






# 资讯
## 研究
### 前端不存在了?盲测64%的人更喜欢GPT-4V的设计,杨笛一等团队新作
https://mp.weixin.qq.com/s/uQ8T4VS9hyD-R-CNytFZcA
将视觉设计实现成执行功能的代码是一项颇具挑战性的任务,因为这需要理解视觉元素和它们的布局,然后将它们翻译成结构化的代码。这个过程需要复杂的技能,也因此让很多普通人无法构建自己的网络应用,即便他们已经有了非常具体的构建或设计思路。不仅如此,由于这个过程需要不同领域的专业知识,因此往往需要具备不同技能的人互相合作,这就会让整个网页构建过程更加复杂,甚至可能导致目标设计与实际实现之间出现偏差。近日,斯坦福大学、佐治亚理工学院等机构的一个联合团队评估了当前的多模态模型在这一任务上的表现。

### DenseMamba:大模型的DenseNet时刻,Mamba和RetNet精度显著提升
https://mp.weixin.qq.com/s/smTpbX_c_e2sxi4aas8Ibg
近期,来自华为诺亚方舟实验室的研究者提出了 DenseSSM,用于增强 SSM 中各层间隐藏信息的流动。通过将浅层隐藏状态有选择地整合到深层中,DenseSSM 保留了对最终输出至关重要的精细信息。DenseSSM 在保持训练并行性和推理效率的同时,通过密集连接实现了性能提升。该方法可广泛应用于各种 SSM 类型,如 Mamba 和 RetNet。

### 当prompt策略遇上分治算法,南加大、微软让大模型炼成「火眼金睛」
https://mp.weixin.qq.com/s/xxMg97rmHQ1w4ILsai3NdA
近年来,大语言模型(LLMs)由于其通用的问题处理能力而引起了大量的关注。现有研究表明,适当的提示设计(prompt enginerring),例如思维链(Chain-of-Thoughts),可以解锁 LLM 在不同领域的强大能力。然而,在处理涉及重复子任务和 / 或含有欺骗性内容的任务(例如算术计算和段落级别长度的虚假新闻检测)时,现有的提示策略要么受限于表达能力不足,要么会受到幻觉引发的中间错误的影响。为了使 LLM 更好地分辨并尽可能避免这种中间错误,来自南加州大学、微软的研究者提出了一种基于分治算法的提示策略。这种策略利用分治程序来引导 LLM。

### 不依赖token,字节级模型来了!直接处理二进制数据
https://mp.weixin.qq.com/s/BLUTwhAlbXMPKYAgIoB_0Q
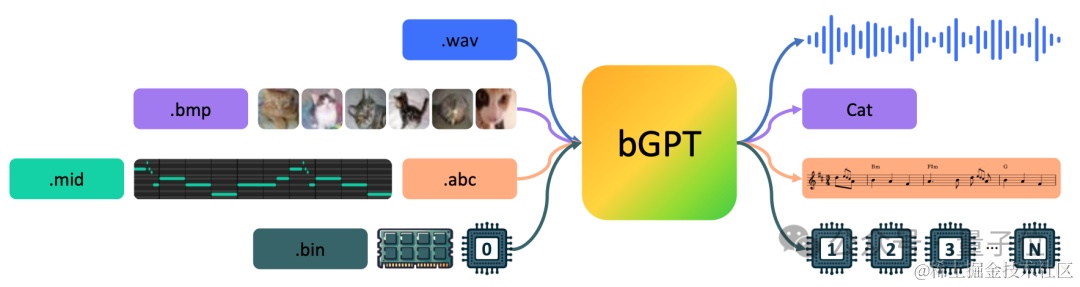
最新GPT,不预测token了。微软亚研院等发布bGPT,仍旧基于Transformer,但是模型预测的是**下一个字节(byte)** 。通过直接处理原生二进制数据,bGPT将所有输入内容都视为字节序列,从而可以不受限于任何特定的格式或任务。能预测CPU行为,准确率**超过99.99%** ;还能直接模拟MIDI——一种音乐传输和存储的标准格式。研究团队认为,传统的深度学习往往忽视了**字节**——数字世界的构建基石。不论是信息的形式还是操作,都是通过二进制格式编码和处理的。字节构成了所有数据、设备和软件的基础,从计算机处理器到我们日常使用的电子产品中的操作系统。
## 产业
### 黄仁勋透露英伟达下一代 DGX AI 系统将采用液冷技术
https://www.ithome.com/0/754/850.htm
英伟达 CEO 黄仁勋已确认,其下一个 DGX AI 系统将采用液冷散热。这为数据中心领域带来了新的机遇。英伟达在一次会议上透露了该消息。数据中心和 AI 服务器领域一直在加快推进液冷步伐,各公司为液冷设备的制造工厂投入巨额资金。此外,液冷数据中心将需要大量的研发工作和足够的基础设施来维护。在数据中心使用液冷有利有弊,主要好处包括更高效的降温和更高的服务器机架密度,因为液冷可以使服务器在机架内更紧密地排列。然而,其高昂的建造成本和维护复杂性一直阻碍推广。

