






XSS攻击基础知识
推荐阅读:
OWASP Cross Site Scripting (XSS)
这一次,彻底理解XSS攻击
如何区分
表层特征:
- < / >
- script, SCRIPT, Script, JavaScript, javascript
- style, iframe
- 97, 108, \x60, (
- …
深层特征:
- 语法是否正确
- 属性值是否合规
- 长度是否合适
- 标签是否允许
- 编码方式是否过多
- …
基于机器学习的XSS分类
数据集
论文:Deepxss: Cross site scripting detection based on deep learning
数据集:https://github.com/das-lab/deep-xss
文本预处理和分词
数据读取和预处理:为每个样本添加了一个标签,0表示正常数据,1表示XSS攻击数据。最后,使用GeneSeg函数对数据中的payload进行分词处理,并将分词结果存储在新的’words’列中。
from collections import Counter
from gensim.models.word2vec import Word2Vec
normal_data = pd.read_csv("dmzo_normal.csv", names=['payload']).sample(frac=0.1)
xssed_data = pd.read_csv("xssed.csv", names=['payload']).sample(frac=0.1)
normal_data['label'] = 0
xssed_data['label'] = 1
data = pd.concat([normal_data, xssed_data])
data['words'] = data['payload'].map(GeneSeg)
GeneSeg()函数:这个函数负责对输入的payload进行预处理和分词操作。首先,它将payload转换为小写形式,这样可以使文本中的大小写保持一致。然后,它使用Python标准库中的urllib模块的unquote函数对URL进行解码操作。接着,它使用正则表达式对数字进行泛化处理,将所有数字替换为"0",将URL替换为"http://u"。最后使用nltk库中的regexp_tokenize函数对文本进行分词处理。
def GeneSeg(payload):
#数字泛化为"0"
payload=payload.lower()
payload=unquote(unquote(payload))
payload,num=re.subn(r'\d+',"0",payload)
#替换url为”http://u
payload,num=re.subn(r'(http|https)://[a-zA-Z0-9\.@&/#!#\?]+', "http://u", payload)
#分词
r = '''
(?x)[\w\.]+?\(
|\)
|"\w+?"
|'\w+?'
|http://\w
|</\w+>
|<\w+>
|<\w+
|\w+=
|>
|[\w\.]+
'''
return nltk.regexp_tokenize(payload, r)
Word2Vec模型训练
构建词汇表:在这部分中,通过统计所有数据中出现的词汇及其出现的频率,提取出现次数最多的3000个词汇构建了一个词汇表。词汇表以Python字典的形式存储,其中词汇为键,索引为值。
# 展开词汇列表
all_words = [word for sublist in data[data['label'] == 1]['words'] for word in sublist]
# 统计词频
word_counts = Counter(all_words)
# 选取出现次数最多的3000个词汇构建词汇表
top_words = [word for word, count in word_counts.most_common(vocabulary_size)]
# 构建词汇表
vocab = {word: idx for idx, word in enumerate(top_words)} # 构建词汇表
# 根据词汇表替换词汇列表中的词汇
processed_words = [[word if word in vocab else 'UNK' for word in sublist] for sublist in data[data['label'] == 1]['words']]
Word2Vec模型训练:
使用Gensim中的Word2Vec模型对经过处理后的数据进行词向量训练。该模型将词汇映射到一个连续向量空间,从而使得具有相似语义的词在向量空间中的距离也比较近。
model = Word2Vec(processed_words,vector_size=embedding_size,window=skip_window,negative=num_sampled,epochs=num_iter)
embeddings = model.wv
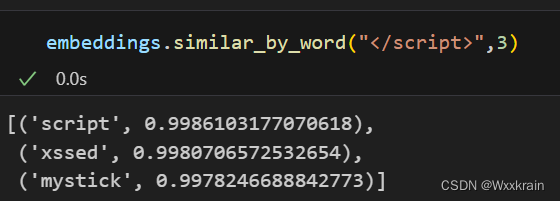
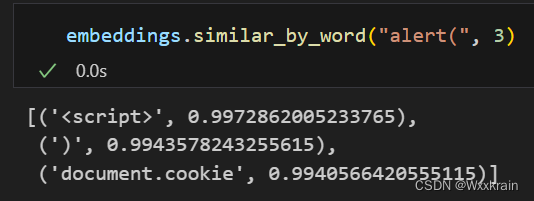
LSTM模型训练
数据准备:
使用TensorFlow的Keras API将文本序列转换为数值序列,并对序列进行了填充操作,使得所有序列具有相同的长度。同时,将标签转换为适当的格式,以便模型可以进行训练和预测。
# 准备数据
tokenizer = tf.keras.preprocessing.text.Tokenizer()
tokenizer.fit_on_texts(data['words'])
word_index = tokenizer.word_index
X = tokenizer.texts_to_sequences(data['words'])
X = pad_sequences(X)
# 处理标签
Y = np.array(data['label'])
# 划分训练集和测试集
X_train, X_test, Y_train, Y_test = train_test_split(X, Y, test_size=0.2, random_state=42)
构建LSTM模型:
在这部分中,使用TensorFlow的Keras API构建了一个简单的LSTM模型。该模型包括嵌入层、空间Dropout层、LSTM层以及最终的密集层。这些层被串联起来以构建一个完整的LSTM模型。
# 构建LSTM模型
model = Sequential()
model.add(Embedding(len(word_index) + 1, 128, input_length=X.shape[1]))
model.add(SpatialDropout1D(0.2))
model.add(LSTM(100, dropout=0.2, recurrent_dropout=0.2))
model.add(Dense(1, activation='sigmoid'))
模型编译和训练:
在这一部分中,编译了LSTM模型,并使用训练集对模型进行了训练。模型的损失函数采用了二元交叉熵(binary_crossentropy),优化器采用了Adam优化器,并且监测了模型的准确率(accuracy)指标。
# 编译模型
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# 训练模型
model.fit(X_train, Y_train, epochs=3, batch_size=16, validation_data=(X_test, Y_test))

模型评估:
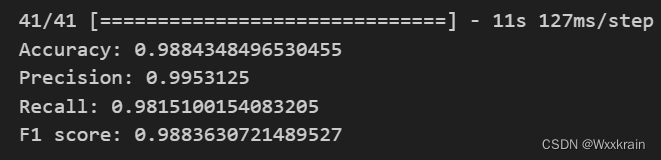
在这部分中,对训练好的模型进行了评估,并计算了模型的准确率、精确度、召回率和F1分数。
# 进行预测
y_pred = model.predict(X_test)
y_pred = (y_pred > 0.5).astype(int)
# 进行评估
from sklearn.metrics import accuracy_score, precision_score, recall_score, f1_score
accuracy = accuracy_score(Y_test, y_pred)
precision = precision_score(Y_test, y_pred)
recall = recall_score(Y_test, y_pred)
f1 = f1_score(Y_test, y_pred)
print(f'Accuracy: {accuracy}')
print(f'Precision: {precision}')
print(f'Recall: {recall}')
print(f'F1 score: {f1}')















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









