









一、pprof 概述
pprof 是用于可视化和分析性能分析数据的工具。但凡是Gopher应该都听过pprof的大名,内存泄漏找它,性能瓶颈找它,查看火焰图找它等等…
本文会介绍基础的pprof使用以及性能分析和优化实例。从实际的例子出发去使用和认识pprof。
如果对trace分析有兴趣,可以查看Golang的trace性能分析
二、服务开启pprof
pprof的使用方式有两种,一种是需要在代码中调用特定API去采集并写入到文件的方式,使用的包是:
runtime/pprof
参考:你不知道的 Go 之 pprof
https://darjun.github.io/2021/06/09/youdontknowgo/pprof/
一种是基于http服务的采集,使用的包是:
net/http/pprof
我们本次就是基于http服务来使用pprof。
1、代码中引用pprof
1、代码中引用pprof
_ "net/http/pprof"
2、服务开启一个端口,用来监听pprof
// Start a HTTP server to expose pprof data
pprofAddr := "0.0.0.0:6060"
go func(addr string) {
if err := http.ListenAndServe(addr, nil); err != http.ErrServerClosed {
logger.Fatalf("Pprof server ListenAndServe: %v", err)
}
}(pprofAddr)
logger.Infof("HTTP Pprof start at %s", pprofAddr)
3、浏览器查看
http://服务ip:6060/debug/pprof
2、服务开启一个端口,用来监听pprof
// Start a HTTP server to expose pprof data
