







目录
复习日
一、作业
尝试找到一个kaggle或者其他地方的结构化数据集,用之前的内容完成一个全新的项目,完成了一个专属于自己的项目。
葡萄酒品质分类项目——数据集链接:Wine Quality Classification | Kaggle
该合成数据集专为葡萄酒品质分类任务而设计。它包含 1000 个葡萄酒样本,包含酸度、糖度、酒精度和密度等关键化学属性。每个样本都标有葡萄酒品质等级:低、中、高。
使用此数据集可以:
- 训练分类模型,例如 SVM、XGBoost 和 Logistic 回归
- 探索化学特征对葡萄酒品质的影响
- 在食品和饮料环境中练习机器学习任务
特征:
- Fixed_acidity:固定酸度等级
- residual_sugar:发酵后的糖含量
- 酒精度:酒精含量(%)
- 密度:液体密度
- quality_label:葡萄酒品质等级(低/中/高)
环境准备:
# === 环境准备 ===
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
from sklearn.model_selection import train_test_split
from sklearn.preprocessing import LabelEncoder, StandardScaler, OneHotEncoder
from sklearn.cluster import KMeans, DBSCAN
from sklearn.impute import SimpleImputer
from sklearn.compose import ColumnTransformer
from sklearn.pipeline import Pipeline
from imblearn.over_sampling import SMOTE
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.ensemble import RandomForestClassifier
from sklearn.model_selection import GridSearchCV
from sklearn.metrics import classification_report, roc_auc_score
import shap1. 数据加载与问题识别
# === 步骤1:数据加载与问题识别 ===
# 读取数据
df = pd.read_csv("wine_quality_classification.csv")
print("步骤1结果:")
print("数据集前5行:\n", df.head())
print("\n数据类型统计:\n", df.dtypes)
print("\n目标变量分布:\n", df['quality_label'].value_counts())
# 识别为分类问题(quality_label为离散类别)
features = ['fixed_acidity', 'residual_sugar', 'alcohol', 'density']
target = 'quality_label'
输出结果:
步骤1结果:
数据集前5行:
fixed_acidity residual_sugar alcohol density quality_label
0 9.3 6.4 13.6 1.0005 high
1 11.2 2.0 14.0 0.9912 medium
2 11.6 0.9 8.2 0.9935 low
3 12.9 6.6 12.7 1.0002 low
4 13.9 13.8 10.4 0.9942 medium
数据类型统计:
fixed_acidity float64
residual_sugar float64
alcohol float64
density float64
quality_label object
dtype: object
目标变量分布:
quality_label
medium 355
high 343
low 302
Name: count, dtype: int64
2. 数据预处理
# === 步骤2:数据预处理 ===
# 2-① 异常值处理
print("\n步骤2-①:异常值处理")
# 连续特征异常值检测(箱线图)
plt.figure(figsize=(12,6))
df[features].boxplot()
plt.title('Boxplot of Continuous Features')
plt.show()
# 定义异常值替换函数
def replace_outliers(df, cols):
for col in cols:
Q1 = df[col].quantile(0.25)
