






资讯
研究
数量即力量!腾讯揭秘:Agent数量越多,大语言模型效果越好
https://mp.weixin.qq.com/s/aIBs7-DOVt40vqhcLbJXTA
来自腾讯的研究者们做了一个关于 agent 的scaling property(可拓展性)的工作。发现:通过简单的采样投票,大语言模型(LLM)的性能,会随着实例化agent数量的增加而增强。其第一次在广泛的场景下验证了该现象的普遍性,与其他复杂方法的正交性,以及研究了其背后的原因,并提出进一步促成scaling发挥威力的办法。

AlphaFold 预测细菌生存所需的 1402 种蛋白互作,最完整的细菌必需相互作用图谱
https://mp.weixin.qq.com/s/1ZKb4PVGOBQ1EpoE4FsrJg
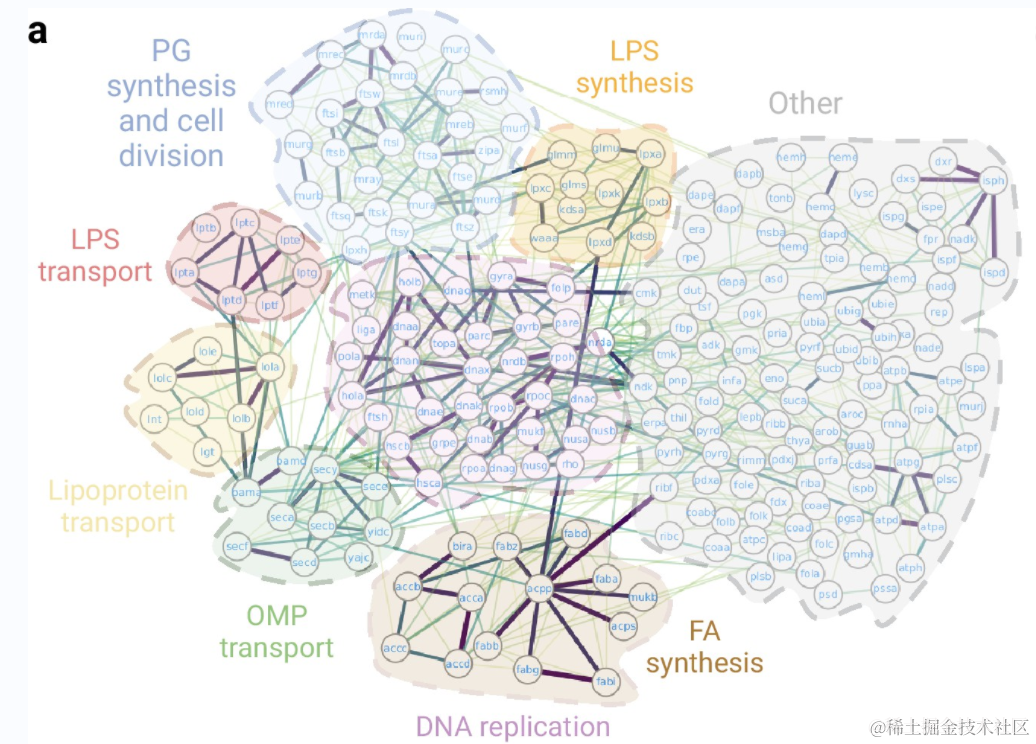
细菌蛋白质组平均由约 4000-5000 个蛋白质组成,这意味着相互作用组可能多达 2000 万个相互作用。据估计,大肠杆菌中大约有 12,000 种物理相互作用。然而,并非所有这些相互作用都对细菌的生存至关重要。对生物体中蛋白质相互作用的研究,是理解生物过程和中心代谢途径的基础。然而,我们对细菌相互作用组的了解仍然有限。近日,西班牙巴塞罗那自治大学(Universitat Autònoma de Barcelona,UAB)的研究人员使用人工智能工具 AlphaFold,预测并模拟了细菌中必需(essential)蛋白质之间的 1402 种相互作用。研究人员绘制了最完整的细菌必需相互作用图谱,即蛋白质如何结合和相互作用以执行其生存所必需的功能。这些结果揭示了这些机制以前未知的细节,并为开发新的抗生素提供了潜在的靶点。
产业
能看会说的人形机器人,对话的样子吓到我了
https://mp.weixin.qq.com/s/v4k-dlKSWCDTmAnHp1Bzhg
Ameca说话的能力是通过接入大型语言模型(早先是GPT-3)来实现的,所以交流起来和语音版ChatGPT体验非常接近。观察世界的能力则来自安装在眼睛、胸部等处的各个摄像头。这些摄像头可以识别人脸、物品和周围环境,并判断在谈话中谁在注意倾听或是在做眼神交流。有时 ,Ameca 也需要多试一次才能准确看到目标(比如,视频里看到第三个人体头部的解剖模型)。在最近举办的2024年世界移动通信大会(MWC 2024)上,Ameca接受了很多媒体的「采访」。