### 零一万物自研全导航图向量数据库,横扫权威榜单6项第一
https://mp.weixin.qq.com/s/FAH1nPYLKtkiniW3WcYRxg
3 月 11 日,零一万物宣布推出基于全导航图的新型向量数据库 「笛卡尔(Descartes)」,已包揽权威榜单 ANN-Benchmarks 6 项数据集评测第一名。向量数据库,又被称为 AI 时代的信息检索技术,是检索增强生成(Retrieval-Augmented Generation, RAG)内核技术之一。对大模型应用开发者来说,向量数据库是非常重要的基础设施,在一定程度上影响着大模型的性能表现。在国际权威评测平台 ANN-Benchmarks 离线测试中,**零一万物笛卡尔(Descartes)向量数据库登顶6 份数据集评测第一名,比之前榜单上同业第一名有显著性能提升,部分数据集上的性能提升甚至超过 2 倍以上。** 零一万物表示,笛卡尔向量数据库将用在近期即将正式亮相的 AI 产品中,未来也将结合工具提供给开发者。

### AWS AI 高管表示,英伟达不是思科,其芯片需求将维持高位
https://mp.weixin.qq.com/s/iWMsRhX1Gprk0jiiRb8SlQ
Nvidia 迅速崛起,成为市值第三大公司,这让很多人将其与思科进行比较。思科在互联网泡沫时期销售路由器取得了成功,短暂地成为了世界上最有价值的上市公司,但 AWS 人工智能产品副总裁 Matt Wood *()* 对这种比较提出了质疑。Wood 表示,Nvidia 的创新能力和为客户带来的“巨大收益”是思科无法比拟的。思科的崛起是短暂的,近年来该公司的业务已经停滞不前。虽然包括 Databricks CEO Ali Ghodsi 在内的一些行业人士表示,他们预计 Nvidia AI 芯片的供应限制将在明年得到缓解,从而导致价格下降,但伍德表示他也不确定这一点。Wood 在与外媒 Information 对谈时表示:“我预计需求将保持相当高的水平。”AWS 和其他云服务提供商将 Nvidia 驱动的服务器出租给他们的客户,并使用它们来开发自己的AI 服务。

# 推特
### 马斯克宣布本周开源Grok,并评论区怒怼OpenAI
https://x.com/elonmusk/status/1767108624038449405?s=20
本周,@xAI 将开源 Grok
* * *
评论区:
如果OpenAI真的是"开放"的,他们也应该这样做。
马斯克回复:
OpenAI只是个谎言