pprofAddr := "0.0.0.0:6060"
go func(addr string) {
if err := http.ListenAndServe(addr, nil); err != http.ErrServerClosed {
logger.Fatalf("Pprof server ListenAndServe: %v", err)
}
}(pprofAddr)
logger.Infof("HTTP Pprof start at %s", pprofAddr)
3、浏览器查看
http://服务ip:6060/debug/pprof
web界面如下

三、使用pprof采集CPU耗时
(1) 引入Pprof
(2) 监听6060端口
(3) 采样,例如采样cpu,采样30s
http://10.91.2.111:6060/debug/pprof/profile?seconds=30&sample_index=0&top=20
参数结束:
seconds: 采集30s
top: 采集耗时前20的程序
在30s内访问接口即可。30s后会下载文件到本地
(4) 分析生成的profile文件:本地开启8080端口,通过浏览器查看分析
go tool pprof -http=localhost:8080 profile(文件名)
(5) Could not execute dot; may need to install graphviz.
安装图像处理工具:
brew cleanup
brew update
brew install graphviz
1、调用流程图

主要指标,查看各个调用的耗时占比,以及调用链路的整体耗时。
2、查看火焰图
点击左上角的view,选择flame graph即可

主要指标
1、火焰图的格子越宽,代表耗时越久
2、火焰图的高度越高代表调用链路越长。
追求:宽度适中,高度适中。优化格子过宽的,或者预期之外耗时较久的。
四、使用pprof分析内存泄漏问题
查看当前程序的内存占用
