






 本文讨论了在处理大规模脑图渲染时遇到的性能问题,通过介绍konva.js的使用和canvas优化技巧,如限制canvas大小、禁用缩放、形状缓存等,展示了如何解决渲染卡顿,实现更流畅的用户体验。
本文讨论了在处理大规模脑图渲染时遇到的性能问题,通过介绍konva.js的使用和canvas优化技巧,如限制canvas大小、禁用缩放、形状缓存等,展示了如何解决渲染卡顿,实现更流畅的用户体验。
背景:
背景是一个类似脑图的迭代需求。脑图本身是团队里以前就做好的功能。此前是基本满足需求。每次渲染的脑图卡片节点不到100个。
不过这次的需求有变,需要展示历史上的所有节点。节点数量可能达到几百个上千个。
这时候问题来了:
因为节点的卡片是一个比较复杂的样式。发现起始渲染会变得卡顿,需要很久才会渲染出第一帧画面。
一开始是直接渲染出一整个脑图,然后用overflow实现滚动,但是全部节点的时候,canvas高度达到数万像素。浏览器根本渲染不了这么大的canvas,直接白屏了。
后来改成canvas为用户窗口大小,但也是比较慢,拖拽的时候也不流畅,不跟手了,拖拽后明显延迟几百毫秒画面才动。
官网说的优化手段都做了后,结果还是不尽人意。如果继续优化只能改源码了,有点得不偿失。
最后只能换一个稍微底层一点的框架,这样能细致的掌控优化细节。 最终选择 konva.js 来实现的。
完成脑图渲染后,如果不做优化,还是满足不了性能要求的,甚至不如之前 。
这时候让我们看看konvajs官方给出的优化手段有哪些?以及为什么这些优化有效果呢?
优化目标:
当然我们最终的优化目标始终都是:
- 尽可能少地计算
- 尽可能少地绘制
konva 优化手段和原理:
- canvas 不要过大。
- 移动的最好要禁止缩放视窗。(因为 canvas 是像素渲染,不是矢量渲染的,如果缩放,为了保证形状清晰,必须要重新计算。比如放大操作,其实也相当于在一个像素密度更高的手机上渲染了)。
- 性能不佳的设备可手动设置 Konva.pixelRatio = 1,(这个原因和上一个一样)。
- 设置 listening(false)。减少不必要的事件监听。(canvas 本身是没有绘制元素的点击操作事件的,konva 自己在 js 层模拟实现了类似 dom 的冒泡事件,这个当然越少越好)
- 图层管理-如果可以的话不要让太多的元素集中在一个图层上,当然这也和你的场景有关。这里的图层 ,kanva 会对每个图层(layer)单独绘制一个 canvas,大量图形如果都在同一个图层上,这样每次重绘都会重新计算所有元素。另外在拖动某个元素时,可以把它拿到另一个图层,同理,这样拖拽的过程中,就会只重绘拖拽图层的内容,而全部元素的图层只在拖拽开始和结束的时候重绘 2 次。
- 形状 缓存 Shape Caching - 这里的 caching 操作 kanva 在内部会将绘制的图形转换为像素图。后续操作就会直接操作这个图。能明显提高渲染速度。(这里为什么变成像素图就能提高了,后面再详述)。但是使用这个 api 也要注意,1. 因为像素化了,所有后面对他的一些变形操作就不行了,比如将一个矩形的宽度变窄。2. 操作此 api 前不能让图形 hide 。这样会得到一个空图。可以Caching后再 hide。
- 保持图形较少-删除不可见的元素 透明度=0 的元素,视窗外的图形不展示。
- 关闭完美绘图-perfectDrawEnabled(false) - 这个主要针对透明元素的配置。在 canvas 中绘制一个带边框的矩形,其实和 dom的 border 是不同的。canvas 的边框 stroke() 是沿着线向 2 侧延伸。也就是说绘制一个2px 的边框。1px 在矩形的width内,1px 在 矩形的 width 外。这样也导致了当我们想绘制一个半透明的效果的矩形时,得到了如下的诡异效果:
const canvas = document.querySelector('#can')
const c2d = canvas.getContext('2d')
c2d.fillStyle = 'red'
c2d.strokeStyle = 'blue'
c2d.lineWidth = 10
c2d.globalAlpha = 0.5
c2d.strokeRect(100, 100, 200, 200)
c2d.fillRect(100, 100, 200, 200)

填充的红色半透明 和 边框向内延伸的一半蓝色半透明混合成了 深红色!
