






作业任务
选择恶意和正常URL链接数据进行研究(特征选择、算法选择),并编写代码构建模型,最终满足如下需求:
- 打印出模型的准确率和召回率;
- 代码可以根据输入的URL自动判定其安全性;
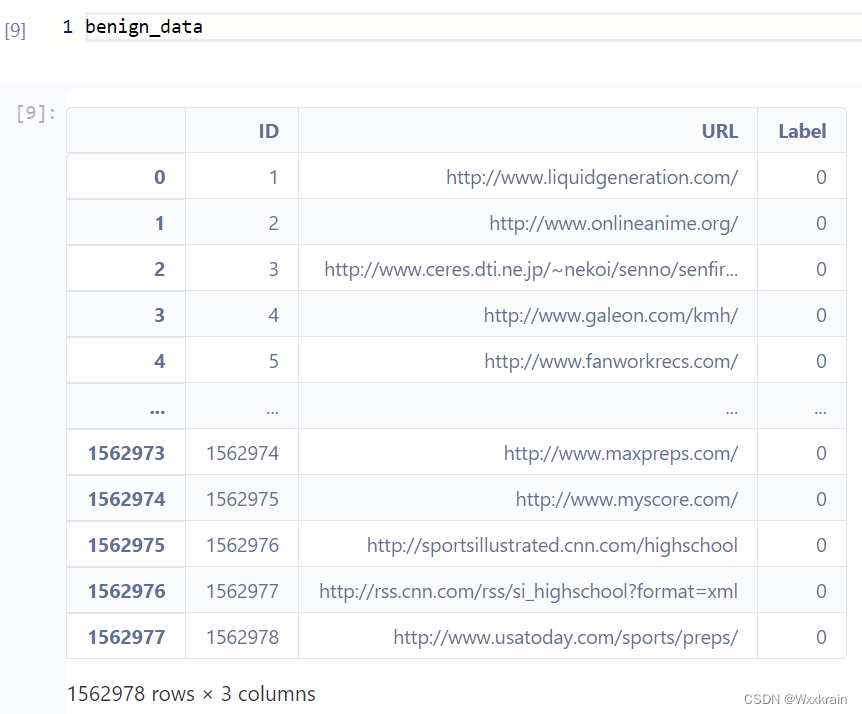
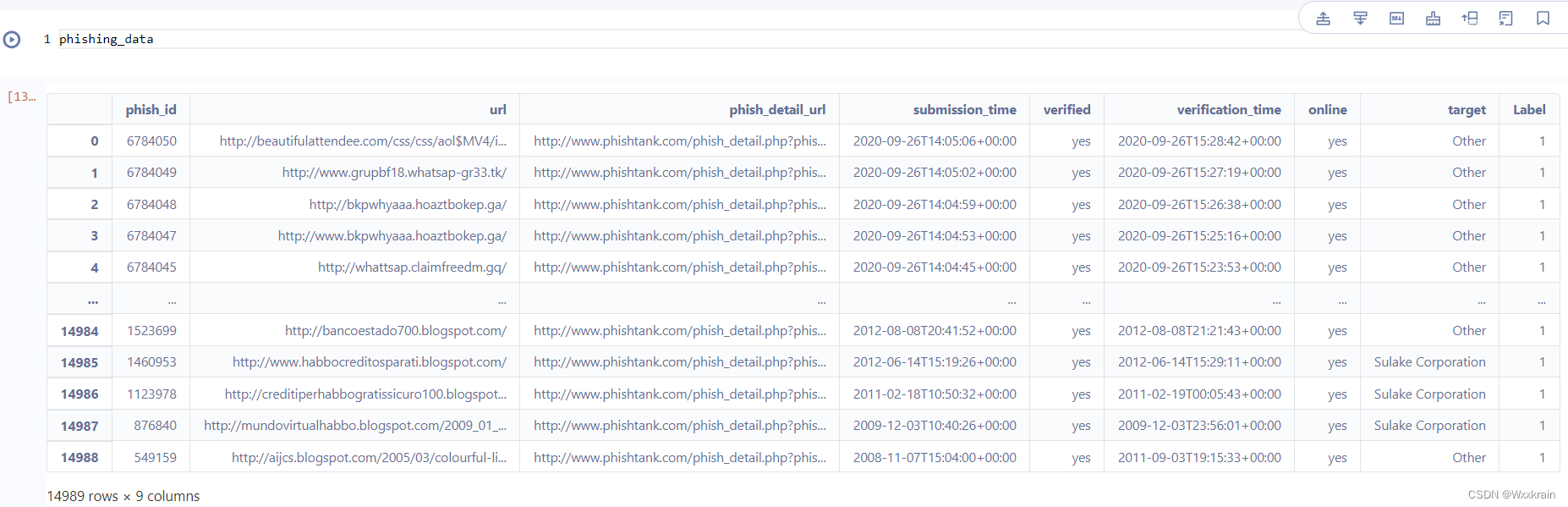
数据集
benign/phishing data,两个csv文件:
Label列是自己添加的,benign为0,phishing为1
钓鱼网址数据来源
属性解释:
网址相关知识
href= protocol + hostname+ port+ pathname+ parameter+ fragment
protocol: http, https(双斜杠)
hostname: 主机域名+二级域名(+多级域名)
port: 默认80且隐藏
pathname: 文件所在子目录
param: 参数(动/静态网址)