知名AI研究者深挖谷歌Gemma:参数不止70亿,设计原则很独特
https://mp.weixin.qq.com/s/-pB6nElzAx3vrH7vMuALzA
就在几天前,开源大模型领域迎来了重磅新玩家:谷歌推出了全新的开源模型系列「Gemma」。相比 Gemini,Gemma 更加轻量,同时保持免费可用,模型权重也一并开源了,且允许商用。谷歌发布了包含两种权重规模的模型:Gemma 2B 和 Gemma 7B。尽管体量较小,但 Gemma 已经「在关键基准测试中明显超越了更大的模型」,包括 Llama-2 7B 和 13B,以及风头正劲的 Mistral 7B。与此同时,关于 Gemma 的技术报告也一并放出。相信大家已经对 Gemma 的相关内容进行了系统研究,本文知名机器学习与 AI 研究者 Sebastian Raschka 向我们介绍了 Gemma 相比于其他 LLM 的一些独特设计原则。

反转?OpenAI:纽约时报「黑客攻击」了ChatGPT,要求驳回版权诉讼
https://mp.weixin.qq.com/s/UOlQEM8dg9_Zib2sk30kWw
去年年底,《纽约时报》向微软和 OpenAI 提起侵犯版权诉讼,指控其违规使用了《纽约时报》的内容来进行人工智能开发。在这份起诉书中,《纽约时报》列出了 GPT-4 输出「抄袭」《纽约时报》的「证据」,GPT-4 的许多回答与《纽约时报》的报道段落几乎完全一致。《纽约时报》指责 OpenAI 和微软试图「搭《纽约时报》对其新闻业的巨额投资的便车」,并创建报纸的替代品。彼时,《纽约时报》发言人在一份电子邮件声明中表示:「如果微软和 OpenAI 想要将我们的作品用于商业目的,法律要求他们首先要获得我们的许可,但他们没有这样做。」令人意外的是,事情居然出现了反转。据路透社报道,OpenAI 已要求联邦法院驳回《纽约时报》的版权诉讼,并称该报「黑客攻击」了 OpenAI 的 ChatGPT 和其他人工智能系统,为该报生成误导性证据。OpenAI 在周一向曼哈顿联邦法院提交的文件中称《纽约时报》通过使用「公然违反 OpenAI 使用条款的欺骗性提示(deceptive prompt)」,使得 AI 复制其材料。

自研大模型新成果:蚂蚁百灵大模型推出 20 亿参数遥感模型,论文入选国际 AI 顶会 CVPR 2024
https://www.geekpark.net/news/331706
蚂蚁集团推出 20 亿参数多模态遥感基础模型 SkySense,这是蚂蚁百灵大模型在多模态领域最新的研发成果,其论文已被世界计算机视觉顶会 CVPR 2024 接收。数据显示,SkySense 在 17 项测试场景中指标均超过国际同类产品,这也是迄今为止国际上参数规模最大、覆盖任务最全、识别精度最高的多模态遥感基础模型。SkySense 可用于地貌、农作物观测和解译等,有效辅助农业生产和经营。

