









专题:SQL使用技巧——实践是检验SQL函数的唯一标准
Hive中使用sql合并与拆分,本文所有演示均使用Hive完成
示例数据
-- create建表
CREATE TABLE concat_split_demo1(
id bigint,
name string,
age int,
city string,
address string,
notes string
);
-- insert插入数据
insert into concat_split_demo1 values(1,'张三',30,'广东省','中山市','备注#大数据#研究生#没对象#没车没房')
,(2,'李四',20,'广东省','佛山市','备注#能源开采#专科#已婚#有车有房')
,(3,'和尚',10,'广东省','东莞市','备注#小学生#小学生#有对象#豪宅豪车')
;
-- 同样方法,建表concat_split_demo2,并插入下方数据
insert into concat_split_demo2 values(1,'lisi',40,'内蒙古','锡林浩特','备注#伐木工#博士#已婚#豪宅')
,(2,'haili',90,'内蒙古','呼伦贝尔','')
,(3,'shanli',100,'内蒙古','呼和浩特市','备注#莲藕打孔#幼儿园#有对象#地下室')
,(4,'张三',30,'广东省','中山市','')
,(5,'李四',20,'广东省','佛山市','备注#能源开采#专科#已婚#有车有房')
,(6,'和尚',10,'广东省','东莞市','备注#小学生#小学生#有对象#豪宅豪车')
;
一.常规合并与拆分
1.1行变列不变 union all
union all最常规的数据合并方法
-- union all
select name,age,address,notes from concat_split_demo1
union all
select name,age,address,notes from concat_split_demo2
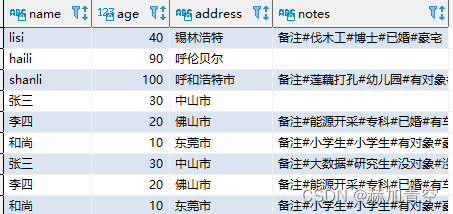
union和union all的区别在于union会对数据做去重,实际项目使用中通常使用union all,避免这种去重带来的时间消耗,具体视情况而定
-- union
select name,age,address,notes from concat_split_demo1
union
select name,age,address,notes from concat_split_demo2
;
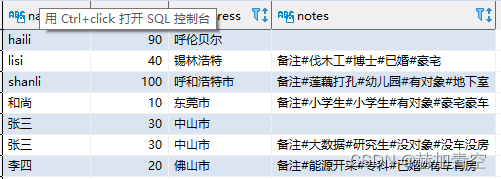
1.2行不变列变 join
join匹配数据 多个表的列合并到同一个表,行不变列变的前提是表与表直接on条件一一对应。
-- join
select d1.id id1,d2.id id2,d1.name name1,d1.name name2
,d1.address address1,d1.address address2
from concat_split_demo1 d1
join concat_split_demo2 d2
on d1.name=d2.name
;

join主要使用的有left join,join,full outer join,left semi join等,内容较多不是本文重点,这里不展开了
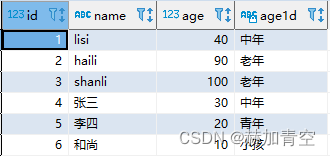
1.3一列变多列 case when
case when
-- case when
select id, name, age
, case when age >= 60 then '老年'
when age >= 30 then '中年'
when age >= 18 then '青年'
else '小孩' end age1d
from concat_split_demo2
;
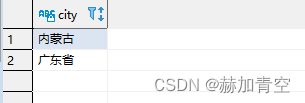
1.4行变 group by
group by 可添加聚合函数,例如count(),不添加聚合函数也可以起到去重的作用,Hive中去重效果要比distinct效果好(MR的执行原理),内容不具体展开。
-- group by
select city
from concat_split_demo2
group by city
;
二.(重点介绍)字段合并与拆分
2.1字段合并