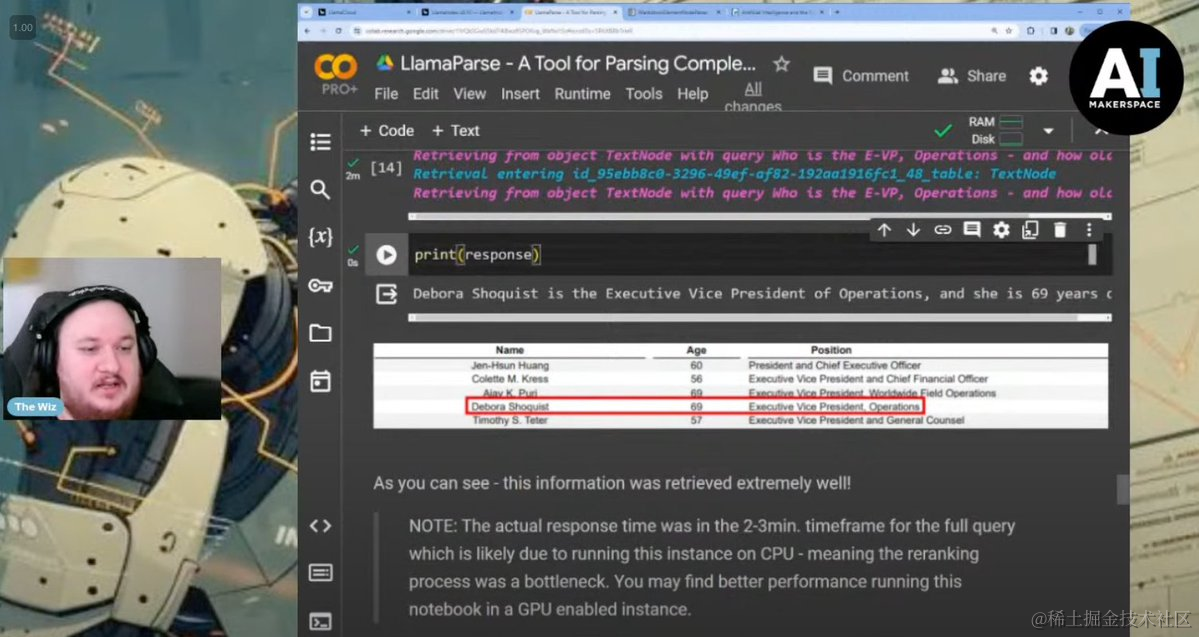
### 用RAG搜索复杂PDF文档
https://x.com/llama_index/status/1766862130761125958?s=20
复杂PDF文档上的RAG V2 📑
如果你在寻找一个权威的教程,教你如何在凌乱、复杂的PDF文档(包含混乱的格式、字体、表格、图表)上解决RAG问题,这就是适合你的教程。
在这些情况下,简单的RAG是行不通的⛔️。这个由@AIMakerspace 制作的视频是一个全面的教程,向你展示如何使用LlamaParse和LlamaIndex,通过高级解析、分层索引和递归检索,精心设计一个RAG管道。
完整视频在这里🎞️:https://youtube.com/watch?v=7qsxz2rURG4
### LlamaGym:只需几行代码,就可以使用在线强化学习来微调LLM Agent
https://x.com/khoomeik/status/1766805213644800011?s=20
基于大语言模型(LLM)的智能体在完成环境中的任务时,不应该得到改进吗?现在宣布推出LlamaGym!只需几行代码,就可以使用在线强化学习来微调LLM智能体。技术细节、GitHub仓库、实验结果等更多内容现已推出。
暂时无法在飞书文档外展示此内容
### Sanseviero分享:“选择LLM时需要考虑的不同工具、因素和注意事项”
https://x.com/osanseviero/status/1766921390970581142?s=20
Omar Sanseviero:比较基础的大语言模型(LLM)和它们的对话版本并非易事😫
我写了这篇博文,解释了在选择LLM时需要考虑的不同工具、因素和注意事项。
请欣赏!<https://osanseviero.github.io/hackerllama/blog/posts/llm_evals/>

### Leonie分享如何微调开源模型:使用LoRA技术微调Gemma-2B模型
https://x.com/helloiamleonie/status/1766856548309975226?s=20
你如何微调开源模型,例如谷歌的Gemma?
Merve Noyan (@mervenoyann)向你展示了如何使用LoRA技术微调Gemma-2B模型:
<https://colab.research.google.com/drive/12OkGVWuh2lcrokExYhskSJeKrLzdmq4T?usp=sharing>