Playground 开源发布 V2.5 版本 AI图像生成模型
https://blog.playgroundai.com/playground-v2-5/
Playground 开源发布 V2.5 版本 AI 图像生成模型,在色彩和对比度的增强、多宽高比的改进生成以及以人像生成的精细细节都有改善。Playground 称 V2.5 在用户研究中显示出效果的显著提升,与SDXL、Playground V2 和PixArt-a 等开源模型相比,以及与 DALL.E3 和 Midjourney V5.2 等闭源图像模型相比都有优势。

推特
Pika Labs分享Lip Sync效果视频
https://x.com/pika_labs/status/1762507225455604165?s=20
我们知道最近有很多关于人工智能生成视频的讨论。那么,现在谁在谈论呢!
现在Pro用户可以在http://pika.art上获得对Lip Sync的早期访问权限。
暂时无法在飞书文档外展示此内容
Klarna的人工智能客服代理在第一个月就能独立处理三分之二的请求,相当于700名客服代理的工作量
https://x.com/tanayj/status/1762611727764537671?s=20
哇,Klarna的人工智能客服代理在第一个月就能独立处理三分之二的请求,相当于700名客服代理的工作量。
New York, NY - February 27, 2024 - Klarna今天宣布其由OpenAI支持的AI助手现已全球上线1个月,数据本身就是最好的证明:
-
该AI助手已进行了230万次对话,占Klarna客户服务聊天的三分之二
-
它所做的工作相当于700名全职代理
-
在客户满意度得分方面,它与人类代理持平
-
在解决差错方面它更加准确,导致重复查询减少了25%
-
客户现在可以在不到2分钟内解决他们的问题,之前需要11分钟
-
它在23个市场提供服务,全天候运行,并支持超过35种语言
-
预计它将在2024年为Klarna带来4000万美元的利润增长

Bunin分享:使用FramesX UI Kit和Replit plugin,从Figma变成React
https://x.com/buninux/status/1762457062695477705?s=20
Dmitriy Bunin:亲爱的,快醒醒,Figma转React是真的!使用FramesX UI Kit和Replit plugin
Frames X - UI界面套件和设计手册
Frames X是唯一的Figma设计系统和手册,用以优化您的工作流程,帮助您更快完成项目,并通过高效管理更多项目来获得更多收入。
暂时无法在飞书文档外展示此内容
Xenova分享实时对象检测,使用Transformers.js,在浏览器中直接运行YOLOv9
https://x.com/xenovacom/status/1762524166249447901?s=20
实时对象检测 w/ 🤗 Transformers.js,在浏览器中直接运行YOLOv9!🤯
这个演示展示了为什么设备上的机器学习这么重要:
-
隐私 - 本地推理意味着不会将用户数据发送到云端
-
无服务器延迟 - 使开发者能够构建实时应用程序
-
降低成本 - 无需支付视频流的带宽和处理费用
暂时无法在飞书文档外展示此内容
DSPy框架如何通过用编程和编译替换提示来解决基于大型语言模型应用程序中的脆弱性问题
https://x.com/helloiamleonie/status/1762508240359702739?s=20
如果你不是生活在岩石下,你已经注意到开发者社区目前对DSPy非常兴奋。
DSPy是由斯坦福大学NLP研究人员(@lateinteraction)开发的框架,旨在帮助你构建基于大型语言模型(LLM)的应用程序。
与类似的框架相比,DSPy旨在通过优先考虑编程而不是提示(prompting),来解决开发基于LLM的应用程序的脆弱性问题。
DSPy通过引入以下概念来实现这一点:
-
手写提示和微调被抽象并替换为签名
-
提示技术,如思维链(Chain of Thought)或ReAct,被抽象并替换为模块
-
手动提示工程通过优化器(teleprompters)和DSPy编译器实现自动化
下面,你可以看到一个针对初学者RAG管道的DSPy程序的代码和信息流程是什么样的。
在@TDataScience上阅读更多:https://medium.com/towards-data-science/intro-to-dspy-goodbye-prompting-hello-programming-4ca1c6ce3eb9?sk=9c65441028a96a8f7e8eac9ed6ba4347