fragment: 当前片段标识符
如何区分特征
表层特征:
- 从字符/数字组成元素
- 从整体字符的长度
- 从各组成部分是否都存在(例如:是否存在瞄点)
- 网址文件后缀语义(静态/动态、可执行文件、视频…)
深层特征: - 分词、单词数量
- 信息熵 (字符复杂度)
- 单词语义及前后关系、单词是否常用词
- 从域名后缀,代表含义 (edu:教育、com:商业、…)
机器学习中常用特征以及代码实现
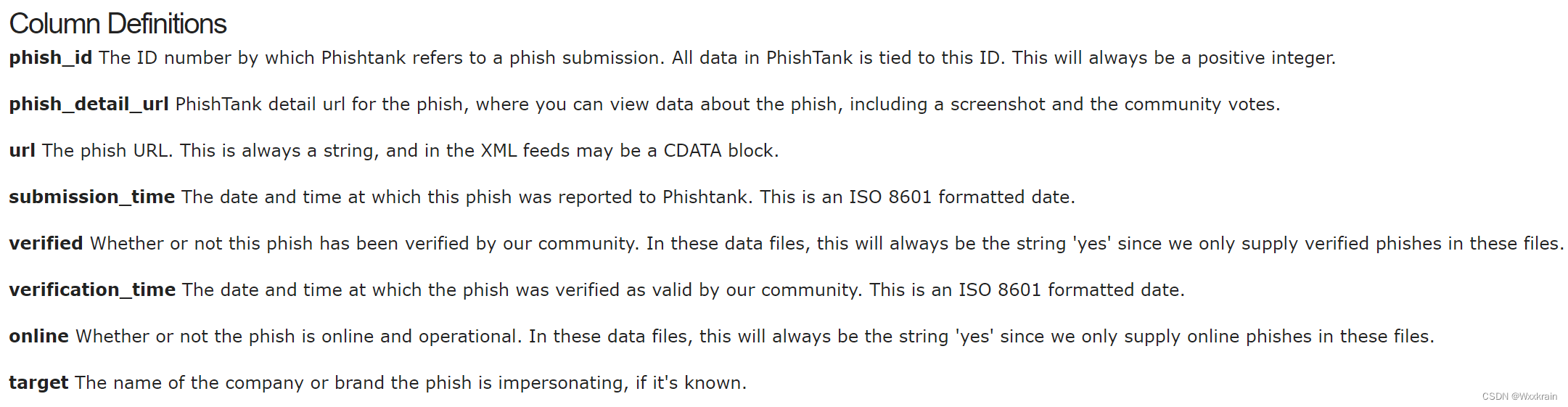
参考论文:Pratiwi M E, Lorosae T A, Wibowo F W. Phishing site detection analysis using artificial neural network[C]//Journal of Physics: Conference Series. IOP Publishing, 2018, 1140(1): 012048.