### 泰米尔语大型语言模型7B v1.0版本上线,在泰米尔语Alpaca数据集上微调
https://x.com/MervinPraison/status/1766796706438426961?s=20
推出泰米尔语大型语言模型7B v1.0版本
专门为泰米尔语微调的大型语言模型。
Hugging Face模型地址:<https://huggingface.co/mervinpraison/tamil-large-language-model-7b-v1.0>
@reach_vb
<https://mer.vin/tamil-large-language-model/>
基础模型:Gemma 7B
在泰米尔语Alpaca数据集上微调
使用了@unslothai, 由@danielhanchen 提供
感谢@ramsri_goutham

### MajorTOM:最大的可用于机器学习的Sentinel-2卫星影像数据集
https://x.com/huggingface/status/1766839995162083593?s=20
我们很高兴与欧洲航天局合作发布MajorTOM,这是最大的可用于机器学习的Sentinel-2卫星影像数据集!🚀
它覆盖了地球表面的50%。2.5万亿像素的开源数据!
🤗👐🌌🚀🌏
<https://huggingface.co/Major-TOM>

# 论文
### **Deepseek-VL: 迈向现实世界的视觉语言理解**
链接:http://arxiv.org/abs/2403.05525v1
我们介绍了DeepSeek-VL,一个面向真实世界视觉和语言理解应用的开源视觉-语言模型。我们的方法围绕三个关键维度展开:我们努力确保我们的数据具有多样性、可扩展性,并且广泛覆盖包括Web截图、PDF、OCR、图表和基于知识的内容在内的真实场景,旨在全面表达实际环境。此外,我们从真实用户场景创建了用例分类法,并相应地构建了一份指导微调数据集。使用这个数据集进行微调显著改进了模型在实际应用中的用户体验。考虑到效率和大多数真实场景的需求,DeepSeek-VL集成了一个混合视觉编码器,能够高效处理高分辨率图像(1024 x 1024),同时保持相对较低的计算开销。这一设计选择确保了模型在各种视觉任务中捕获关键语义和详细信息的能力。我们认为一个熟练的视觉-语言模型首先应具有强大的语言能力。为了确保在预训练期间保持LLM的能力,我们研究了一种有效的视觉-语言预训练策略,通过从一开始就整合LLM训练并仔细管理视觉和语言模式之间观察到的竞争动力学。DeepSeek-VL系列(包括1.3B和7B模型)展示了在真实应用中作为视觉-语言聊天机器人的卓越用户体验,在保持鲁棒的语言中心基准性能的同时,在相同模型大小下实现了一流或具有竞争性的性能,跨越广泛的视觉-语言基准。我们已经公开发布了1.3B和7B模型,以促进基于这一基础模型的创新。

### **Gemini 1.5: 在数百万个token的上下文中解锁多模态理解**
链接:http://arxiv.org/abs/2403.05530v1
在这份报告中,我们介绍了Gemini家族的最新模型,Gemini 1.5 Pro,这是一个高度高效的多模态专家混合模型,能够回忆和推理来自上百万token上下文的细粒度信息,包括多个长文档和几小时的视频和音频。Gemini 1.5 Pro在跨模态的长上下文检索任务上实现了近乎完美的召回,改进了长文档QA、长视频QA和长上下文ASR的现有技术水平,并在一系列基准测试中与或超过了Gemini 1.0 Ultra的技术水平。通过研究Gemini 1.5 Pro长上下文能力的极限,我们发现在至少10M token范围内,下一个token的预测和几乎完美的检索率(>99%),这远远超过了现有模型如Claude 2.1(200k)和GPT-4 Turbo(128k)。最后,我们强调了大型语言模型在边界上的令人惊讶的新能力;当给定一个Kalaman语的语法手册,这是一种全球少于200名使用者的语言,模型学会以与从相同内容学习的人类相似的水平将英语翻译为Kalaman。