2.1.1 多列并一列 ||和concat()、concat_ws()
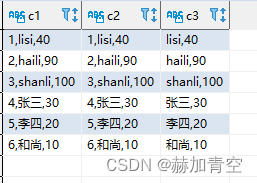
提示:NULL与任何内容拼接都返回NULL ||和concat() 效果是一样的,但是建议使用||,这不是Hive特有的,在某些数据库中||效率远高于concat(),例如华为ELK(亲测效果)
-- ||和concat()、concat_ws()
select id||','||name||','||age c1
,concat(id,',',name,',',age) c2
,concat_ws(',',name,cast(age as string)) c3
from concat_split_demo2
;
2.1.2 多行并一行 collect_list()、collect_set()
collect_list()、collect_set()的区别是列表list和集合set的区别,list没有去重,set做了去重,另外list和set都不排序,可以用sort_array()进行排序,对生成的list或set元素做concat_ws()合并。具体对比如下:
-- 为了更好区分collect_list()和collect_set(),先增加id=7的内容
insert into concat_split_demo2 values(7,'甄嬛',30,'广东省','东莞市','备注#演员#本科#有对象#豪宅豪车');
-- collect_list()、collect_set()、concat_ws()、sort_array()
select city
,collect_list(address)
,collect_set(address)
,concat_ws(',',collect_list(address))
,concat_ws(',',collect_set(address))
,concat_ws(',',sort_array(collect_set(address)))
from concat_split_demo2
group by city
;

2.2字段拆分
拆分要注意拆分符号的转义,例如 ‘;’ 需要写成 ‘\;’
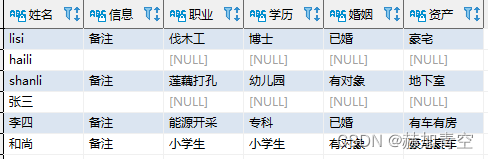
2.2.1 一列拆多列 split
-- split
select name `姓名`
,note[0] `信息`,note[1] `职业`,note[2] `学历`,note[3] `婚姻`, note[4] `资产`
from (
select name,age,address,split(notes,'#') note
from concat_split_demo2
) a
;
2.2.2 一列提取多列 get_json_object()
-- get_json_object
select GET_JSON_OBJECT(kv, '$.url') as infoid
GET_JSON_OBJECT(kv, '$.name') as infoid
from ...
;
-- split和get_json_object套用
select split(split(GET_JSON_OBJECT(kv, '$.url'),'id=')[1],'&')[0] as infoid from ...
这里没有案例,简单解释下,第一个sql是从json格式的kv字段中提取url的信息,第二个sql是对第一个sql的再加工,第一次split按照’id='来拆分并取了[1](即拆分后第2段的内容,不明白重看split),第二次split是对[1]的内容再拆分,这次按照&符号来拆分并取[0](即二次拆分后第1段的内容)。具体怎么拆要看实际json内容,但split和get_json_object套用后再复杂内容的也能完成拆分,剩下的就是细心比对了。
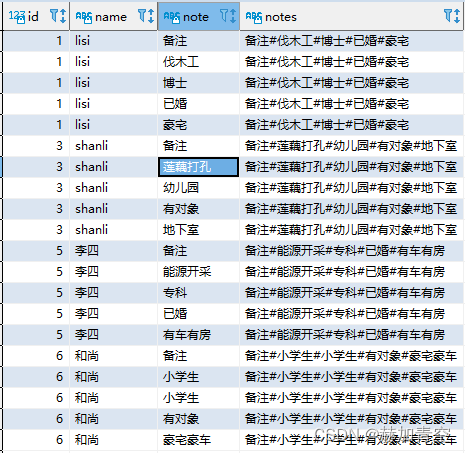
2.2.3 一行拆多行 lateral view
lateral view侧视图的用法如下,但显然下方情况1还是按照split拆分更符合实际项目需求
情况1:不同字段,不同内容强拆
-- 侧视图 lateral view
select id,name,note,notes
from
(select * from concat_split_demo2 where notes is not null and trim(notes)<>'') a
lateral view explode(split(notes,'#')) notes as note
