






0. 理论基础
推荐阅读:
DGA域名的今生前世:缘起、检测、与发展
1. 数据集
dga域名:
第一列是家族,后面是时间
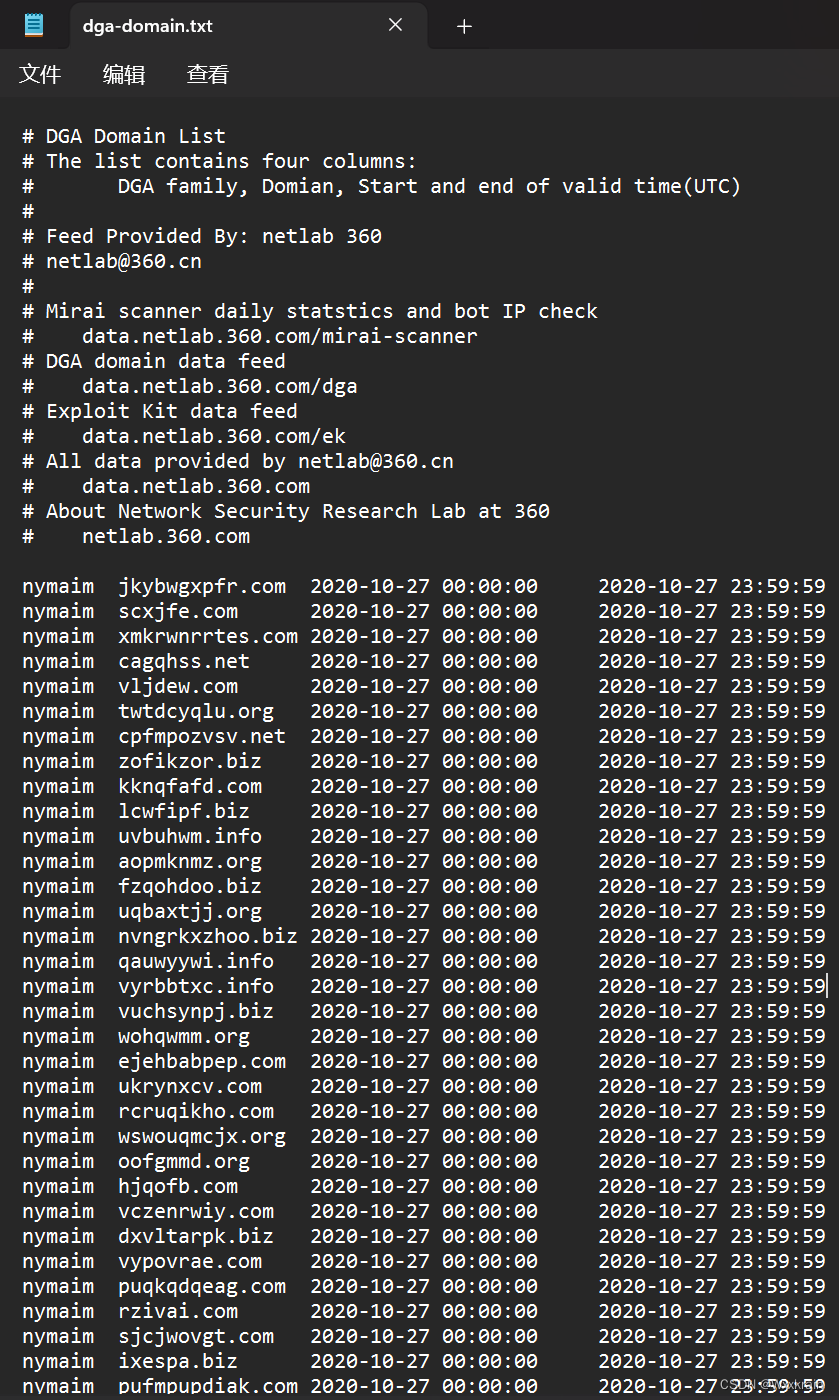
正常域名:
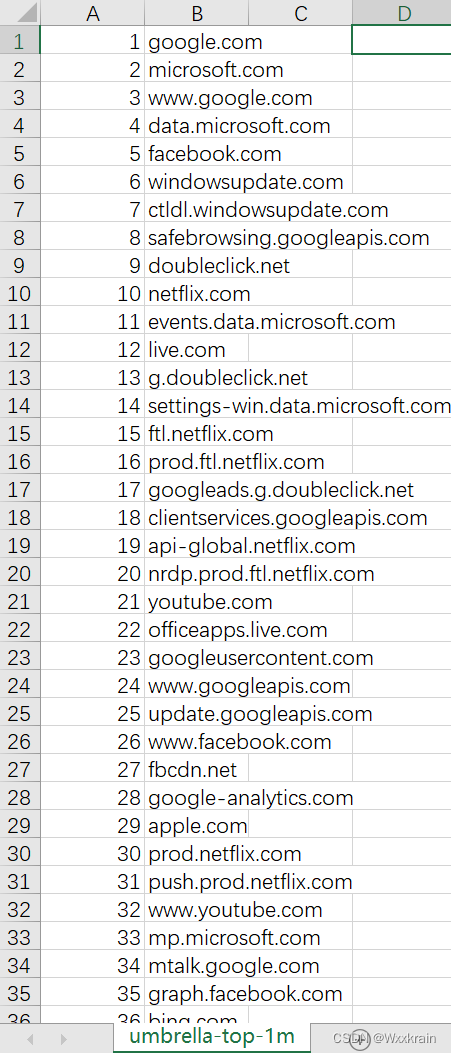
2. 代码实现
- 导入相关包
import pandas as pd
import numpy as np
from random import sample
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import accuracy_score, classification_report
from sklearn.feature_extraction.text import CountVectorizer, TfidfVectorizer
from gensim.models import Word2Vec
- 数据读取(dga标签1,正常域名标签0)
为加速,每类各取n=10000样本
dga_file="./dga-domain.txt"
alexa_file="./umbrella-top-1m.csv"
n = 10000
max_features=10000
#加载alexa文件中的数据
def load_alexa():
x=[]
data = pd.read_csv(alexa_file, sep=",",header=None)
x=[i[1] for i in data.values]
x = sample(x, n)
return x
#加载dga数据
def load_dga():
x=[]
data = pd.read_csv(dga_file, sep="\t", header=None,skiprows=18) #跳过前18行注释
x=[i[1] for i in data.values]
x = sample(x, n)
return x
alexa=load_alexa()
dga=load_dga()
x=alexa+dga
y=[0]*len(alexa)+[1]*len(dga)
- 特征提取(分别采用四种算法)
# N-gram
ngram_range = (2, 2)
vectorizer_ngram = CountVectorizer(analyzer='char', ngram_range=ngram_range)
X_ngram = vectorizer_ngram.fit_transform(x)
# Bag of Words
vectorizer_bow = CountVectorizer()
X_bow = vectorizer_bow.fit_transform(x)
# TF-IDF
vectorizer_tfidf = TfidfVectorizer()
X_tfidf = vectorizer_tfidf.fit_transform(x)
# Word2Vec
sentences = [domain.split('.') for domain in x]
model = Word2Vec(sentences, min_count=1)
X_word2vec = model.wv.vectors
# Adjust the sample size of Word2Vec feature
sample_size_word2vec = X_word2vec.shape[0]