链接:https://iopscience.iop.org/article/10.1088/1742-6596/1140/1/012048/pdf
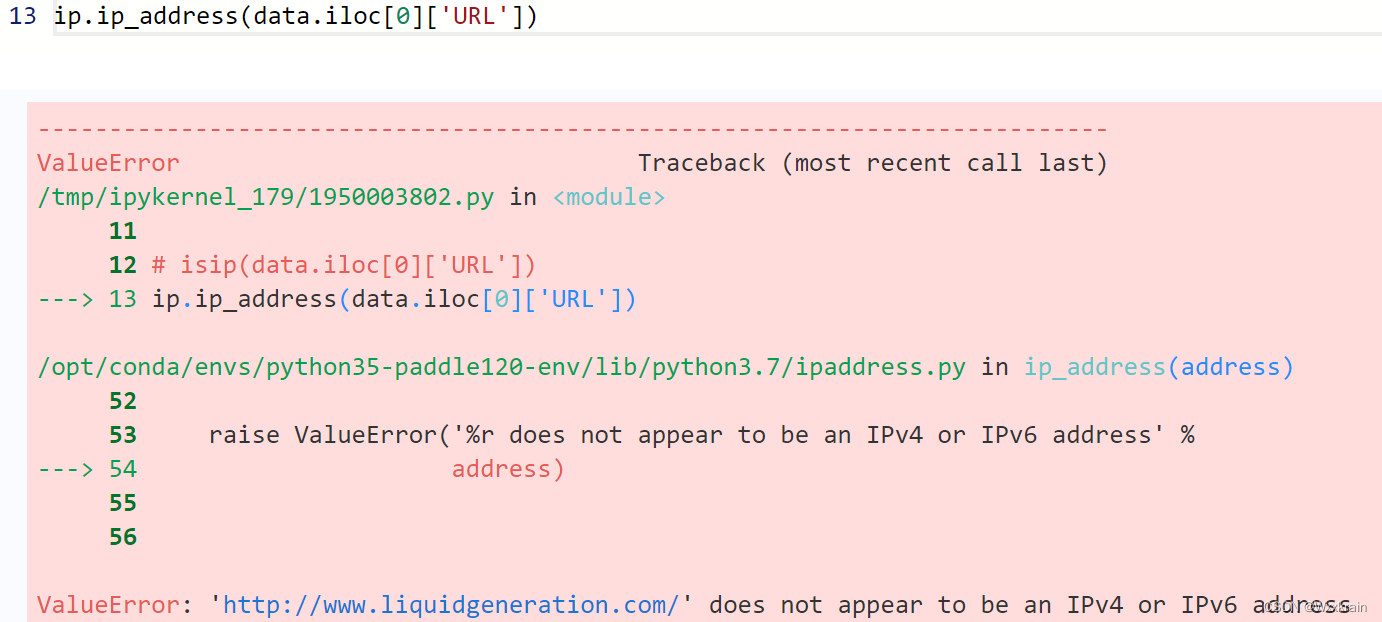
- having_IP_Address{ -1,1 }
# Is IP addr present as the hostname
import ipaddress as ip
def isip(uri):
try:
if ip.ip_address(uri):
return 1
except:
return 0
如果不是IPv4/IPv6地址时会报错,返回0
- URL_Length{ 1,0,-1 }
# URL_Length{ 1,0,-1 }
def url_len(url):
length = len(url)
if length < 54:
return -1
elif length < 75:
return 0
else:
return 1
- Shortining_Service{ 1,-1 }
是否使用了url缩短服务
def shorten_service(url):
match = re.search('bit\.ly|goo\.gl|shorte\.st|go2l\.ink|x\.co|ow\.ly|t\.co|tinyurl|tr\.im|is\.gd|cli\.gs|'
'yfrog\.com|migre\.me|ff\.im|tiny\.cc|url4\.eu|twit\.ac|su\.pr|twurl\.nl|snipurl\.com|'
'short\.to|BudURL\.com|ping\.fm|post\.ly|Just\.as|bkite\.com|snipr\.com|fic\.kr|loopt\.us|'
'doiop\.com|short\.ie|kl\.am|wp\.me|rubyurl\.com|om\.ly|to\.ly|bit\.do|t\.co|lnkd\.in|'
'db\.tt|qr\.ae|adf\.ly|goo\.gl|bitly\.com|cur\.lv|tinyurl\.com|ow\.ly|bit\.ly|ity\.im|'
'q\.gs|is\.gd|po\.st|bc\.vc|twitthis\.com|u\.to|j\.mp|buzurl\.com|cutt\.us|u\.bb|yourls\.org|'
'x\.co|prettylinkpro\.com|scrnch\.me|filoops\.info|vzturl\.com|qr\.net|1url\.com|tweez\.me|v\.gd|'
'tr\.im|link\.zip\.net',
url)
if match:
return 1
else:
return -1
- having_At_Symbol{ 1,-1 }
在 URL 中使用“@”符号会导致浏览器忽略“@”符号之前的所有内容,而真实地址通常位于“@”符号之后。
# Function to check if URL has '@' symbol
def having_At_Symbol(url):
if '@' in url:
return 1
else:
return -1
- double_slash_redirecting{ -1,1 }
双斜杠或“//”表示用户或用户将被重定向到另一个站点。双斜杠的使用位置通常出现在第六个位置,如链接 http://amikom.ac.id 中所写。但是,如果双斜线出现在第七个位置,即 https://amikom.ac.id,则可能会被怀疑是网络钓鱼站点。

