







一、主要贡献
解决了给定单个输入图像的完善的多人 2D 人体姿态估计问题。 我们专门解决了自主导航设置中出现的挑战,如图 1 所示:(i) 宽视角,人类分辨率有限,即 30-90 像素的高度,以及 (ii) 行人相互遮挡的高密度人群 . 当然,我们的目标是高召回率和准确率。

二、思想概述
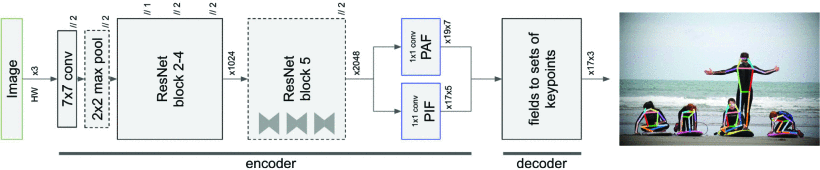
新方法 PifPaf 使用Part Intensity Field (PIF) 来定位身体部位,使用Part Association Field (PAF) 将身体部位相互关联以形成完整的人体姿势。 我们的方法在低分辨率和拥挤、杂乱和遮挡的场景中优于以前的方法,这要归功于 (i) 我们新的复合场 PAF 编码细粒度信息和 (ii) 选择拉普拉斯损失进行回归,其中包含了不确定性的概念。 我们的架构基于完全卷积、单次、无框设计。 我们在标准 COCO 关键点任务上执行与现有最先进的自下而上方法相当,并在交通领域的修改后的 COCO 关键点任务上产生最先进的结果。
我们建议将姿势估计 [3] 中的场概念扩展到标量和矢量场之外的复合场。 我们引入了一种具有两个头部网络的新神经网络架构。 对于每个身体部位或关节,一个头部网络预测该关节的置信度得分、精确位置和大小,我们将其称为部件强度场 (PIF),类似于 [34] 中的融合部件置信度图。 另一个头部网络预测部件之间的关联,称为部件关联字段 (PAF),它是一种新的复合结构。 我们的编码方案能够在低分辨率激活图上存储细粒度信息。 关节位置的精确回归至关重要,我们使用基于拉普拉斯的 L1 损失 [23] 而不是普通的 L1 损失 [18]。 我们的实验表明,我们在低分辨率图像上的性能优于自下而上和已建立的自上而下方法,同时在更高分辨率上的性能相当。














 4873
4873











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