Tumblr和Wordpress正准备向Midjourney和OpenAI出售用户数据, Clem:权力集中的风险将非常巨大
https://x.com/ClementDelangue/status/1762573829799354577?s=20
来自@samleecole的新消息:根据我们审阅的内部文件,Tumblr和Wordpress正准备向Midjourney和OpenAI出售用户数据。
HuggingFace Clem: 有争议的观点:如果我们最终处于一个只能在$$许可的数据上训练好的AI模型的系统中,那么权力集中的风险将非常巨大。可能不是用户、艺术家或内容创作者会从中受益,而是大公司和好莱坞工作室将交易他们的权利而不进行再分配。

virat分享:开源财务代理,可以反馈股票的最新价格、股票的最新新闻
https://x.com/virattt/status/1762615408803053813?s=20
我的开源财务代理🤖
这是我为了乐趣而构建的一个新的副项目。
它将从colab开始,所以你可以运行我实现的所有代码。
开始的两个工具:
• 股票的最新价格
• 股票的最新新闻
现在,它可以回答:
“ABNB的最新股价和新闻是什么?”
即将推出的工具:
• 股票的财务数据
• 股票的内在价值
所有这些都是借助@LangChainAI的LangGraph构建的。
财务数据由@polygon_io提供支持。

GitHub Copilot Enterprise正式发布
https://x.com/ashtom/status/1762509378144629137?s=20
今天,我们带来了开发者工具的下一个前沿——GitHub Copilot Enterprise的正式发布,这是一个根据您组织的知识和代码库定制的伴侣。

OpenDiT:易于使用、快速且内存效率高的系统,用于训练和部署DiT模型
https://x.com/YangYou1991/status/1762447718105170185?s=20
想要训练一个像#Sora那样的模型吗?看看我们的新项目#OpenDiT吧!
OpenDiT是一个易于使用、快速且内存效率高的系统,用于训练和部署DiT模型,这些模型是像Sora这样的模型的基础。
使用OpenDiT,你可以实现:
-
训练速度提升高达80%
-
内存使用减少50%
-
通过新颖的序列并行性,通信量减少超过50%
Github: https://github.com/NUS-HPC-AI-Lab/OpenDiT

论文
通过 Evo 模型从分子到基因组规模上进行序列建模和设计
链接:https://www.biorxiv.org/content/10.1101/2024.02.27.582234v1
基因组是一串完整编码了DNA、RNA和控制整个生物体功能的蛋白质的序列。结合大规模全基因组数据集的机器学习进步,可能会实现一种生物学基础模型,加速我们对复杂分子相互作用机制的理解和生成设计。我们报道了Evo,一种基因组基础模型,能够从分子到基因组尺度进行预测和生成任务。利用基于深度信号处理进步的架构,我们将Evo扩展到70亿参数,并具有131千碱基(kb)的上下文长度,以单核苷酸、字节解析度实现。Evo在整个原核生物基因组上进行训练,能够跨越分子生物学中心法则的三个基本模式进行泛化,执行零样本功能预测,其表现不仅可以与领先的特定领域语言模型相媲美,甚至能超越它们。Evo在多元素生成任务上也表现出色,我们通过首次生成合成CRISPR-Cas分子复合物和完整的转座系统来证明这一点。Evo利用从整个基因组学到的信息,还能够以核苷酸解析度预测基因的必要性,并且能生成长达650千碱基的富含编码序列,其长度比之前的方法要长几个数量级。Evo在多模态和多尺度学习方面的进步为我们在多个复杂性层面上提高对生物学的理解和控制提供了一条有前景的路径。