# Function to check for double slash redirecting
def double_slash_redirecting(url):
if url.find('//') > 7:
return 1
else:
return -1
- Prefix_Suffix{ -1,1 }
钓鱼网址通常使用-连接前后缀伪装,例如http://www.amikom-keren.com.
# Function to check for Prefix Suffix
def Prefix_Suffix(url):
if '-' in url:
return 1
else:
return -1
- Having_Sub_Domains{-1,0,1}
域名可能有每个国家/地区的代码(cc TLD),例如“id”,或学术教育机构的“ac”和组合的“ac.id”,也称为二级域(SLD)。提取特征的阶段首先要做的是删除 URL 中的“www”并删除 cc DTL(如果有)。然后计算剩余的点,如果点的数量大于1,则该URL可以被归类为“可疑”,因为只有子域。但是,如果点数大于两个,则它将被归类为网络钓鱼,因为它有多个子域,如果没有子域,则站点被归类为合法网站。

# Function to classify URL based on the number of dots in the domain part
def remove_subdomain_ccDTL(url):
global domain
if domain.startswith("www."):
domain = domain[4:]
domain_segments = domain.split(".")
ccSLDs = ["ac", "co", "gov", "mil", "edu", "org", "net", "int"]
ccTLDs = ["uk", "us", "ca", "au", "fr", "br", "de", "jp", "cn", "in", "ru", "za", "ch", "nl", "se"]
if len(domain_segments) >= 2 and domain_segments[-1] in ccTLDs:
domain_segments.pop()
if len(domain_segments) >= 2 and domain_segments[-1] in ccSLDs:
domain_segments.pop()
dots_in_domain = len(domain_segments) - 1
if dots_in_domain <= 1:
return -1
elif dots_in_domain == 2:
return 0
else:
return 1
- HTTPS{-1,0,1}

# Function to check HTTPS with trusted issuer
def check_https_with_trusted_issuer(url):
global parsed_url
is_https = parsed_url.scheme == "https"
trusted_issuers = ["DigiCert", "Let's Encrypt", "Comodo", "Symantec"]
if is_https:
try:
cert_info = ssl.get_server_certificate((parsed_url.hostname, 443))
x509 = ssl.PEM_cert_to_DER_cert(cert_info)