1、执行命令
go tool pprof -inuse_space http://127.0.0.1:6060/debug/pprof/heap
2、进入命令行
top: 查看当前占用内存的函数排行
list 函数名: 查看内存占用的函数内部代码
top示例如下:
Type: inuse_space
Time: Jun 16, 2023 at 3:29pm (CST)
Entering interactive mode (type "help" for commands, "o" for options)
(pprof) top
Showing nodes accounting for 2706.84kB, 100% of 2706.84kB total
Showing top 10 nodes out of 32
flat flat% sum% cum cum%
650.62kB 24.04% 24.04% 650.62kB 24.04% github.com/valyala/fasthttp/stackless.NewFunc
515kB 19.03% 43.06% 515kB 19.03% vendor/golang.org/x/net/http2/hpack.init
514.63kB 19.01% 62.07% 514.63kB 19.01% math/rand.newSource (inline)
514.38kB 19.00% 81.08% 514.38kB 19.00% google.golang.org/protobuf/reflect/protoregistry.(*Types).register
512.20kB 18.92% 100% 512.20kB 18.92% runtime.malg
0 0% 100% 514.63kB 19.01% github.com/nacos-group/nacos-sdk-go/v2/clients.NewConfigClient
0 0% 100% 514.63kB 19.01% github.com/nacos-group/nacos-sdk-go/v2/clients/config_client.NewConfigClient
0 0% 100% 514.63kB 19.01% github.com/nacos-group/nacos-sdk-go/v2/clients/config_client.NewConfigProxy
0 0% 100% 514.63kB 19.01% github.com/nacos-group/nacos-sdk-go/v2/common/nacos_server.NewNacosServer
0 0% 100% 514.63kB 19.01% github.com/spf13/cobra.(*Command).Execute
3、通过查看当前服务的内存占用,可以分析内存泄漏等
查看goroutine的运行时间
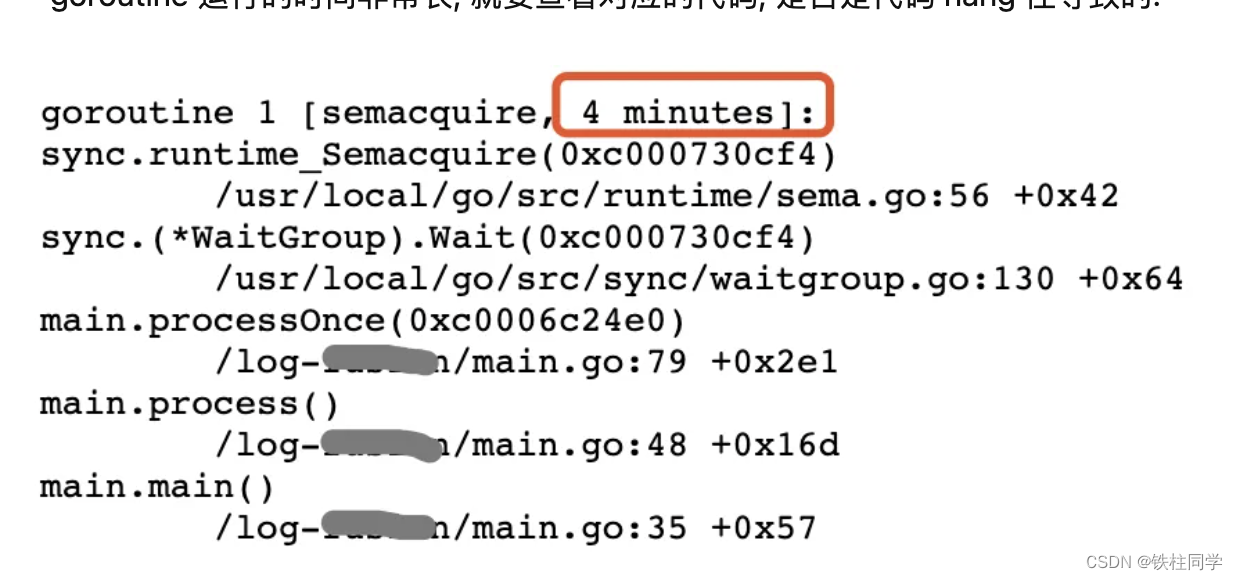
看到长时间运行的goroutine就需要小心了,如果是非系统的goroutine,有可能是业务上的goroutine一直没释放,这也是内存泄漏的来源之一。
五、性能优化案例
背景
Go服务进行批量查询的时候,由于返回的数据中包含大量的OSS签名数据,导致实际的QPS很低,且延时比较高,因此决定针对这个接口做性能分析及优化。
查询的大致流程是:
1、参数校验
2、从数据库批量查询
3、OSS签名,处理数据
4、json序列化返回
流程很简单,就是普通的查询接口,但是当查询的数量比较多的时候,比如查询30多条记录,QPS表现实在是不尽如人意。压测结果如下:

本次性能分析及优化暂时不涉及到数据库缓存,由于时间原因,只做除数据库外的其他优化。
1、压测工具介绍
go-wrk
go-wrk 是一个用于测试 Go 语言网络服务器性能的命令行工具。它基于 Go 的标准库 net/http 包,使用 goroutine 实现了高并发请求。