视频是现实世界决策的新语言
链接:http://arxiv.org/abs/2402.17139v1
文本和视频数据在互联网上丰富,并通过下一个token或帧预测支持大规模自监督学习。然而,它们并未被充分利用:语言模型在现实世界中产生了重大影响,而视频生成在很大程度上仅限于媒体娱乐。然而,视频数据捕捉到了难以用语言表达的关于物理世界的重要信息。为了弥补这一差距,我们讨论了将视频生成扩展到解决现实世界任务的一种被低估机会。我们观察到,类似于语言,视频可以作为统一界面,吸收互联网知识并代表各种任务。此外,我们展示了视频生成如何通过技术(如上下文学习、规划和强化学习)成为规划者、智能体、计算引擎和环境模拟器,类似于语言模型。我们确定了在领域中的主要影响机会,例如机器人、自动驾驶和科学,这些机会得到了最近的研究支持,证明了视频生成中这些先进能力可能在可见层次内。最后,我们确定了在视频生成中减缓进展的关键挑战。解决这些挑战将使视频生成模型能够在更广泛的AI应用中与语言模型展示出独特价值。

Sora:大视觉模型的背景、技术、限制和机遇回顾
链接:http://arxiv.org/abs/2402.17177v1
摘要:Sora是一个由OpenAI于2024年2月发布的文本到视频生成AI模型。该模型经过训练,能够根据文本指令生成逼真或想象的场景视频,并展示出模拟物理世界的潜力。本文基于公开的技术报告和逆向工程,全面审视了该模型的背景、相关技术、应用、挑战以及文本到视频AI模型的未来发展方向。我们首先追踪Sora的发展并调查用于构建这个“世界模拟器”的基础技术。然后,我们详细描述了Sora在影视制作、教育和营销等多个行业中的应用和潜在影响。我们讨论了需要解决的主要挑战和限制,比如确保视频生成的安全性和公正性。最后,我们探讨了Sora和视频生成模型的未来发展,以及该领域的进步如何能促进人机互动的新方式,提升视频生成的生产力和创造力。

Playground v2.5: 提高文本到图像生成美学质量的三个见解
链接:http://arxiv.org/abs/2402.17245v1
在这项工作中,我们分享了实现文本到图像生成模型在美学质量方面取得最新成果的三个见解。我们专注于模型改进的三个关键方面:增强色彩和对比度,改善在多种比例下的生成,并提高以人为中心的微调细节。首先,我们深入探讨了在训练扩散模型中噪声计划的重要性,展示了它对现实感和视觉保真度的深刻影响。其次,我们解决了在图像生成中适应各种比例的挑战,强调准备均衡分桶数据集的重要性。最后,我们调查了将模型输出与人类偏好对齐的关键作用,确保生成的图像与人类感知预期 resonated。通过广泛的分析和实验,Playground v2.5在各种条件和比例下的美学质量方面展示了最新成果,在性能方面超过了广泛使用的开源模型,如SDXL和Playground v2,以及封闭源商业系统,如DALLE 3和Midjourney v5.2。我们的模型是开源的,希望Playground v2.5的发展为那些旨在提升基于扩散的图像生成模型美学质量的研究人员提供有价值的指导。

探究大语言模型中的持续预训练:洞察与影响
链接:http://arxiv.org/abs/2402.17400v1
本文研究了大语言模型(LLMs)中不断学习(CL)领域的发展,重点是开发高效持续训练策略。我们主要关注持续领域自适应预训练,这是一个旨在使LLMs具备整合来自各个领域新信息的能力,同时保留先前学到的知识、增强跨领域知识传递的过程,不依赖于特定领域识别。我们引入了一个新的基准,旨在衡量LLMs适应这些不断变化的数据环境的能力,提供评估的综合框架。我们的研究揭示了几个关键见解:(i)如果领域序列显示语义相似性,持续预训练使LLMs在当前领域的专业化比独立微调更好,(ii)跨多个领域的训练增强了前后知识传递,(iii)较小的模型对持续预训练特别敏感,显示出最显著的遗忘和学习率。我们认为我们的研究标志着建立研究LLMs中CL更现实的基准的转变,并有潜力在引导未来研究方向中发挥关键作用。