### **关于大型** **预训练模型** **人机协作的调查**
链接:http://arxiv.org/abs/2403.04931v1
摘要:在人工智能领域快速发展的背景下,人类智能与人工智能系统之间的合作,即人工智能(HAI)团队合作,已经成为推动问题解决和决策过程的基石。大型预训练模型(LPtM)的出现显著改变了这一格局,通过利用大量数据来理解和预测复杂模式,为人类智能提供了前所未有的能力。本文调查了LPtM与HAI的关键整合,强调了这些模型如何超越传统方法增强协作智能。它探讨了LPtM在增强人类能力方面的协同潜力,并讨论了这种协作对人工智能模型改进、团队协作、伦理考虑以及在各个领域的广泛应用的意义。通过这一探索,本研究揭示了LPtM增强的HAI团队合作的转变性影响,为未来的研究、政策制定和旨在充分发挥这种合作潜力为研究和社会利益做出贡献的战略实施提供了见解。

### **GEAR: 一种高效的** **KV** **缓存** **压缩算法** **,用于** **LLM** **的接近无损的生成推断**
链接:http://arxiv.org/abs/2403.05527v1
关键-值(KV)缓存已成为加快大型语言模型(LLMs)推理生成速度的事实标准。然而,随着序列长度的增加,缓存需求也在不断增长,将LLM推理转变为一个受内存限制的问题,显著地限制了系统吞吐量。现有方法依赖于丢弃不重要的token或对所有条目进行均匀量化。然而,这些方法往往会产生高的逼近误差,以表示压缩矩阵。自回归解码过程进一步增加了每一步的错误,导致模型生成的关键偏差和性能恶化。为了解决这一挑战,我们提出了GEAR,一种能够实现几乎无损高比例压缩的高效KV缓存压缩框架。GEAR首先将大多数大小相似的条目量化为超低精度。然后使用低秩矩阵来近似量化误差,使用稀疏矩阵来修正异常条目引起的个别错误。通过巧妙地整合三种技术,GEAR能够充分发挥它们的协同潜力。我们的实验表明,与其他选择相比,GEAR实现了接近无损的4位KV缓存压缩,吞吐量提高最多2.38倍,同时将峰值内存大小减小最多2.29倍。我们的代码公开可用于 https://github.com/HaoKang-Timmy/GEAR.

### **Alpaca对抗Vicuna:利用** **LLM** **揭示LLM的记忆现象**
链接:http://arxiv.org/abs/2403.04801v1
本文介绍了一种黑盒提示优化方法,使用攻击者LLM智能体揭示受害智能体中更高级别的记忆,与直接提示目标模型使用训练数据的方法相比,这是量化LLM中记忆的主要方法。我们使用迭代拒绝抽样优化过程来找到具有两个主要特征的基于指令的提示:(1)与训练数据最小的重叠,以避免直接向模型展示解决方案,和(2)受害模型的输出与训练数据的最大重叠,旨在诱导受害者吐出训练数据。我们观察到,我们基于指令的提示生成的输出与训练数据的重叠比基线前缀后缀测量高23.7%。我们的研究结果表明,(1)经过指令调整的模型可以暴露出与基础模型一样多的预训练数据,甚至更多;(2)除了原始训练数据之外的环境可能导致泄漏;(3)使用其他LLM提出的指令可以打开一条新的自动攻击途径,我们应进一步研究和探索。代码可在 https://github.com/Alymostafa/Instruction_based_attack 找到。

### **高效Transformer真的节省计算量吗?**
链接:http://arxiv.org/abs/2402.13934v1
摘要:随着基于Transformer的语言模型在越来越大的数据集和庞大数量的参数上进行训练,寻找替代标准Transformer的更高效方法变得非常有价值。尽管提出了许多高效的Transformer和Transformer替代方案,但没有提供它们能够作为标准Transformer替代品的理论保证。这使得难以确定何时使用特定模型以及优先考虑何种方向进行进一步研究。本文旨在了解高效Transformer的能力和局限性,特别是稀疏Transformer和线性Transformer。我们关注它们在思维能力方面的表现,通过“CoT prompts”展现,并遵循以前的研究将其建模为动态规划(DP)问题。我们的结果表明,虽然这些模型具有足够的表达能力来解决一般DP任务,但与预期相反,它们需要随着问题规模而扩大的模型大小。尽管如此,我们确定了一类DP问题,对于这些模型来说可以比标准Transformer更高效。通过在代表性DP任务上进行实验验证了我们的理论结果,增加了对高效Transformer实际优势和劣势的了解。