Q3 = df[col].quantile(0.75)
IQR = Q3 - Q1
lower_bound = Q1 - 1.5 * IQR
upper_bound = Q3 + 1.5 * IQR
df[col] = np.where((df[col] < lower_bound) | (df[col] > upper_bound), np.nan, df[col])
return df
df = replace_outliers(df, features)
print("异常值替换后的缺失值统计:\n", df.isnull().sum())
# 2-② 缺失值填补
print("\n步骤2-②:缺失值填补")
imputer = SimpleImputer(strategy='most_frequent')
df[features] = imputer.fit_transform(df[features])
print("缺失值填补完成")
# 2-③ 离散特征编码
print("\n步骤2-③:标签编码")
le = LabelEncoder()
df[target] = le.fit_transform(df[target]) # 转换为数值标签输出结果:
步骤2-①:异常值处理
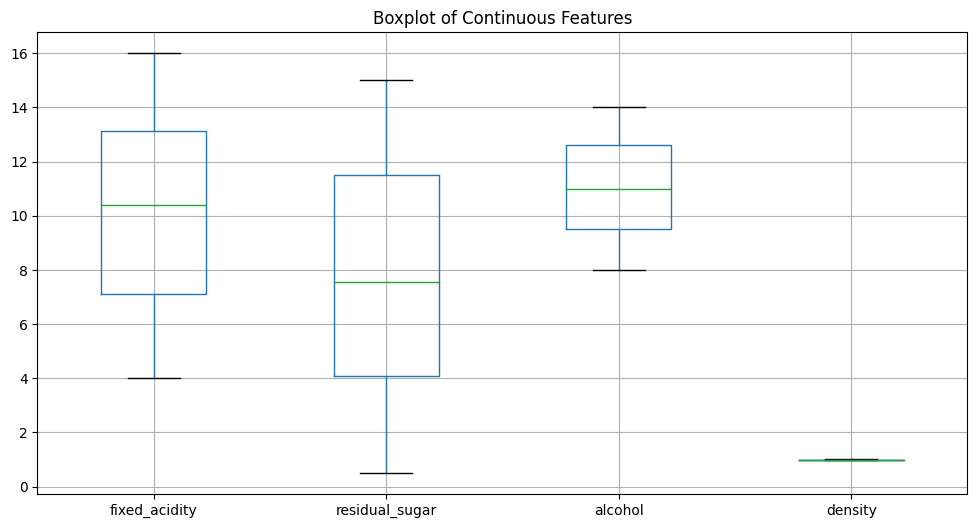
异常值替换后的缺失值统计:
fixed_acidity 0
residual_sugar 0
alcohol 0
density 0
quality_label 0
dtype: int64
步骤2-②:缺失值填补
缺失值填补完成
步骤2-③:标签编码
3. 特征工程
# === 步骤3:特征工程 ===
print("\n步骤3:特征工程")
# 划分训练测试集(提前划分以防止数据泄露)
X_train, X_test, y_train, y_test = train_test_split(df[features], df[target], test_size=0.2, random_state=42)
# 聚类特征生成(仅在训练集操作)
def add_cluster_features(X):
# KMeans聚类
kmeans = KMeans(n_clusters=3, random_state=42)
kmeans_cluster = kmeans.fit_predict(X)
X['kmeans_cluster'] = kmeans_cluster
# 计算到质心的距离
distances = kmeans.transform(X[features])
X['distance_to_centroid'] = np.min(distances, axis=1)
# DBSCAN聚类
dbscan = DBSCAN(eps=0.5, min_samples=5)
dbscan_cluster = dbscan.fit_predict(X[features])
X['dbscan_cluster'] = dbscan_cluster
return X
X_train = add_cluster_features(X_train.copy())
X_test = add_cluster_features(X_test.copy())
print("新增特征后的训练集列名:", X_train.columns.tolist())输出结果:
步骤3:特征工程
新增特征后的训练集列名: ['fixed_acidity', 'residual_sugar', 'alcohol', 'density', 'kmeans_cluster', 'distance_to_centroid', 'dbscan_cluster']
The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
The default value of `n_init` will change from 10 to 'auto' in 1.4. Set the value of `n_init` explicitly to suppress the warning
4. 数据划分与平衡处理
# === 步骤4:数据划分与平衡处理 ===
print("\n步骤4:数据平衡处理")
# 检查标签分布
print("原始标签分布:\n", pd.Series(y_train).value_counts())
# 过采样处理
smote = SMOTE(random_state=42)
X_train_res, y_train_res = smote.fit_resample(X_train, y_train)
print("过采样后标签分布:\n", pd.Series(y_train_res).value_counts())输出结果:
步骤4:数据平衡处理
原始标签分布:
quality_label
2 288
0 272
1 240
Name: count, dtype: int64
过采样后标签分布:
quality_label
1 288
0 288
2 288
Name: count, dtype: int64
5. 模型训练与评估
# === 步骤5:模型训练与评估 ===
print("\n步骤5:模型训练")
# 数据标准化
scaler = StandardScaler()
X_train_scaled = scaler.fit_transform(X_train_res)
X_test_scaled = scaler.transform(X_test)
# 定义模型与参数网格
models = {
"LogisticRegression": {
"model": LogisticRegression(),
"params": {'C': [0.1, 1, 10], 'solver': ['lbfgs', 'saga']}
},
"RandomForest": {
"model": RandomForestClassifier(),
"params": {'n_estimators': [100, 200], 'max_depth': [None, 5]}
},
"SVM": {
"model": SVC(probability=True),
"params": {'C': [0.1, 1], 'kernel': ['linear', 'rbf']}
}
}
# 网格搜索与交叉验证
best_models = {}
for name, config in models.items():
gs = GridSearchCV(config["model"], config["params"], cv=5, scoring='roc_auc_ovr')
gs.fit(X_train_scaled, y_train_res)
best_models[name] = gs.best_estimator_
print(f"{name}最佳参数:{gs.best_params_} | 验证集AUC:{gs.best_score_:.4f}")
# 模型评估
print("\n测试集评估:")
for name, model in best_models.items():
y_pred = model.predict(X_test_scaled)
auc = roc_auc_score(y_test, model.predict_proba(X_test_scaled), multi_class='ovr')
print(f"{name}的AUC:{auc:.4f}")
print(classification_report(y_test, y_pred, target_names=le.classes_))输出结果:
步骤5:模型训练
LogisticRegression最佳参数:{'C': 0.1, 'solver': 'lbfgs'} | 验证集AUC:0.5051
RandomForest最佳参数:{'max_depth': None, 'n_estimators': 100} | 验证集AUC:0.5626
SVM最佳参数:{'C': 1, 'kernel': 'rbf'} | 验证集AUC:0.5021
测试集评估:
LogisticRegression的AUC:0.4936
precision recall f1-score support
high 0.37 0.46 0.41 71
low 0.32 0.21 0.25 62
medium 0.31 0.33 0.32 67
accuracy 0.34 200
macro avg 0.33 0.33 0.33 200
weighted avg 0.34 0.34 0.33 200
RandomForest的AUC:0.5020
precision recall f1-score support
high 0.34 0.25 0.29 71
low 0.24 0.23 0.23 62
medium 0.36 0.48 0.41 67
accuracy 0.32 200
macro avg 0.31 0.32 0.31 200
weighted avg 0.32 0.32 0.31 200
SVM的AUC:0.5079
precision recall f1-score support
high 0.35 0.30 0.32 71
low 0.31 0.27 0.29 62
medium 0.36 0.46 0.41 67
accuracy 0.34 200
macro avg 0.34 0.34 0.34 200
weighted avg 0.34 0.34 0.34 2006. 可解释性分析
