






自动化产生轨迹数据的方法!可恶啊,我还以为我的工作可以成为第一个自动化产生轨迹的方法呢。不过它的思路和我的不一样,它用的是我最开始的时候尝试过的思路,但是因为轨迹数据质量太差被我放弃了。这个论文貌似是设计了一个奖励函数,可以判定一个轨迹数据是否高质量,从而筛选出合适的轨迹。
•通过从任务驱动的方法转向交互驱动的GUI代理数据构建,我们引入了反向任务合成来提高轨迹质量和多样性。
•我们提出了一种新的管道,OS Genesis,能够有效地合成高质量的轨迹数据。无需人工监督,OS Genesis支持跨环境的GUI代理端到端培训。
•在动态基准上对移动和web任务进行的广泛实验表明,OS Genesis的性能优于一系列强大的基线。
我的方法是任务驱动的。它用的是task goal generation的思路,只是更加完善,会先生成单步思考,然后再总结整个轨迹的任务,获得这些任务之后将high level的任务交给gpt4o去做(what?前面这么多工作都是用来生成任务的?)然后用reward函数(其实也是gpt4o)去筛选合适的轨迹。
它一开始就和droidbot一样,随便乱点,乱划。需要打字的内容就交给gpt4o,然他生成适合当前情况的输入内容。
做实验的时候都是接受了a11y tree和截图的。
实验的时候它简直是跳脸嘲讽!实验分几种情况:没训练过的,用任务驱动方式获取的轨迹来训练的(不就是我的方法吗?就是少了一个自动产生新任务而已),用self-instruct方法获取更多任务的(我之前还讲过self-instruct这篇论文,就是用种子任务产生新任务然后筛选的那个)最后再用自己这一套方案产生的数据集训练的模型,和前面几种方法去比较。它应该是想要说自己的产生新任务的方法更好,后续的筛选也让轨迹质量更高了。但它成本也高啊,又是生成小任务,集合大任务,最后还要再执行一遍。我生成新任务几乎无成本。
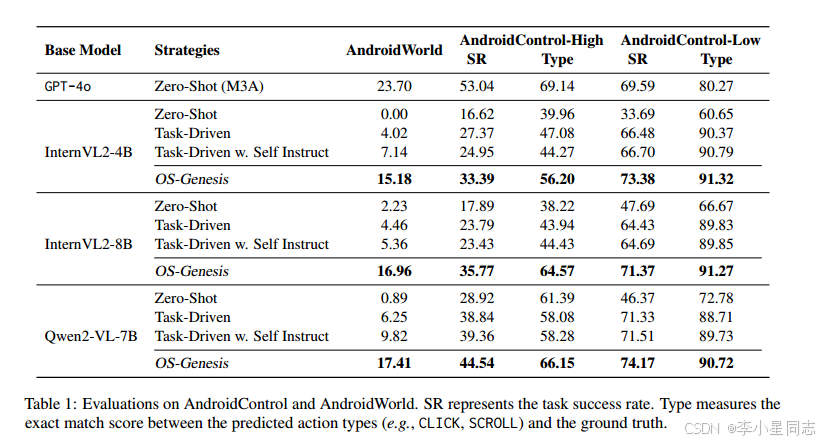
在训练细节方法,它和我一样是有训练cot和action。公平起见,大家都只是用1k条轨迹来训练(不过self-instruct是用的1.5k)。除了这些开源模型以外,它还用了gpt4o来测试,以证明自己的方法使得这些开源模型和闭源模型的差距减小。
文章表示他们的任务生成方法可以生成更加多样性的任务,可以覆盖app的各种功能,故而生成任务的质量更高。文章还使用sentence bert计算各个任务描述的余弦距离,证明平均距离大,任务多样性也高。同时文章还发现人类写出来的任务语义差别大,但轨迹区别小。本文的方法就没有这个问题。
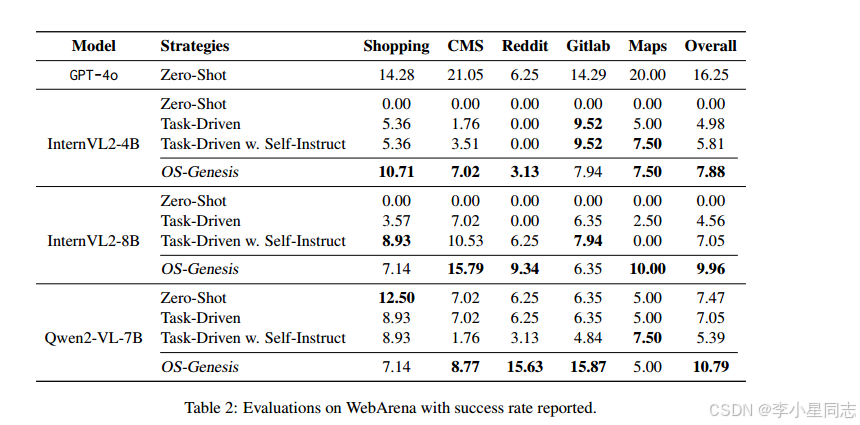
文章随后还发现数据集过大之后模型的能力会饱和。太大提升效果就不明显了。
仔细想想这篇工作也是有缺点的:过多依赖gpt4o等闭源模型,因为开源模型能力不够。但是我有mcts啊,我可以手动提高开源模型的能力,不带一点害怕的。但是生成新任务的方法,是这篇文章更厉害。就算加上后续的任务池大更新,应该也是这篇文章的方法更强。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