### **LLM4Decompile: 使用大语言模型反编译** **二进制代码**
链接:http://arxiv.org/abs/2403.05286v1
反编译旨在将编译代码恢复为易读的源代码,但在名称和结构等细节上存在困难。大型语言模型(LLMs)在编程任务上显示出潜力,鼓励将它们应用于反编译。然而,目前并不存在任何用于反编译的开源LLM。此外,现有的反编译评估系统主要考虑标记级准确性,而很大程度上忽略了代码的可执行性,这是任何程序最重要的特征。因此,我们发布了第一个开放获取的反编译LLMs,其范围从1B到33B,预训练了40亿个C源代码和相应的汇编代码的token。这些开源LLMs可以作为该领域进一步发展的基准。为了确保实际程序评估,我们引入了Decompile-Eval,这是第一个考虑了反编译的重新编译和重新执行性的数据集。该基准重点强调了从程序语义的角度评估反编译模型的重要性。实验表明,我们的LLM4Decompile已经展示了准确反编译21%的汇编代码的能力,比GPT-4提高了50%。我们的代码、数据集和模型已发布在https://github.com/albertan017/LLM4Decompile。

# 产品
### **EverLearns Studio**
https://generator.everlearns.com
EverLearns 是一个帮助用户在短短 5 分钟内生成任何课程的产品。它使用 AI 驱动的编辑器来构建交互式课程内容,并提供一键分享课程给学生的功能。这个平台旨在帮助内容创作者、教育工作者和家长快速创建高质量的课程,节省时间并专注于更重要的事情。
### Wondercraft
https://www.wondercraft.ai/
Wondercraft 是一个旨在简化音频内容创建过程的平台,它允许用户通过打字、使用逼真的 AI 声音甚至他们自己的克隆声音来制作播客、有声读物、广告等。该平台的目标是打破制作高质量音频的困难,以及解决语言障碍的问题。Wondercraft 还提供对现有内容进行翻译和配音的服务,结合了 AI 翻译的效率与人工编辑和质量保证。
# HuggingFace&Github
### MovieLLM
https://deaddawn.github.io/MovieLLM/
MovieLLM 是一种为长视频创建合成的高质量数据的框架。该框架利用 GPT-4 和文本到图像模型的强大功能来生成详细的脚本和相应的视觉效果。通过 MovieLLM,研究人员可以克服现有视频数据集在稀缺性和偏见方面的局限性,从而提高多模态模型在理解复杂视频叙事方面的性能。


### **Anthropic Cookbook**
https://github.com/anthropics/anthropic-cookbook
Anthropic Cookbook 帮助开发人员使用 Clade 进行构建的代码和指南,提供可复制的代码片段,用户可以轻松地将其集成到自己的项目中。
### AtomoVideo
https://atomo-video.github.io/
AtomoVideo 是一种新颖的高保真图像到视频 (I2V) 的生成框架,可从输入图像生成高保真视频,实现比现有工作更好的动作强度和一致性,并且无需特定调整即可兼容各种个性化 T2I 模型。

