能不要这个?能,那就是Direct Preference Optimization (DPO) 算法。:
Direct Preference Optimization (DPO) 是一种近年来引入的算法,尤其在强化学习领域中,用于解决从偏好反馈中直接进行学习的问题。与传统强化学习算法不同,DPO 不需要构建显式的奖励函数,而是直接通过人类偏好或其他形式的反馈来优化策略。这使得 DPO 特别适用于某些情境中难以明确定义或获取奖励信号的问题,例如对话系统的生成、推荐系统以及其他基于复杂用户偏好的任务。
DPO 的核心思想
-
偏好学习:DPO 主要依赖于偏好数据集,这些数据集通常是由用户或专家标注的成对偏好反馈,即给定两种行为或策略的输出,用户选择其中一个更符合其期望的结果。这个反馈形式直接用于指导模型的优化。
-
策略学习:与传统的策略梯度算法不同,DPO 不需要先构建一个回报函数,而是通过对比策略输出和人类的偏好反馈来更新策略。通过最大化偏好反馈中选择的行为的概率,DPO 能够引导模型朝向更符合用户偏好的方向优化。
-
直接优化:DPO 在优化时直接基于人类偏好反馈进行,不需要将反馈转化为奖励函数。相比于从反馈构建奖励函数再进行策略优化,DPO 能够减少潜在的偏差和噪音,因为它跳过了明确的奖励设计这一环节。
DPO 算法的主要步骤
-
数据收集:从环境中生成不同的行为样本,并基于这些行为样本获得人类偏好反馈。通常,偏好是成对的,即给定两个行为样本,用户或专家对其进行选择,指出哪个行为更优。
-
策略更新:在每一轮迭代中,通过最大化模型生成的行为与用户偏好一致的概率,直接对策略进行更新。更新过程中通常会用到交叉熵损失或 KL 散度,以更有效地对比两种行为样本。
-
采样与优化:通过策略的改进,模型能生成越来越符合偏好的行为,并逐步迭代,朝向最终的最优策略收敛。
DPO 相对于传统 RLHF(Reinforcement Learning from Human Feedback)的优势
-
不依赖显式奖励信号:在许多现实任务中,设计奖励函数非常困难或容易引入偏差。比如说PPO,需要通过人类反馈然后训练奖励模型。DPO 直接利用偏好数据进行优化,绕过了奖励函数设计。
-
更直接的反馈机制:DPO 直接将人类的偏好反馈应用于策略学习,而不是将其转换成间接的奖励信号,从而可能减少信息丢失或噪声。
-
简化的训练过程:相比于通过构建奖励模型再进行策略优化的 RLHF,DPO 只需通过偏好反馈对策略进行直接优化,训练流程更加直接。
DPO 的应用领域
DPO 尤其适合需要根据复杂的人类偏好进行优化的任务,例如:
- 对话系统:让对话 AI 生成符合用户期望的回答,而不需要通过复杂的奖励函数来衡量回答的质量。
- 推荐系统:根据用户的偏好直接优化推荐模型,而无需为每一个用户行为设计奖励。
- 生成模型:在图像、文本生成等任务中,基于用户的选择反馈,直接优化生成的结果。
举一个例子
我们可以通过一个训练 Web Agent 的例子来具体讲解 Direct Preference Optimization (DPO) 算法的工作原理和步骤。
设定情境
假设我们在训练一个 Web Agent,这个智能体的目标是帮助用户完成各种网页上的任务,比如查找信息、进行购物或预订机票。智能体需要学习如何在不同的网页上采取一系列动作(如点击、输入、滚动等),以满足用户的需求。
通常情况下,训练这样的 Web Agent 可能需要设计一个复杂的奖励函数,来判断智能体每次执行的动作是否朝着完成任务的方向前进。但是定义一个准确的奖励函数非常困难,因为有许多潜在的、细微的用户偏好是无法直接量化的。这时,DPO 就能派上用场。
DPO 的工作流程
-
数据收集(偏好反馈)
首先,智能体会生成多个关于执行任务的行为序列。每个行为序列代表智能体在网页上的一系列操作(例如点击按钮、填表、滚动页面等)。接着,我们通过人工的方式收集成对的偏好数据,即展示给用户两条不同的行为序列,询问他们哪一个行为序列更符合他们的需求或更高效。
举例:
- 行为序列 A:智能体在网页上先滚动再点击 "下一页" 按钮。
- 行为序列 B:智能体直接点击 "搜索" 按钮。
用户可能会根据任务的具体目标,比如是否需要看完整的内容,选择其中一个序列。假设用户更喜欢行为序列 B,因为它直接解决了任务,用户反馈这条行为序列更优。
-
构建偏好数据集
收集足够多的偏好反馈后,构建一个偏好数据集。这种数据通常呈现为成对的行为序列和相应的偏好选择:
- (行为序列 A, 行为序列 B, 用户选择 B)
- (行为序列 C, 行为序列 D, 用户选择 D)
- ...