go-wrk [flags] url:启动测试,并指定要测试的 URL。
-c value:指定并发数。默认为 50。
-d value: 压测时间,单位是秒
-t value:指定请求超时时间。默认为 20 秒。
-H "header:value":设置 HTTP 请求头。
-v:显示详细输出。
-m: 设置 HTTP 请求方法,例如 GET, POST, PUT, DELETE 等常用的请求方法。
例如:
go-wrk -c 100 -d 30 -T 2000 -H "Content-Type: application/json, Authorization: Bearer token" \n
http://localhost:8080/test -m POST -body '{"name":"bob","age":30}'
返回:
15841 requests in 38.848392606s, 117.13MB read
Requests/sec: 407.76
Transfer/sec: 3.01MB
Avg Req Time: 2.452395215s
Fastest Request: 66.236651ms
Slowest Request: 19.945042378s
Number of Errors: 232
适合本地使用,安装方便。主要关注的参数是请求数。
jmeter
jmeter是一款开源的、用于功能测试和性能测试的Java应用程序。安装的时候需要界面来配置自动化场景,目前是使用meterSphere中自带的jmeter,主要关注TPS指标。
本来想在Linux下安装个命令行压测一下,实测结果是安装复杂,但是功能很全面。公司测试使用的是jmeter,那我们后续的压测都以jmeter的结果为准
2、pprof分析火焰图
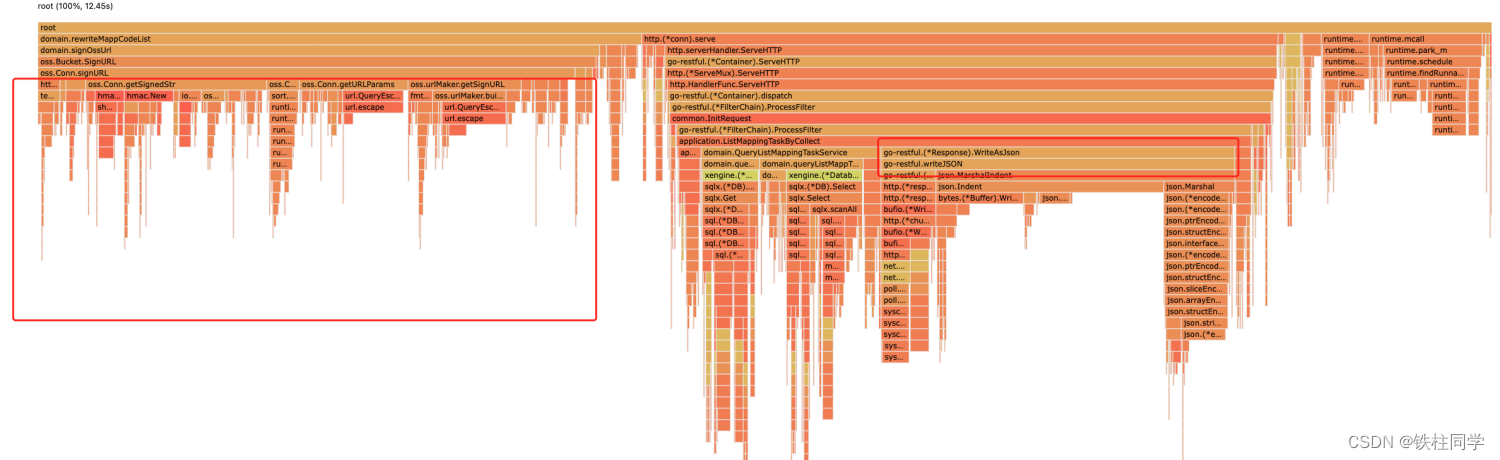
主要问题如下