### FSDP_QLora
https://github.com/AnswerDotAI/fsdp_qlora
这个库是有关使用量化 LoRA + FSDP 进行训练的LLMs。
# 投融资
### AI创企Astera寻求募资5.34亿美元IPO ,估值或达50亿美元
https://news.crunchbase.com/ai/chip-startup-astera-labs-ipo/
Astera Labs,一家芯片初创公司,正计划通过首次公开募股(IPO)获得高达45亿美元的估值,利用投资者对所有与AI相关的事物的浓厚兴趣。这家位于加利福尼亚州圣克拉拉的公司将提供近1480万股,而现有股东将提供约300万股,根据其监管文件。总体而言,公司计划通过以每股27至30美元的价格出售股份,募集高达5.34亿美元资金。这一目标估值较公司2022年晚些时候在由富达管理研究公司领投的1.5亿美元D轮融资中的近32亿美元估值有所增加。Astera的其他投资者包括Atreides Management、英特尔资本和Sutter Hill Ventures。Astera的IPO申请正值芯片巨头Nvidia看似即将超越苹果成为世界第二大市值公司之际,高端芯片的需求因当前的生成式AI浪潮而达到前所未有的高度,这无疑与Astera的申请时机有关。
### 寻找最新人工智能初创公司的演示文稿。
https://decks.chiefaioffice.xyz/
Chief AI Decks 是一个展示超过50家人工智能创业公司商业计划书的平台。这个网站提供了一个独特的机会,让用户能够发现最新的AI创业公司,并将这些公司的信息直接发送到用户的邮箱中。网站分类详细,包括从前种子期(Pre-Seed)到C轮(Series C)不等的融资阶段,涵盖了各个领域的AI创业公司,如图形设计基础模型工具、人工智能和机器人技术、大数据处理等。这为对人工智能领域感兴趣的投资者、创业者和科技爱好者提供了丰富的资源和灵感。
# 学习
### 可能是讲的最清楚的WeightonlyGEMM博客
https://zhuanlan.zhihu.com/p/675427125?utm_medium=social&utm_oi=56635854684160&utm_psn=1750099158134951936&utm_source=wechat_session&s_r=0
文章详细介绍了WeightOnly GEMM技术,这是一种由NVIDIA和Microsoft合作提出的加速MoE推理的方法。该技术针对MoE模型大、内存受限的问题,通过将权重从int8或int4快速转换为FP16进行计算,同时保持高精度。文章还探讨了WeightOnly GEMM与Naive FP16 GEMM的性能对比,以及在不同batch size下的表现。此外,文章还深入讨论了快速整数到浮点数转换的技术细节,以及如何通过权重交错和布局转换来优化TensorCore的使用。最后,文章还提到了针对小batch size的WeightOnly GEMV优化,以及在不同GPU架构上实现WeightOnly GEMM的策略。
### LogSumExp求导
https://zhuanlan.zhihu.com/p/667056682?utm_medium=social&utm_oi=56635854684160&utm_psn=1750068190280077312&utm_source=wechat_session&s_r=0
文章详细阐述了LogSumExp(LSE)算子的求导过程。LSE在机器学习中广泛应用,如多分类问题的Softmax函数,用于解决数值上溢问题。文章首先定义了LSE的数学表达式,并区分了两种情况:当索引i不等于最大值索引j时,以及当i等于j时。通过一系列数学推导,作者得出了LSE对输入向量中每个元素的偏导数。最终结果表明,在两种情况下,LSE的导数都等于指数函数值除以所有指数函数值的总和。这一结果对于理解和优化涉及LSE的机器学习模型具有重要意义。
### FlashAttention v2核心代码解析
https://zhuanlan.zhihu.com/p/686225377?utm_psn=1750464860968919040
本文深入解析了FlashAttention v2的核心代码实现,涉及并行化设计、cute库的应用、early exit处理、流水线并行等技术。FlashAttention v2在处理序列长度维度上实现了并行化,提高了算法效率。代码中使用了cute库来加速数据拷贝和GEMM运算,同时通过early exit技术减少了不必要的计算,并通过流水线并行提高了计算效率。文章还详细介绍了softmax和mask函数的实现细节,以及如何将计算结果输出到全局内存。整体上,FlashAttention v2的实现展示了在推理和部署加速方面的先进技术和优化策略。
### Diffusion Policy系列文章笔记
https://zhuanlan.zhihu.com/p/686378554?utm_psn=1750564564008357888
文章主要总结了Diffusion Policy系列文章的关键技术点,专注于强化学习中的策略学习和优化。首先介绍了Diffusion Q-learning(DQL),将Diffusion模型与Q-learning结合,利用复杂概率分布作为策略,旨在直接最大化Q函数以提升策略性能。接着探讨了Selecting from Behavior Candidates (SfBC)和Implicit Diffusion Q-learning (IDQL),这两种方法通过创新的伪采样技术,从行为候选中选择最优策略,以解决Offline RL问题。文章通过深入分析这些方法的理论基础和实现机制,展示了如何有效地结合Diffusion模型和强化学习策略,以达到优化决策过程的目的。
# 声明
本文档仅供学习交流使用,版权归原作者所有,若涉侵权,请联系Jack Jin 15101136166



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