;
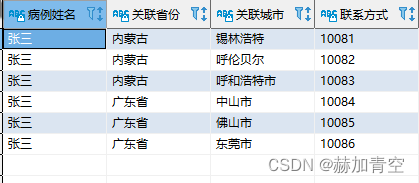
情况2:相同内容字段的拆分时,使用侧视图,示范拆2.1.2 的_c4字段
举个例子,例如有新冠病例’张三…等数人’旅游去过很多地方,每个省份提供了一个到访城市名单,现在要拆成一个一个城市,并匹配另一张表,各城市的联系方式。
with aa as(
select nm
,c1
,c
from
(
select '张三' nm,'内蒙古' c1,'锡林浩特,呼伦贝尔,呼和浩特市' c2
union all
select '张三' nm,'广东省' c1,'中山市,佛山市,东莞市' c2
) a
lateral view explode(split(c2,',')) c2 as c
)
select aa.nm `病例姓名`
,aa.c1 `关联省份`
,aa.c `关联城市`
,t.tel `联系方式`
from aa
left join
(select '锡林浩特' city, '10081' tel
union all
select '呼伦贝尔' city, '10082' tel
union all
select '呼和浩特市' city, '10083' tel
union all
select '中山市' city, '10084' tel
union all
select '佛山市' city, '10085' tel
union all
select '东莞市' city, '10086' tel
) t
on aa.c = t.city
;
情况3:被拆分字段是NULL时,lateral view outer将展示内容,lateral view将不展示内容
-- lateral view outer和lateral view
select id,name,note,notes
from
(select id,name,null notes from concat_split_demo2 where trim(notes)='' or notes is null) a
lateral view outer explode(split(notes,'#')) notes as note
;
侧视图内容不再详细展开。
三.其他情况
3.1字段合并wm_concat()的使用
下方代码使用环境是腾讯TDW,支持Hive和orcale语法。在其他系统环境下可能无法执行,仅做参考。
select id
,wm_concat(qq) qq_cat
from qq_table
group by id
;
wm_concat的详细使用解释
wm_concat(a) 对a字段无分隔符不排序concat
wm_concat(a,'-') 对a字段使用'-'作为分隔符不排序concat
wm_concat(a,'-','asc') 对a字段使用'-'作为分隔符,按照a的升序concat
wm_concat(a,'-','desc') 对a字段使用'-'作为分隔符,按照a的降序concat
wm_concat(a,'-','asc',b) 对a字段使用'-'作为分隔符,按照b的升序concat
wm_concat(a,'-','desc',b) 对a字段使用'-'作为分隔符,按照b的降序concat
wm_concat(a,' ','asc',b) 对a字段以空格为分隔符,按照b的升序concat
wm_concat(distinct a,' ','asc') 对a字段去重以空格为分隔符,按照a的升序concat
wm_concat(distinct a,' ','asc',b) 结果可能存在一定的不确定性
# wm_concat()不支持多字段排序(已验证),多字段时仅根据第一个字段进行排序
纸上得来终觉浅,绝知此事要躬行。SQL之路只有一个标准答案——实践成真。
相关内容推荐:
专题:大数据单机学习环境搭建
大数据单机学习环境搭建(3)Hive安装和启用
大数据单机学习环境搭建(4)设备重启后如何重启Hive和连接DBeaver
大数据单机学习环境搭建(5)Hive建表DDL详解
大数据单机学习环境搭建(6)Hive优化实现
大数据单机学习环境搭建(7)SQL的DQL查询优化
声明:本文所载信息不保证准确性和完整性。文中所述内容和意见仅供参考,不构成实际商业建议,可收藏可转发但请勿转载,如有雷同纯属巧合。















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