indices = np.random.choice(sample_size_word2vec, len(y))
X_word2vec = X_word2vec[indices]
- 划分训练/测试集,并确定训练模型
from sklearn.linear_model import LogisticRegression
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score, classification_report
# Split the data into training and testing sets
X_train_ngram, X_test_ngram, y_train, y_test = train_test_split(X_ngram, y, test_size=0.2, random_state=42)
X_train_bow, X_test_bow, _, _ = train_test_split(X_bow, y, test_size=0.2, random_state=42)
X_train_tfidf, X_test_tfidf, _, _ = train_test_split(X_tfidf, y, test_size=0.2, random_state=42)
X_train_word2vec, X_test_word2vec, _, _ = train_test_split(X_word2vec, y, test_size=0.2, random_state=42)
# Initialize models
models = {
'Logistic Regression': LogisticRegression(),
'Random Forest': RandomForestClassifier()
}
- 各算法迭代训练,并存储结果:
# Fit and evaluate models for each feature
# Dictionary to store results
results = {}
# Fit and evaluate models for each feature
for feature, X_train, X_test in zip(['n-gram', 'Bag of Words', 'TF-IDF', 'Word2Vec'],
[X_train_ngram, X_train_bow, X_train_tfidf, X_train_word2vec],
[X_test_ngram, X_test_bow, X_test_tfidf, X_test_word2vec]):
print(f"Evaluation for {feature}:")
results[feature] = {}
for model_name, model in models.items():
model.fit(X_train, y_train)
y_pred = model.predict(X_test)
accuracy = accuracy_score(y_test, y_pred)
report = classification_report(y_test, y_pred, output_dict=True)