Sora 生成视频有令人惊叹的几何一致性
链接:http://arxiv.org/abs/2402.17403v1
摘要:最近开发的 Sora 模型在视频生成方面表现出色,引发了关于其模拟真实世界现象能力的激烈讨论。尽管其日益流行,但目前还缺乏能够定量评估其对真实世界物理规律忠实度的已建立指标。本文引入了一个新的基准,评估生成视频的质量,基于它们是否遵循真实世界物理原理。我们采用一种方法将生成的视频转换为3D模型,利用3D重建对视频质量的重要影响假设。从3D重建的角度,我们使用构建的3D模型满足的几何约束的忠实度作为评估生成视频符合真实世界物理规律程度的近似指标。项目页面:https://sora-geometrical-consistency.github.io/

释放大语言模型作为提示优化器的潜力:与基于梯度的模型优化器的类比分析
链接:http://arxiv.org/abs/2402.17564v1
自动提示优化是改善大语言模型(LLMs)性能的重要方法。最近的研究表明,可以将LLMs用作提示优化器,通过迭代改进生成改进的任务提示。在本文中,我们提出了一种新颖的视角,通过将其与基于梯度的模型优化器进行类比,来研究基于LLM的提示优化器的设计。为了将这两种方法联系起来,我们确定了模型参数学习中的两个关键因素:更新方向和更新方法。专注于这两个方面,我们借鉴了从梯度优化中的优化理论框架和学习方法,设计了改进的LLM提示优化器策略。通过系统分析丰富的改进策略,我们进一步开发了一种强大的基于梯度的LLM提示优化器,称为GPO。在每个步骤中,它首先从优化轨迹中检索相关提示作为更新方向。然后,通过控制余弦衰减策略来执行更新,同时利用基于生成的改进策略。大量实验证明了GPO的有效性和效率。特别是,与基准方法相比,GPO在Big-Bench Hard和MMLU上分别带来了高达56.8%和55.3%的额外改进。

产品
Thinkbuddy AI
https://thinkbuddy.ai/
Thinkbuddy 是供苹果 macOS 用户使用的 AI 门户,提供多种功能,包括语音转文字、截屏分析、快速聊天、文本操作工具、即时写作建议、文本辅助、快速激活人工智能等。该服务还提供访问 Google 的 Gemini 和即将推出的开源模型等。

Openmart
https://www.openmart.ai/
Openmart 是 ZoomInfo 的替代品,帮助初创企业根据其特定需求轻松发现潜在客户。可以在几秒钟内即可获得高质量零售商和中小型企业潜在客户的列表。

HuggingFace&Github
MobiLlama
https://github.com/mbzuai-oryx/MobiLlama
MobiLlama 是一个准确且完全透明的开源 5 亿(0.5B) 参数的小型语言模型(SLM)。它是为了满足资源受限计算的特定需求而设计的,重点是在减少资源需求的同时增强性能。 MobiLlama 使用了一种从更大的模型开始,并应用谨慎的参数共享方案来降低预训练和部署成本的设计方法。

OpenDiT
https://github.com/NUS-HPC-AI-Lab/OpenDiT
OpenDiT 是一个开源项目,提供由 Colossal-AI 支持的 Diffusion Transformer (DiT) 高性能实现,专门用于提高 DiT 应用程序的训练和推理效率,包括文本到视频生成和文本到图像生成。

AutoPrompt
https://github.com/Eladlev/AutoPrompt
AutoPrompt是一个提示优化框架,增强和完善实际用例的提示。该框架会根据用户意图自动生成高质量、详细的提示,并采用优化过程来迭代构建具有挑战性的边缘案例数据集,并相应地优化提示。这种方法不仅减少了提示工程中的手动工作,还有效地解决了常见问题,如提示敏感性和固有的提示歧义问题。

GPTFast
https://github.com/MDK8888/GPTFast
GPTFast 最初是 PyTorch 团队开发的一套技术,用于加速 Llama-2-7b 的推理速度。

