









专题:大数据单机学习环境搭建和使用
大数据单机学习环境搭建(7)SQL的DQL查询优化
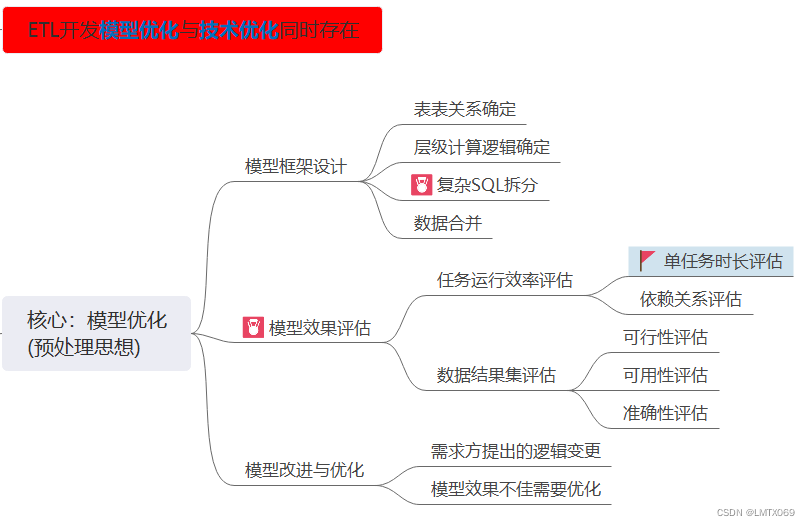
1.模型优化(内练固本)——预处理思想
注:所谓预处理就是提前准备好,形同饭店的备菜环节,应该先把要用到的菜洗、切等预处理好,等客人点菜了直接炒就好。预处理环节层层递进,适合复杂任务的拆分处理,简单任务“杀鸡焉用牛刀”。
模型设计优化的思路需要在工作中养成,很重要但很难像技术优化那样清晰可见,可能这就是经验的重要性吧,这里举几个例子简单说明下:
1.1复杂SQL拆分
内容:周月报优化
优化:小时分区任务计算转化为天任务计算,每月一次的统计平均到每天去做,最后仅收集每日一条的统计结果(小时数据量约4000万左右)
效果:6个8小时任务,均压缩到10分钟内完成
1.2数据合并、可行性和可用性评估
内容:某游戏排行榜数据接口任务
优化原因:模型及其复杂,需求方目的明确,但业务逻辑转化开发逻辑后数据量极大,无法实现前端展示(接口返回数据集为GB级)。多数据结果集合并更是无法进行。
优化方式:沟通修改需求,需求方往往并不能预估需求结果(事实上开发人员也做不到),只能是一边开发一边调整,主要是找到问题合理、准确的解释
2.技术优化(外练强身)
2.1表设计优化——好的开端是成功的一半
合适的表设计和合适的存储方式,对数据的查询至关重要;反之会直接造成查询完全无法进行的局面,优化更无从谈起
- 表的设计过程中要首先区分:
a.结合数据库类型(OLTP、OLAP),区分使用场景是主“读”操作还是主“写”操作;是否支持实时查询等
b.结合数据库特性(关系型数据库、非关系型数据库),区分对索引、事务和DQL的支持程度; - “读”为主的数据库,表的设计原则:
a.避免全表扫描,通过分区、分桶的方式实现;
b.设置主键、索引,提高查询效率;
c.选择文件存储格式(NoSQL),从文件读取时间和存储空间方面考虑。
2.2查询任务优化——锦上添花
DQL语法编写常识
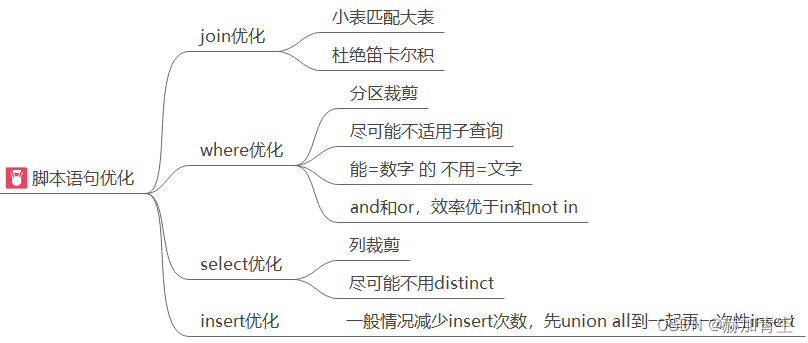
扩展内容: 《Hive优化实现》
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,如有雷同纯属巧合。















 336
336











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