cert = ssl.DER_cert_to_PEM_cert(x509)
issuer_info = None
for line in cert.split("\n"):
if line.startswith("issuer"):
issuer_info = line[len("issuer="):].strip()
break
if issuer_info and any(trusted in issuer_info for trusted in trusted_issuers):
cert_data = ssl.get_certificate(parsed_url.hostname)
cert_start_date = datetime.datetime.strptime(cert_data.get_notBefore().decode(), "%Y%m%d%H%M%SZ")
cert_end_date = datetime.datetime.strptime(cert_data.get_notAfter().decode(), "%Y%m%d%H%M%SZ")
cert_validity_years = (cert_end_date - cert_start_date).days / 365.0
if cert_validity_years >= 1:
return -1
else:
return 0
except Exception as e:
pass
return 1
- Domain Registration Length{-1,1}
属于钓鱼网站,有效期短,使用期限为一年。

# Function to check domain registration length
def check_domain_registration_length(url):
global domain
domain_info = whois.whois(domain)
try:
domain_info = whois.whois(domain)
expiration_date = domain_info.expiration_date
today = datetime.datetime.now()
if isinstance(expiration_date, list):
expiration_date = min(expiration_date)
if expiration_date is not None:
days_until_expiration = (expiration_date - today).days
if days_until_expiration <= 365:
return 1
else:
return -1
else:
return 0
except Exception as e:
return 0
- Favicon{-1, 1}
Favicon是在网站上用作图标的图像,favicon也表明了网站的身份。但如果地址栏中的图标分开显示,则可以怀疑该网站是钓鱼网站。

# Function to check favicon
def check_Favicon(url):
global parsed_url, soup
try:
favicon_tag = soup.find("link", rel="icon")
if favicon_tag:
favicon_url = favicon_tag.get("href")
parsed_favicon_url = urlparse(favicon_url)