results[feature][model_name] = {'accuracy': accuracy, 'report': report}
print(f"{model_name} Accuracy: {accuracy:.4f}")
print(f"{model_name} Classification Report:")
print(classification_report(y_test, y_pred))
print("--------------------------")
- 结果可视化
import matplotlib.pyplot as plt
# Create a bar chart for each feature and model
plt.figure(figsize=(12, 8))
for i, feature in enumerate(results.keys()):
plt.subplot(2, 2, i+1)
models = list(results[feature].keys())
values = [results[feature][model]['accuracy'] for model in models]
plt.bar(models, values, color=['b', 'r'])
plt.title(f'Performance for {feature}')
plt.xlabel('Models')
plt.ylabel('Accuracy')
plt.ylim(0, 1.0) # Set the y-axis limit to 0-1
plt.xticks(rotation=45)
plt.tight_layout()
plt.show()
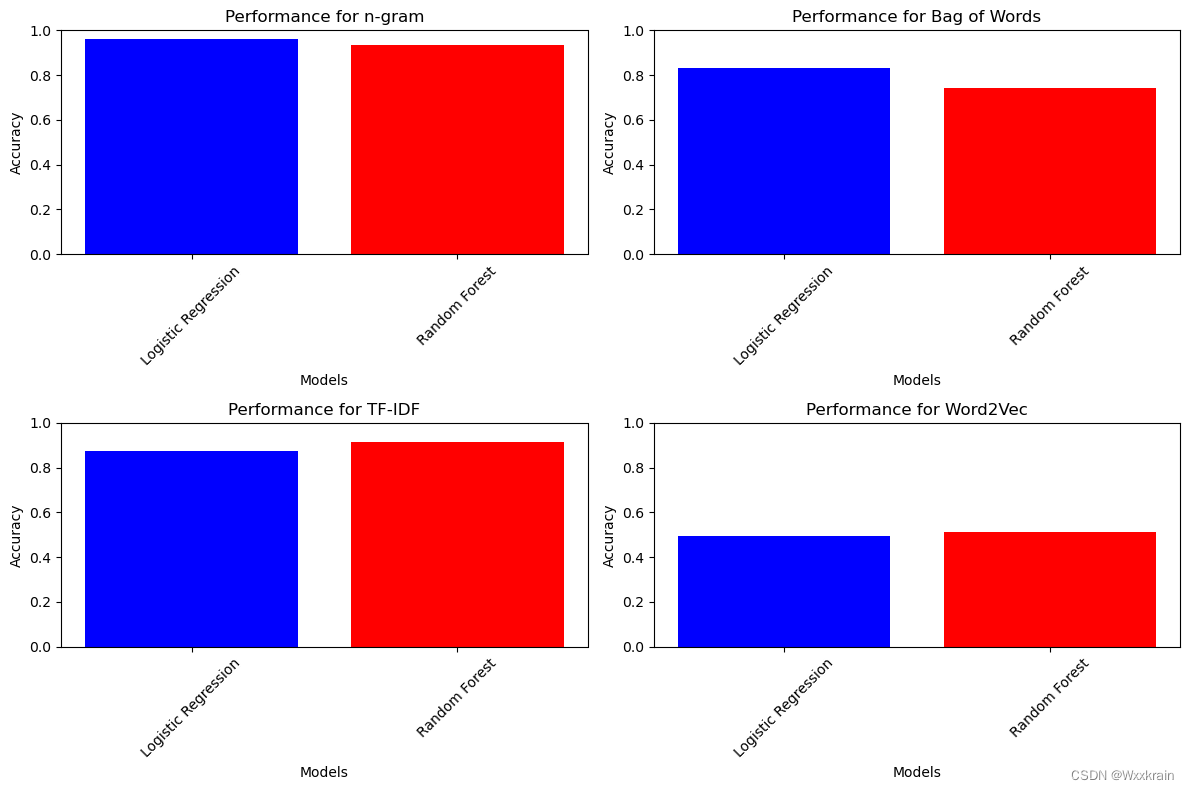
3. 结果分析
-
n-gram模型的表现: 使用n-gram特征提取方法的逻辑回归和随机森林模型均表现出较高的准确性(0.9625)。它们的精确率、召回率和F1分数也都很接近,表明模型在预测恶意域名和正常域名时具有很高的准确性和稳定性。
-
Bag of Words模型的表现: 使用词袋模型的逻辑回归和随机森林模型的准确性较低(0.8320和0.7412)。由于收敛警告和精确率、召回率以及F1分数的差异较大,可能是由于数据特征的复杂性或模型参数配置不当导致的。
-
TF-IDF模型的表现: TF-IDF特征提取方法与逻辑回归和随机森林模型相结合,获得了较高的准确性(0.8752和0.9140)。分类报告中的精确率、召回率和F1分数都相对较高,显示出模型对正常域名和恶意域名的识别能力较强。
-
Word2Vec模型的表现: Word2Vec特征提取方法结合逻辑回归和随机森林模型的准确性相对较低(0.4945和0.5090)。精确率、召回率和F1分数也较低,可能是因为Word2Vec无法很好地捕捉到域名的特征,导致模型性能下降。
综合来看,不同特征提取方法对模型性能有着显著的影响。n-gram和TF-IDF方法在域名检测任务中表现较好,而词袋模型和Word2Vec方法则表现较差。这些结果提醒着我们在选择特征提取方法时需考虑数据特点和任务要求,以及在模型训练过程中需谨慎调整参数,以获得更好的性能。















 266
266











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