投融资
开源生态系统AI平台FlowGPT完成1000万美元融资
https://www.prnewswire.com/news-releases/flowgpt-the-open-ecosystem-ai-platform-raises-10m-302070574.html
FlowGPT宣布在Pre-Series A轮中筹集到1000万美元,由专注于消费科技的Goodwater Capital领投,早期VC公司DCM跟投。这是一个为AI应用创建者和社群提供开放生态系统的包容性平台。FlowGPT自2023年1月推出以来,已在110个国家吸引了数百万月度活跃用户,用户基础活跃地开发了超过10万个AI应用,供LLMs(如ChatGPT, Google PaLM)和开源模型(如Pygmalion)使用。该资金将用于全球扩大其工程和研究团队。

NLX完成1200万美元A轮融资
https://nlx.ai/news/nlx-raises-12m-in-series-a-funding
NLX宣布完成由Cercano领投、Thayer Ventures和HL Ventures跟投的1200万美元A轮融资。早期投资者IAG Capital Partners、JetBlue Ventures以及Tech Square Ventures的Engage也参与了此轮投资。NLX利用最新的生成型AI、云软件以及其语音、聊天和多模态对话AI技术,为大型和企业品牌提供出色的客户体验。本轮资金将用于市场扩张、战略性招聘以及增加更多市场领先的能力,包括其专利的多模态技术。NLX的产品已在90个国家、超过65种语言和方言中部署。

Composable Prompts完成400万美元种子轮融资
https://composableprompts.com/blog/2024-02-27_seed-round-elaia-illuminate_financial
Composable Prompts宣布已经完成由Elaia Partners和Illuminate Financial领投、Motier Ventures、Kima Ventures等参投的400万美元种子轮融资。这家公司推出了一款企业级平台,可让企业部署具有高级治理、细粒度安全、协作、编排功能和创新的大型语言模型(LLM)虚拟化引擎的LLM技术。平台支持广泛的开源和专有模型,如Claude、LLama2、Mistral、GPT4和AI21,在多个提供商(包括OpenAI、Google VertexAI、Amazon Bedrock等)上运行。这些工具旨在简化LLM技术与业务流程的整合,并过渡到结构化、特定领域的方法。

学习
全面整理!机器学习常用的回归预测模型
https://mp.weixin.qq.com/s/7m2waIASOEg90NONgRpQFQ
这篇文章全面整理了机器学习中常用的回归预测模型,包括线性模型如普通最小二乘线性回归、套索回归(Lasso)、岭回归、随机梯度下降回归、弹性网络回归(ElasticNet)等;非线性模型如集成树模型(XGBoost、LightGBM、CatBoost)、决策树回归、支持向量机回归(SVR)、KNN回归等;以及广义线性模型(GLM)。文章还介绍了异常值鲁棒回归器、贝叶斯回归模型和深度学习模型,如多层感知器(MLP)、深度森林(DeepForest)和门控加性树集成(GATE)。这些模型在处理不同类型的数据和预测任务时具有各自的优势和应用场景。
北大AI对齐团队近期工作
https://zhuanlan.zhihu.com/p/684342003?utm_psn=1746165766137843712
北大AI对齐团队近期工作包括:1) 发布了AI对齐全面性综述和资源网站;2) 创建了百万条安全对齐数据集BEAVERTAILS;3) 提出了带安全约束的RLHF对齐算法;4) 开发了基于对齐器的超对齐方法Aligner;5) 研究了基于过程奖励的树结构RLHF;6) 探索了多目标对齐/帕累托对齐方法Panacea。此外,团队还进行了AI对齐相关的科普工作。
LLM推理到底需要什么样的芯片(2)
https://zhuanlan.zhihu.com/p/683908169?utm_psn=1746166526506643456
LLM(大型语言模型)推理需要的芯片需具备高内存带宽和互联带宽,以支持100GB~1TB级别的数据访问。芯片设计需考虑计算密集型的prefill阶段和访存密集型的decode阶段,以及不同场景下token量的变化。此外,芯片还需具备灵活性和可编程性,以适应不同用户请求的动态变化,同时满足对IO带宽的高要求,处理大量用户的KV-cache数据交换。这些需求对芯片的算力、内存容量、带宽、互联和系统调度设计提出了极高的挑战。
声明
本文档仅供学习交流使用,版权归原作者所有,若涉侵权,请联系Jack Jin 15101136166
















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