# === 步骤6:可解释性分析 ===
print("\n步骤6:SHAP分析")
# 使用效果最好的模型(假设随机森林最佳)
explainer = shap.TreeExplainer(best_models["RandomForest"])
shap_values = explainer.shap_values(X_test_scaled)
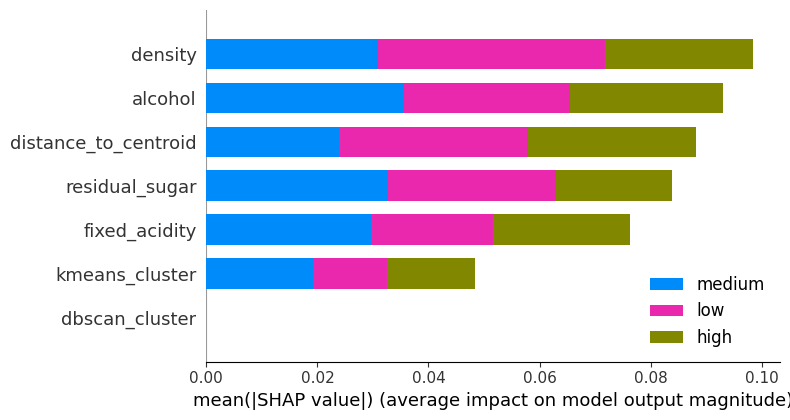
# 特征重要性条形图
shap.summary_plot(shap_values, X_test_scaled, feature_names=X_train.columns, class_names=le.classes_, plot_type="bar")
plt.title("SHAP Feature Importance")
plt.show()
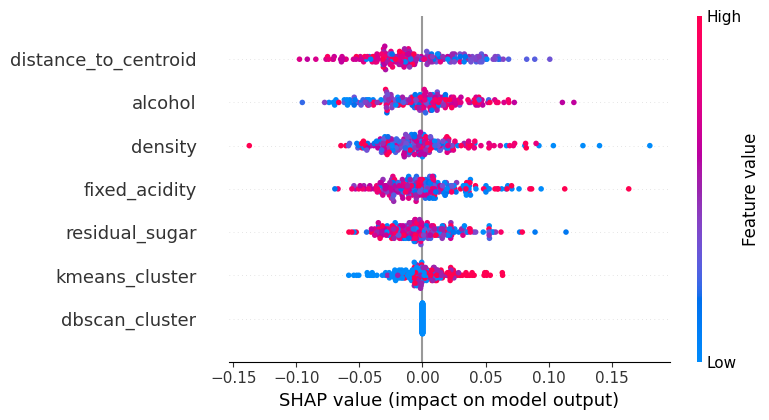
# 蜂巢图(单个类别示例)
shap.summary_plot(shap_values[0], X_test_scaled, feature_names=X_train.columns)
plt.title("SHAP Beeswarm Plot for Class 'Low'")
plt.show()输出结果:
①特征重要性条形图
②特征重要性蜂巢图
二、思考
1. 数据是否能够支撑研究?(数目与质量)
数目评估:
- 样本量:1000个样本对于简单的分类任务(如三分类)通常足够,但需注意:
- 模型复杂度:若使用复杂模型(如深度学习),可能需要更多数据避免过拟合。
- 特征维度:仅4个特征,数据量相对充足,但需确保特征与标签有强相关性。
质量评估:
- 合成数据局限性:
- 优点:通常无缺失值、噪声可控。
- 缺点:可能无法完全模拟真实数据分布(如极端值或非线性关系)。
- 验证建议:
- 检查特征范围(如酒精度是否在合理区间:通常葡萄酒酒精含量为9%-16%)。
- 分析标签分布是否均衡(低/中/高样本比例)。
- 通过EDA(如箱线图、相关性分析)验证特征与标签的逻辑关系。
2. 数据来源是否可靠?
可靠性判断依据:
- Kaggle平台:数据集通常有用户评分和讨论,需检查:
- 上传者背景(是否为领域专家或可信机构)。
- 数据描述是否详细(如生成方法、引用来源)。
- 合成数据生成逻辑:
- 是否基于真实数据建模(如论文引用或公开数据库)。
- 是否有明确说明生成规则(如正态分布、人工定义的阈值)。
风险提示:
- 若生成逻辑不透明,可能引入偏差(如虚构的特征交互关系)。
- 需通过交叉验证和外部数据集测试模型泛化性。
3. 什么是数据的质量?
数据质量的核心维度:
| 维度 | 定义与示例 |
|---|---|
| 准确性 | 数据正确反映现实,如酒精度的测量误差是否在合理范围内。 |
| 完整性 | 无缺失值或无效值。若某样本的density为空,则数据不完整。 |
| 一致性 | 单位统一(如所有密度以g/cm³为单位),标签定义明确(如“高”品质的阈值一致)。 |
| 时效性 | 数据是否过时。例如,10年前的葡萄酒生产工艺可能与现在不同。 |
| 相关性 | 特征与目标变量有逻辑关联。如糖分与口感相关,但与颜色无关。 |
| 噪声控制 | 随机误差或异常值较少。例如,密度值中出现100 g/cm³显然为噪声。 |
合成数据的特殊考量:
- 生成逻辑合理性:是否模拟了真实世界的复杂关系(如酸度与酒精度的负相关性)?
- 分布真实性:特征分布是否符合领域知识?例如,糖分是否呈长尾分布(少量高糖样本)?
4. 筛选数据源的标准是什么?
筛选数据源的核心标准及示例:
| 标准 | 说明与示例 |
|---|---|
| 可信度 | 优先选择权威来源(如UCI、Kaggle高评分数据集)或经过同行评审的研究数据。 |
| 数据量 | 样本量需匹配模型复杂度(如XGBoost需数百样本,深度学习需数千以上)。 |
| 相关性 | 特征与研究问题直接相关。例如,葡萄酒品质分类不需要“包装颜色”等无关特征。 |
| 完整性 | 缺失值比例低于5%,且缺失机制为随机(如非系统性漏填)。 |
| 可解释性 | 提供清晰的字段定义和生成方法文档。例如,alcohol是否以体积百分比为单位? |
| 法律与伦理 | 数据需符合隐私法规(如匿名化处理),避免使用未经许可的商业数据。 |
| 平衡性 | 分类任务中各类别比例接近。例如,低/中/高品质样本比例为3:4:3。 |
| 技术验证 | 通过统计检验(如Kolmogorov-Smirnov检验)验证数据分布是否符合预期。 |


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