if parsed_favicon_url.netloc != '' and parsed_url.netloc != parsed_favicon_url.netloc:
return 1
return -1
except Exception as e:
return 0
- Port{-1, 1}
用于验证某些服务(例如 HTTP)的端口。利用防火墙、代理、网络地址转换或NAT可以进行自动封锁,并可以按照意愿开放。但如果所有端口都打开,网络钓鱼者就会发现漏洞并启用任何所需的服务,例如窃取信息。

预测结果
whois查询会很慢,一直到timeout,并且很多网址已失效都返回None

使用soup分析html的几个属性也非常慢,几十个训练样本就需要十分钟来提取特征
# Function to check request URL
def request_url(url):
global parsed_url, domain, soup
try:
all_urls = [link.get("href") for link in soup.find_all(["a", "img", "script", "link"])]
main_domain = domain
same_domain_count = sum(1 for url in all_urls if urlparse(url).netloc == main_domain)
total_urls_count = len(all_urls)
percentage_same_domain = (same_domain_count / total_urls_count) * 100
if percentage_same_domain < 22:
return -1
elif 22 <= percentage_same_domain <= 61:
return 0
else:
return 1
except Exception as e:
return 0
# Function to check anchor URL
def anchor_url(url):
global parsed_url, domain, soup
try:
anchor_urls = [link.get("href") for link in soup.find_all("a")]
main_domain = domain
different_domain_count = sum(1 for url in anchor_urls if urlparse(url).netloc != main_domain)
total_anchor_count = len(anchor_urls)
percentage_different_domain = (different_domain_count / total_anchor_count) * 100
if percentage_different_domain < 31:
return -1
elif 31 <= percentage_different_domain <= 67:
return 0
else:
return 1
except Exception as e:
return 0
# Function to check links in tags
def links_in_tags(url):
global parsed_url, domain, soup
try:
meta_tags = soup.find_all("meta")
script_tags = soup.find_all("script")
link_tags = soup.find_all("link")