oss签名占比将近40%
GC耗时比较高,占比>10%
go-restful写入response占比>20%,本质上是json序列化
3、第一波优化
OSS签名
由于签名设置过期时间为1个小时,且写入OSS的数据不频繁更新,因此可以考虑加缓存。
这里使用轻量级go-cache。OSS签名缓存并不需要考虑分布式缓存,go-cache足够了。
go get github.com/patrickmn/go-cache
var c = cache.New(50*time.Minute, 10*time.Minute) //设置过期队列
c.Set("key", value, cache.DefaultExpiration) // 写入缓存
cachedValue, found := c.Get("key") // 读出缓存
json序列化优化
原生json库使用反射,性能上可能差点,我们使用高性能的json-iterator/go库来进行json序列化。
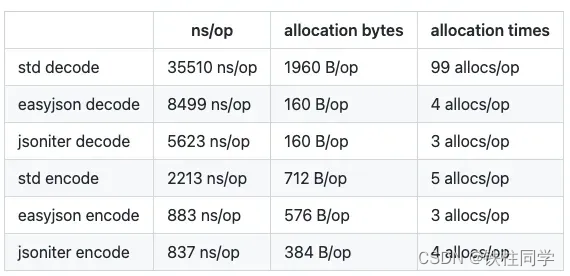
// 使用很简单,安装之后开箱即用
var fastJson = jsoniter.ConfigFastest
jsonData, _ := fastJson.Marshal(data)
优化之后的效果
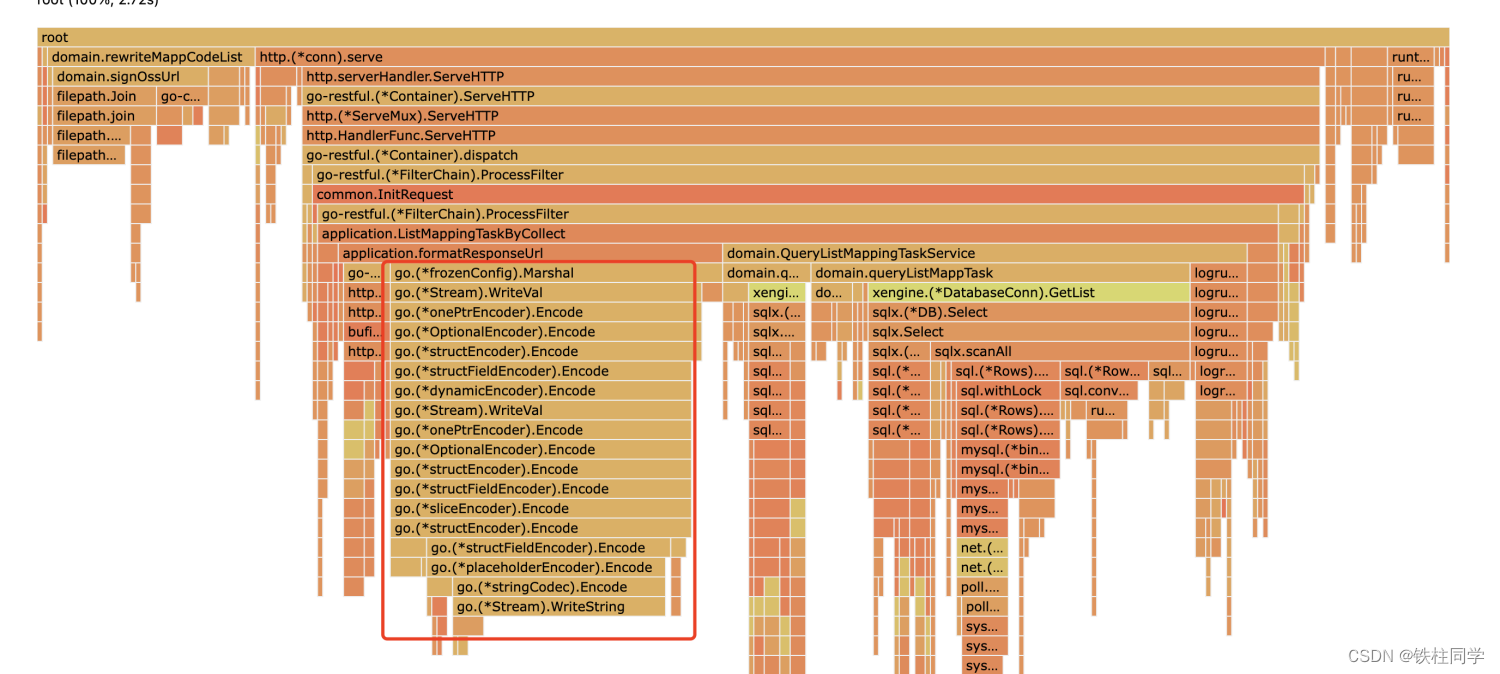
1、oss签名占比<1%
2、批量查询sql耗时较多,主要集中在scanAll部分,这部分的耗时跟数据库查询字段的多少有关
3、json序列化耗时较多,但比之前的原声json要好一些
第二波优化
优化点
1、减少json解析字段,按需返回。
2、sql优化,返回字段缩减。
3、由于不分页,因此可以减少count查询的sql
优化效果
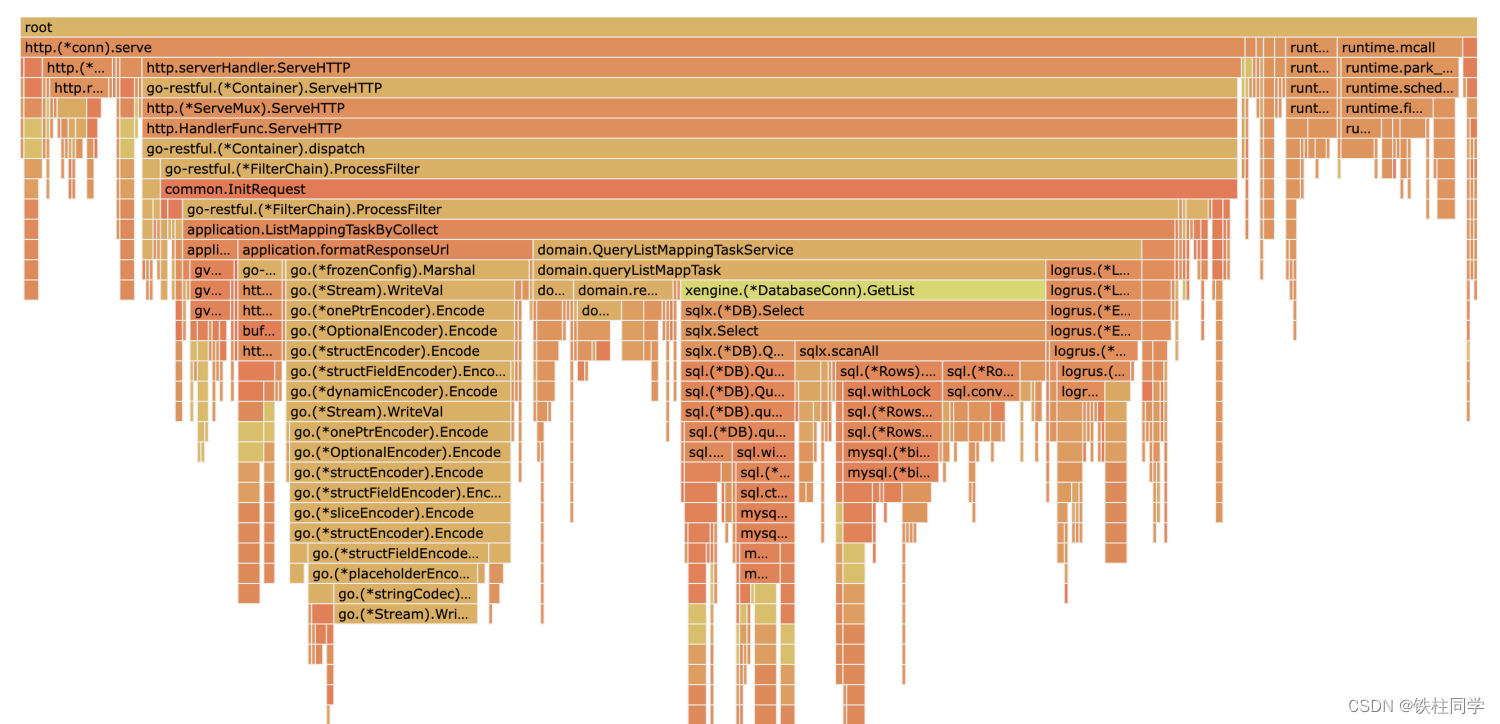
存在的问题
1、数据库占用37%
2、json耗时从27%下降到17%