-
策略模型的初始化
然后,我们初始化一个策略模型 πθ\pi_{\theta}πθ,用来表示智能体在每个网页状态下选择动作的概率分布。这个模型的参数是 θ\thetaθ,它决定了智能体如何在不同的网页上做出决策。
-
偏好优化(基于反馈进行策略更新)
DPO 的核心思想是通过用户偏好直接优化策略,而不是设计奖励函数。具体来说,DPO 要求最大化策略生成的行为序列与用户选择的行为序列相一致的概率。这个优化可以通过以下几个步骤来完成:
-
概率计算:对于每一对行为序列 (A,B)(A, B)(A,B),模型分别计算生成行为序列 AAA 和 BBB 的概率 πθ(A)\pi_{\theta}(A)πθ(A) 和 πθ(B)\pi_{\theta}(B)πθ(B)。
-
损失函数:DPO 使用交叉熵损失或 KL 散度来优化偏好。比如,如果用户偏好行为序列 BBB,那么损失函数将 penalize 生成 AAA 的概率,并鼓励生成 BBB 的概率。我们可以使用如下的目标函数:
L(θ)=−logπθ(B)πθ(A)+πθ(B)L(\theta) = -\log \frac{\pi_{\theta}(B)}{\pi_{\theta}(A) + \pi_{\theta}(B)}L(θ)=−logπθ(A)+πθ(B)πθ(B)这个损失函数的直观解释是:当用户选择 BBB 时,我们希望模型倾向于更频繁地生成 BBB,并减少生成 AAA 的概率。
-
策略更新:通过反向传播和梯度下降等优化算法来最小化这个损失函数,更新策略模型的参数 θ\thetaθ。这样,随着训练的进行,智能体会逐步偏向生成更符合用户偏好的行为序列。
-
-
行为序列采样与策略改进
随着模型不断更新,智能体将能够生成越来越符合用户偏好的行为序列。每一次策略更新后,智能体会基于更新后的策略再生成新的行为序列,然后这些序列将被用来继续收集用户偏好数据。
Web Agent 例子中的 DPO 细节
在训练 Web Agent 时,DPO 的具体应用流程如下:
-
行为采样:Web Agent 会根据当前策略在不同网页上执行一系列操作,生成多个行为序列。每个序列可能包含点击某个链接、输入文本、滚动页面等动作。
-
收集偏好反馈:用户或专家基于这些行为序列提供偏好反馈,指出哪一个序列更接近理想的操作。这些反馈将形成成对的偏好数据集。