main_domain = domain
links_count = sum(1 for tag in (meta_tags + script_tags + link_tags) if urlparse(tag.get("src", "")).netloc == main_domain)
total_links_count = len(meta_tags) + len(script_tags) + len(link_tags)
percentage_links_in_tags = (links_count / total_links_count) * 100
if percentage_links_in_tags < 17:
return -1
elif 17 <= percentage_links_in_tags <= 81:
return 0
else:
return 1
except Exception as e:
return 0
# Function to check server form handler (SFH)
def sfh(url):
global parsed_url, domain, soup
try:
sfh_value = ""
form_tag = soup.find("form")
if form_tag:
sfh_value = form_tag.get("action", "")
main_domain = domain
sfh_parsed_url = urlparse(sfh_value)
sfh_domain = sfh_parsed_url.netloc if sfh_parsed_url.netloc else main_domain
if sfh_value == "about:blank" or sfh_value == "":
return 1
elif sfh_domain != main_domain:
return 0
else:
return -1
except Exception as e:
return 0
# Function to check submitting to email
def submitting_to_email(url):
global soup
try:
script_tags = soup.find_all("script")
for script in script_tags:
script_text = script.get_text()
if "mail()" in script_text or "mailto:" in script_text:
return 1
return -1
except Exception as e:
return 0
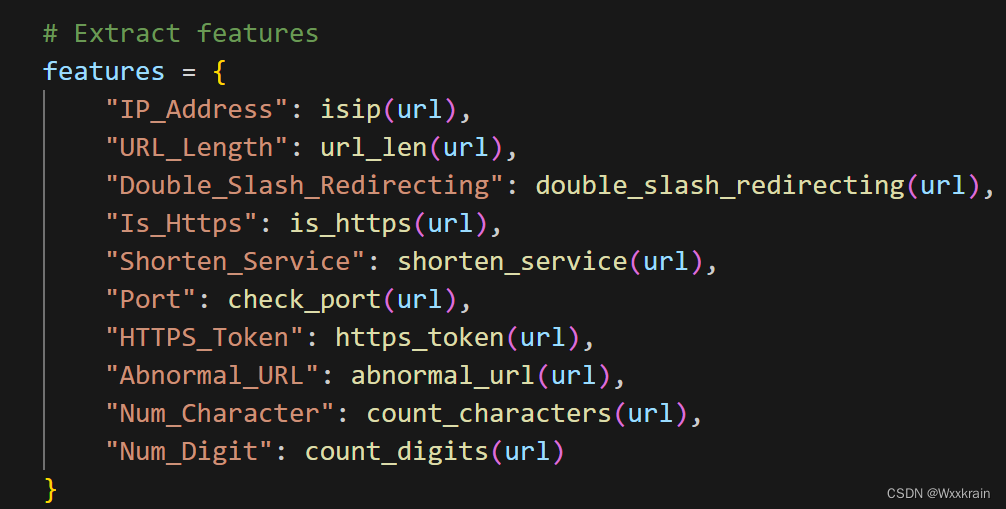
如果只保留与html无关的属性,几百个样本或者几万个样本的提取特征速度非常快,准确率最高0.91:
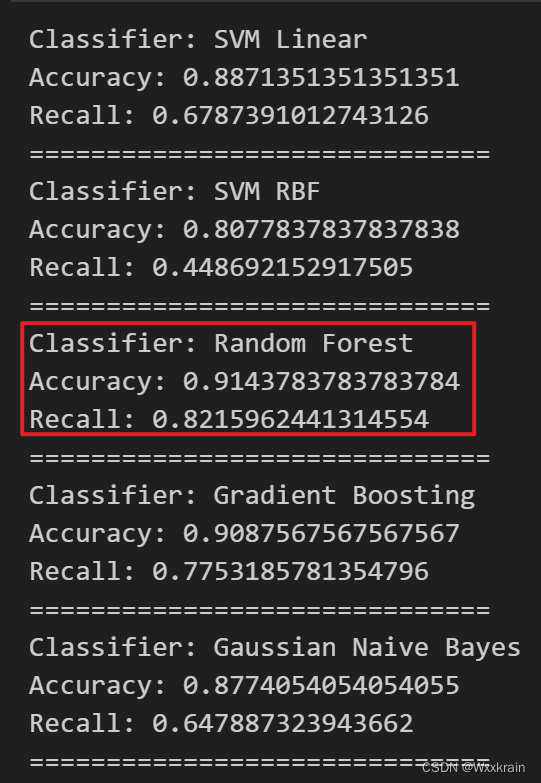
添加了与html相关的属性速度非常慢,但是准确率有提升
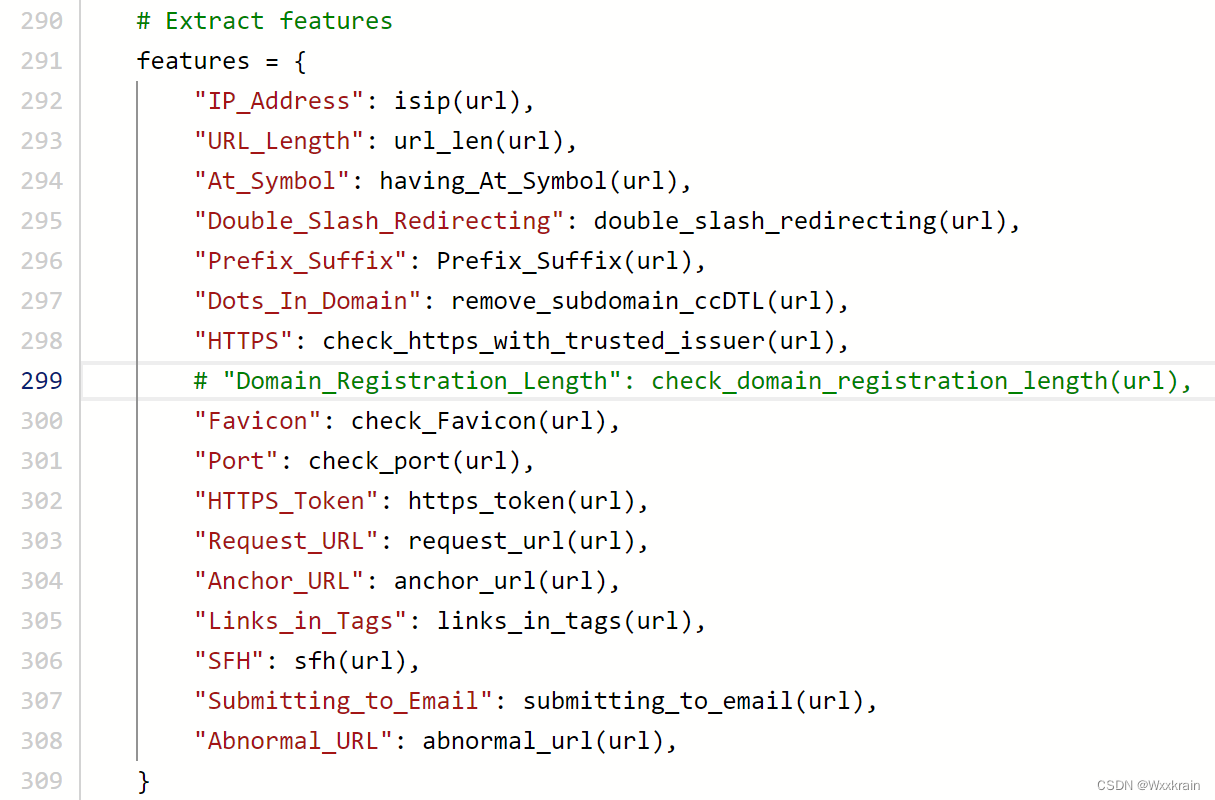
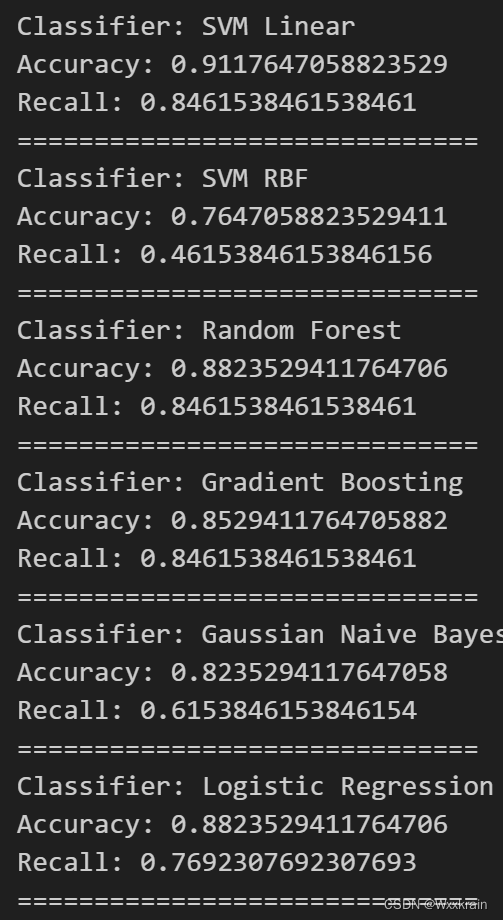
【有一次准确率有100%,后来不知道哪里没保存,这结果再也找不到了】

















 4054
4054

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