3、gc占用过多,4G内存,只能用到100M就GC了
4、日志打印耗时10%
5、gvalid校验参数耗时占比6.6%
第三波优化
优化sql,增大连接池
unsafeDb.SetMaxOpenConns(200) // 设置最大连接数为 200
unsafeDb.SetMaxIdleConns(10) // 设置最大空闲连接数为 10
优化json编码器
// 原来先解析成[]byte,后赋值给resp
// 新增了变量且多了赋值操作
jsonData, _ := fastJson.Marshal(common.SuccessRESTResp(data))
resp.Header().Set(restful.HEADER_ContentType, "application/json")
resp.WriteHeader(200)
resp.Write(jsonData)
// 直接把go-restful的resp *restful.Response 作为参数
// 编码器会直接把编码结果写入到resp,省去了原来的拷贝赋值
enc := fastJson.NewEncoder(resp)
enc.Encode(common.SuccessRESTResp(data))
实测json序列化效果并没有提升。
json.Marshal

使用json.NewEncoder
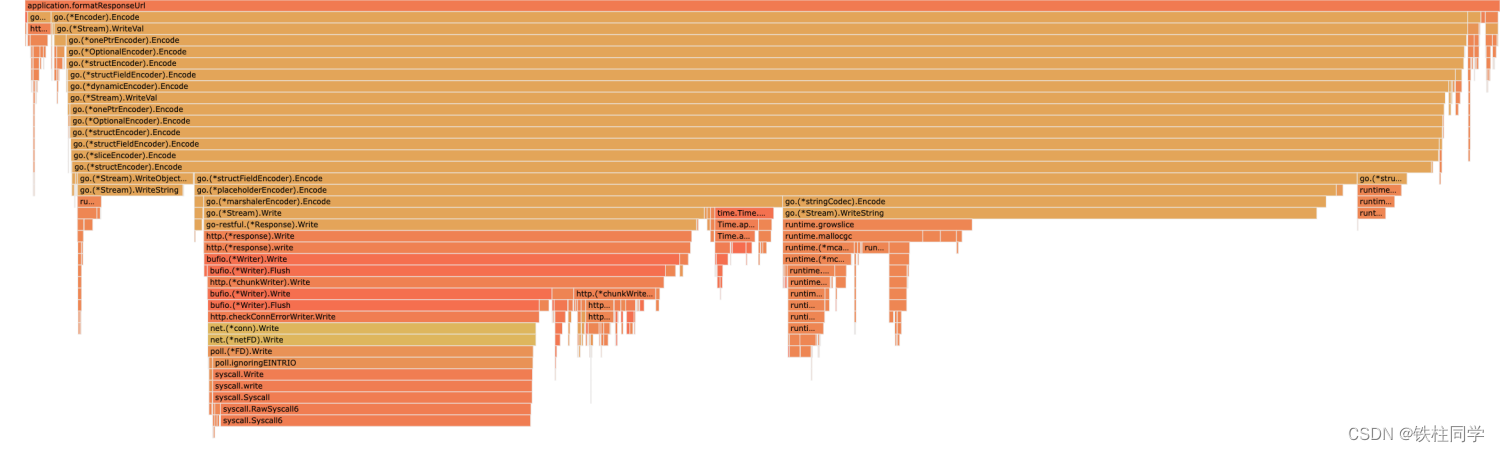
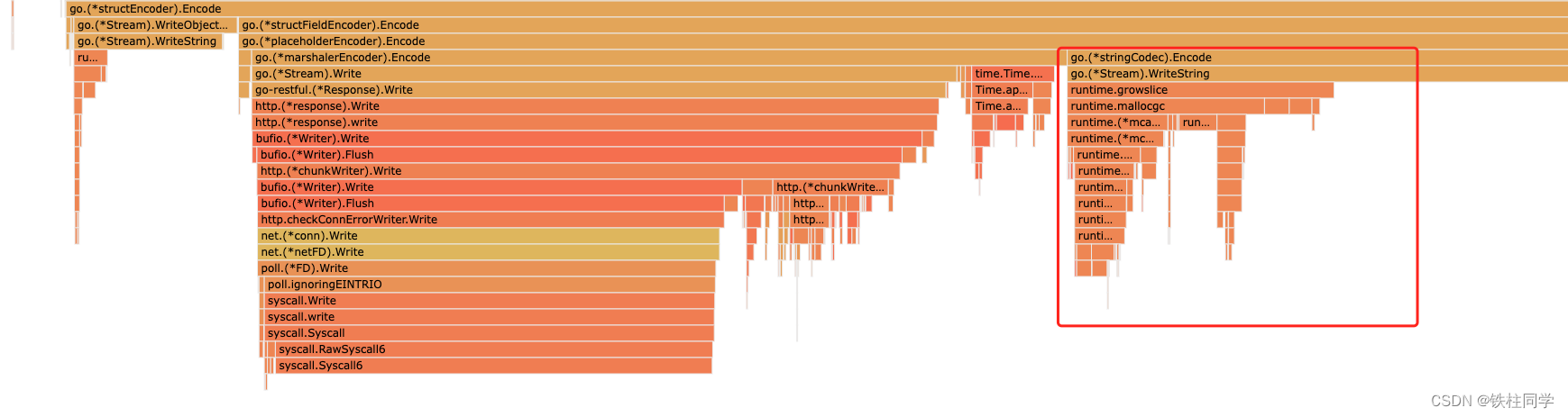
理论上来说,把写入response合并到一起,减少了数据拷贝才对,但是实测发现json耗时从27%到33%。 查看详情发现,主要是多了切片动态扩容的部分,如下所示:
减少不必要的日志打印
logrus的info部分转为debug。不必要的infof打印参数去掉或者转为debugf
手动设置GOGC阈值
目前使用内存太少了,分配了4G只使用了几十M。Go服务的GC阈值可以通过GOGC这个环境变量来配置,默认是100,也就是说:
GC的部分可以参考:Golang的trace性能分析
当前内存10M,那么下次GC是在10M + 10M * 100% = 20M的时候进行GC。
设置阈值增大10倍,预计在内存占比达到100-200M区间才会进行GC
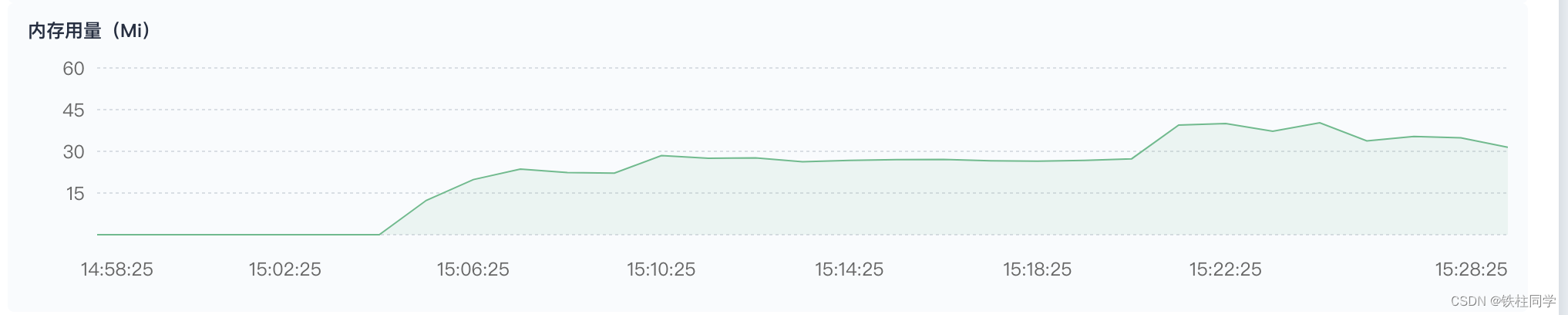
优化后的效果
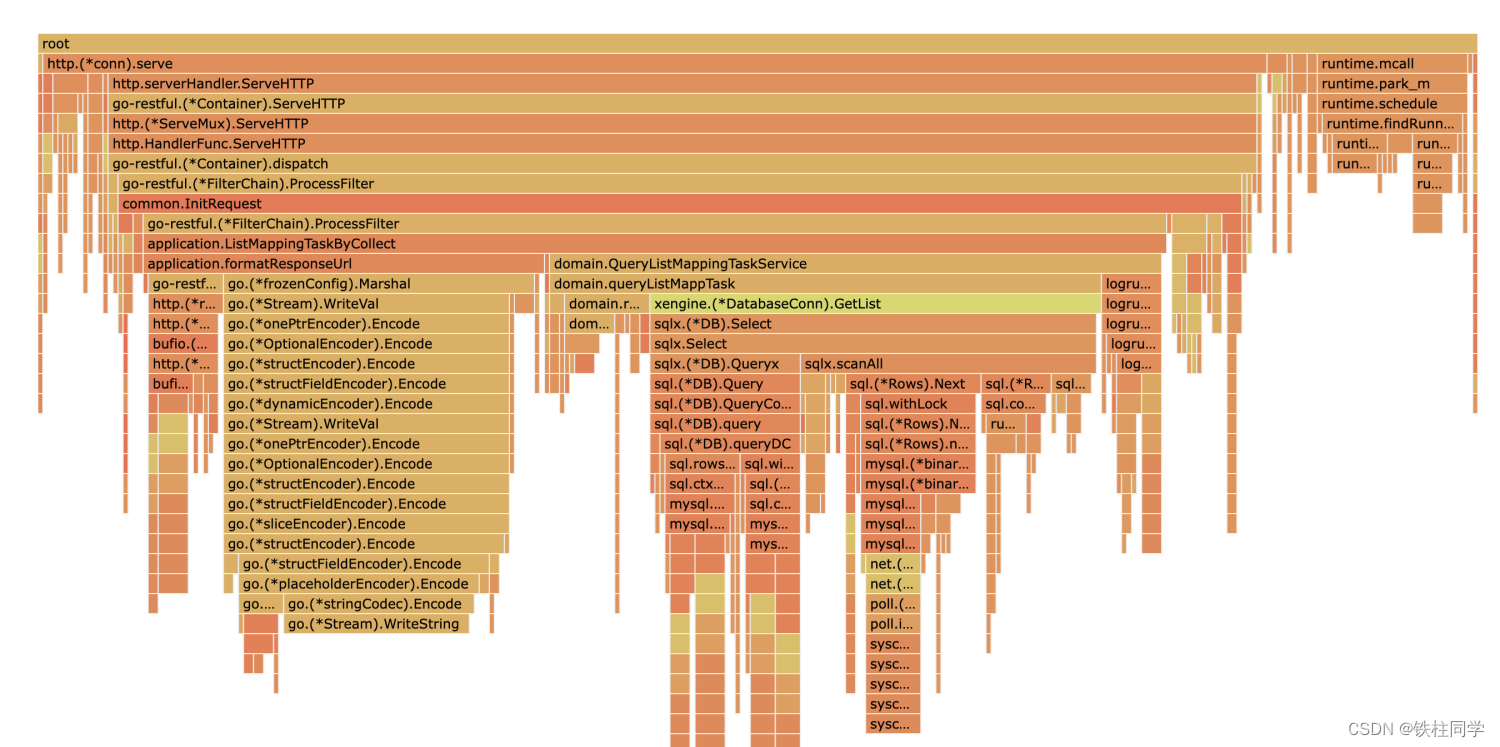
压测结果

结论
1、数据库占比31%
2、日志占比下降,目前占比4%
3、json序列化占比20%左右
4、主要耗时还是在sql,需要上缓存
5、参数校验耗时低于1%
6、GC占比略有下降,查看trace发现GC频率明显下降。
后续优化方向
1、接入缓存
高QPS必定离不开缓存,数据库能支撑的QPS有限。使用redis做缓存是合适的。
2、限制查询数量
json序列化随着查询参数的增多,占比越来越大。适当减少数据的返回,对json序列化提升会很大。
3、更换高性能日志库
日志的重要性不需要强调,因为性能而放弃日志也是不可取的。作为现在统计和排查问题的关键,我们可以选择使用更高性能的日志库。
uber开源的高性能日志库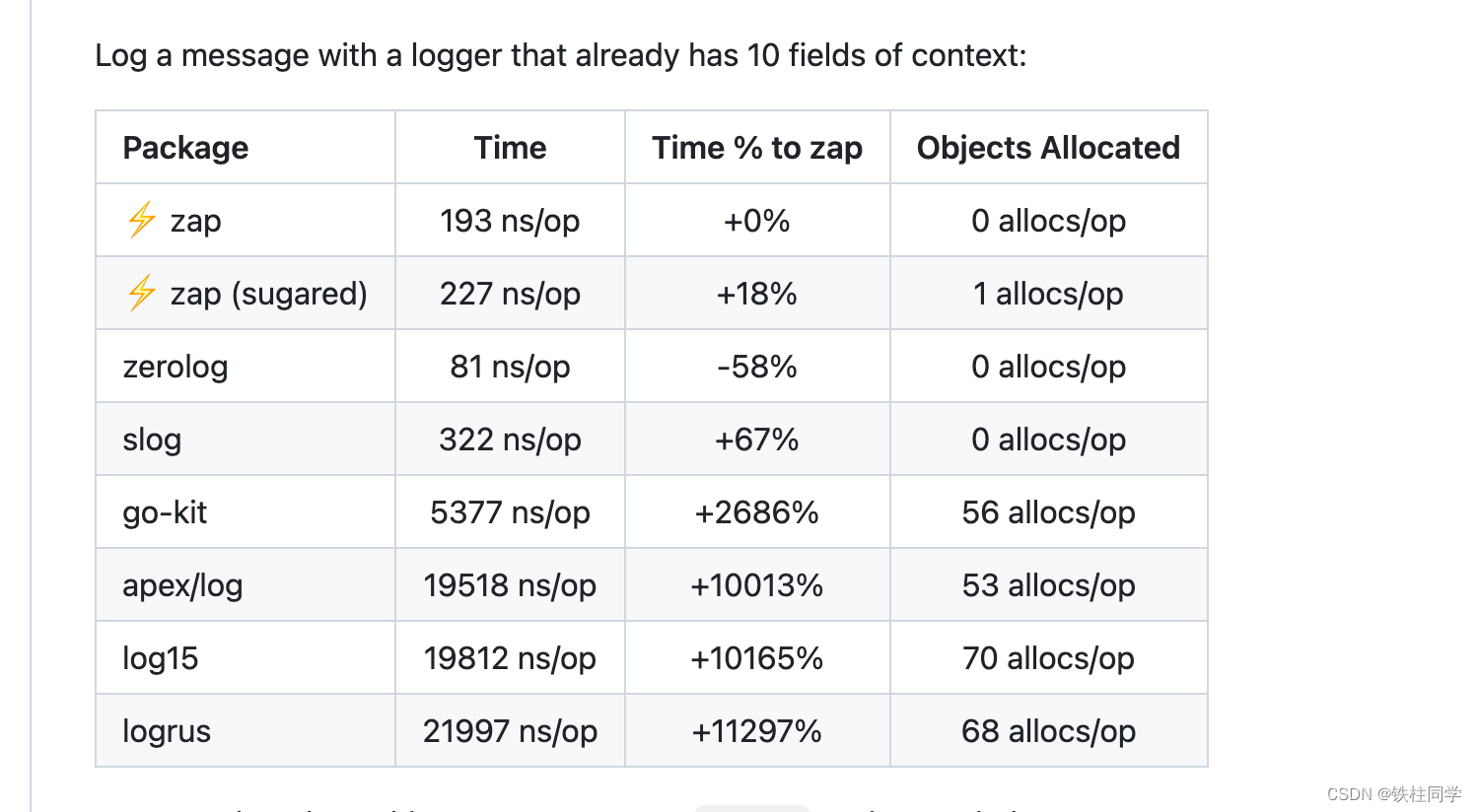
实话实说,logrus的性能实在是差。
4、GC调优
Go 1.9之前只能设置GOGC方法来调整GC的阈值,1.9之后可以直接设置一个MemoryLimit,达到limit就GC,不达到就不GC。
问题是,GC阈值变的很高就真的很好吗,一次GC扫描的内存变大,标记耗时也会延长,实际的效果可能并不能如意,需要慎重和多次验证找到最佳GC阈值。
end















 449
449











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