-
优化策略:通过优化算法,调整智能体策略,使其在相似的环境下更倾向于执行那些更符合用户偏好的操作序列。
-
迭代训练:智能体不断生成行为序列,收集新的偏好数据,逐步改进其策略,以应对更加复杂的任务和环境。
优势
- 避免显式奖励设计:DPO 直接通过偏好反馈进行学习,不需要手动设计复杂的奖励函数。
- 偏好一致性:通过最大化用户选择行为的概率,智能体能够更加高效地适应用户的需求。
- 减少噪声:相比于通过用户反馈构建奖励模型再进行优化,DPO 的直接偏好优化能够减少一些中间步骤带来的噪声和偏差。

本文的模型只使用过去的动作和当前的页面作为状态,不记录之前的状态。
使用强化学习的大语言模型,可能会想到PPO。但是这样子会需要大量的线上样本(人工打分之类的)有解决这一问题的方法Q-transformer,但是也不好。本文直接用DPO。
POMDP是什么?是部分可观察的马尔卡弗决策过程。

模型每次生成动作的时候会生成好几个,然后会有另一个模型打分排名。:
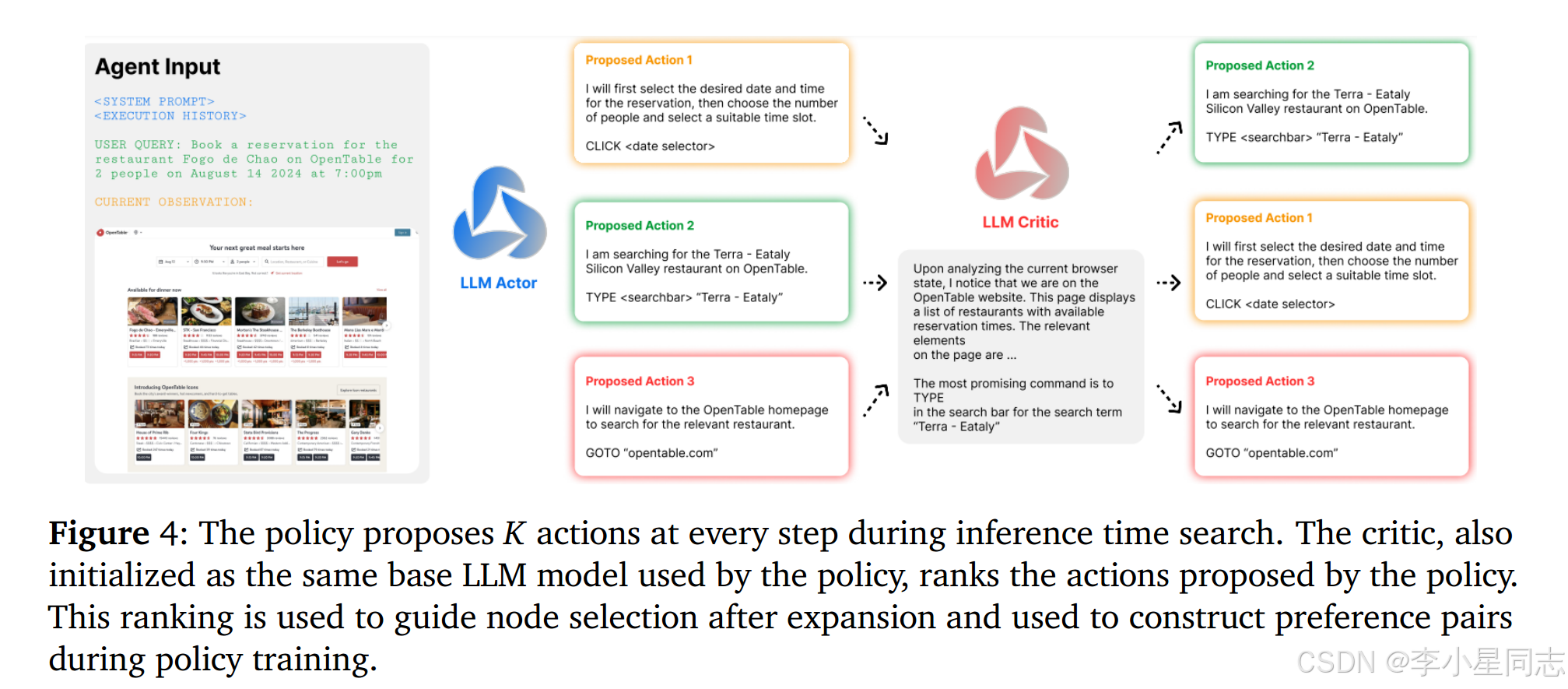
通过这种方式一直探索,直到叶子节点。这个时候看结果,如果成功了就是1,不成功就是0.把结果奖励反向传播给前面的节点与动作。每个节点都会记录自己这个节点+动作对的价值与自己这个节点被访问的次数.
总体流程是这样:首先只使用正确的轨迹,使用DPO的方法训练模型。这样可使模型性能上升,但还不够。
于是使用蒙特卡洛树。在其他ai的帮助下对生成的多个行动进行排名,探索。有可能会得到错误的结果,但是失败也是经验,模型以后这么做的概率就会降低。成功了,模型以后这么做的概率就上升。这样成功也学,失败也学,模型性能大幅上升。
但是在下一个任务opentable中,难度又上升了,于是文章有使用了RFT。
RFT是指无奖励探索,先检测环境,状态是如何变化的。这部分也可以对模型进行训练,相当于只是让模型知道这些页面是怎么跳转的,不让他纠结任务目标是什么。
除了用蒙特卡洛树来指导模型训练外,这个算法也可以在做推理的时候使用,也可以大幅提高模型的效果,因为可以进行额外的探索。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