konva默认会打开perfectDrawEnabled,避免这种现象,原理是先在一个缓冲 canvas 中绘制好非透明的形状后,再在当前图层绘制缓冲 canvas 的像素。详见 kanva 源码中
Shape.ts 下 _useBufferCanvas 方法相关的代码
如果我们没有半透明的元素可以直接设置 perfectDrawEnabled : false
9. 如果我们不需要对描边单独做阴影,可以设置 shape.shadowForStrokeEnabled(false), 原理同上,konvas 为了避免诡异效果,做了缓冲处理。
10. 如果一个图形有细微的描边,可以对细微描边可以设置 shape.hitStrokeWidth(0) 取消描边的点击。这很好解释,节约了对描边的位置计算。在一个圆角矩形中,点击是否命中描边,所需的计算也是很多的。
11. 其他优化就不细说了,比如优化动画,及时释放内存。
12. 对于大量数据。我们也可以自己做一些队列,异步渲染,避免卡顿,每次渲染一小部分。中间最好留给用户 10 几 ms 的空间,用户操作能较好的减少卡顿感。
把上面的优化做完,我们就能看到明显比一开始流畅了不少。
但是有些地方我们还不是很明白。
比如:
- 对不相关的元素设置 listening(false),发现优化效果很有限。
- 对图形 cache,变成图片,发现虽然首次渲染会变慢一点,但是重绘的渲染速度大幅增加,可以做到完全跟手的状态了。
为何不同的优化手段效果不同?还有没有别的优化手段了?
mdn 上提示对canvas的优化:
在 mdn 中我们能看到一些官方推荐的优化手段:
- 离屏渲染, offscreenCanvas- 现代很多浏览器都支持了这个功能,这个可以在 web worker 中渲染 kanvas ,避免了主线程中影响用户操作,造成卡顿感。渲染本身的速度没有变。
- 避免浮点数的坐标点,用整数取而代之- 浮点数的坐标会让浏览器额外的处理抗锯齿计算。(什么是抗锯齿?其实就是针对人眼看到的形状边缘的像素进行优化,让人眼看起来更好看。比如一个 0.5px 的黑色线,画在一个白底上。显示器不可能真的显示出 0.5px 来,计算机就会计算出一个灰色的线,模仿 0.5px 的线。)
- 不要在用
drawImage时缩放图像 - 最好缓存不同尺寸的图片。 - 使用多层画布去画一个复杂的场景 - 在上面已经说过类似的了,也是避免每次重绘很多的图形。
- 用 CSS 设置大的背景图-也是为了减少 canvas 中的元素。
- 用 CSS 变换特性缩放画布 - 这个的原因后面我们详述。
- 关闭透明度 - 如果不需要透明可以 把
alpha选项设置为false - 更多的贴士
- 将画布的函数调用集合到一起(例如,画一条折线,而不要画多条分开的直线)
- 避免不必要的画布状态改变
- 渲染画布中的不同点,而非整个新状态
- 尽可能避免 shadowBlur特性
- 尽可能避免 text rendering
- 尝试不同的方法来清除画布 (
clearRect()vs.fillRect()vs. 调整 canvas 大小) - 有动画,请使用
window.requestAnimationFrame()而非window.setInterval() - 请谨慎使用大型物理库
上面的优化手段,有些我们做可以可以实现如: 避免浮点数的坐标点。但有些是需要在konva 这种框架层面去做的,比如 将画布的函数调用集合到一起, 比如绘制多个矩形组成的形状,我们可以直接绘制一个多边形来,理论上会比绘制多个矩形来的快。但是那样需要很多数学知识,做业务时不会给我们那么多时间研究。
看到这里我们有学会了不少优化手段,但是为何做这些操作能带来性能提高呢,这些不同的优化操作效果有什么不同呢?
进入canvas源码,寻找优化原理
接下来我们再稍稍深入一点看看 canvas 是如何绘制图形的。
以 chromium 内核为例。chromium源码很大,数十G,我们只是查阅,没必要都下载下来,可以直接在 web 上看源码(chromium/src - Chromium Code Search)
另外还有一份源码说明,可以先在这里搜索(docs - Chromium Code Search)
我们搜索 canvas 或者 canvas 的一些 api 作为关键字,虽然里面看不太懂代码,但从中可以摸索到一个关键字 Skia 在 how_cc_works.md 中描述
PaintCanvas is the abstract class to record paint commands.
It can be backed by either a SkiaPaintCanvas (to go from paint ops to SkCanvas) or a PaintRecordCanvas (to turn paint ops into a recorded PaintRecord).
查看Skia官网滑雪 — Skia,这是一个跨平台的图形引擎。
并且确实是 chromium 中 canvas的图形引擎。
在官方文档中,可以发现,Skia 的 api 和 canvas 的十分类似。都支持画一些形状、渲染文本等操作。
另外 skia 还支持多种后端,包括 Raster,或者 OpenGL, Vulkan 等 GPU 驱动,PDF 输出。
我们在浏览器的设置界面能找到一个开关。是否开启硬件加速,默认是开启的。这个的作用其实就是利用 gpu 的驱动来渲染。如果关闭了就会完全用 cpu 去计算像素。
skia的后端如果选择 Raster 意思就是在 skia 内部用 cpu 计算每个像素。
而如果选择 Vulkan 等 gpu 驱动,skia 就会生成对应的 gpu 着色器,并利用 gpu api 来渲染。
可以看出硬件加速的情况下,主要渲染流程如下:
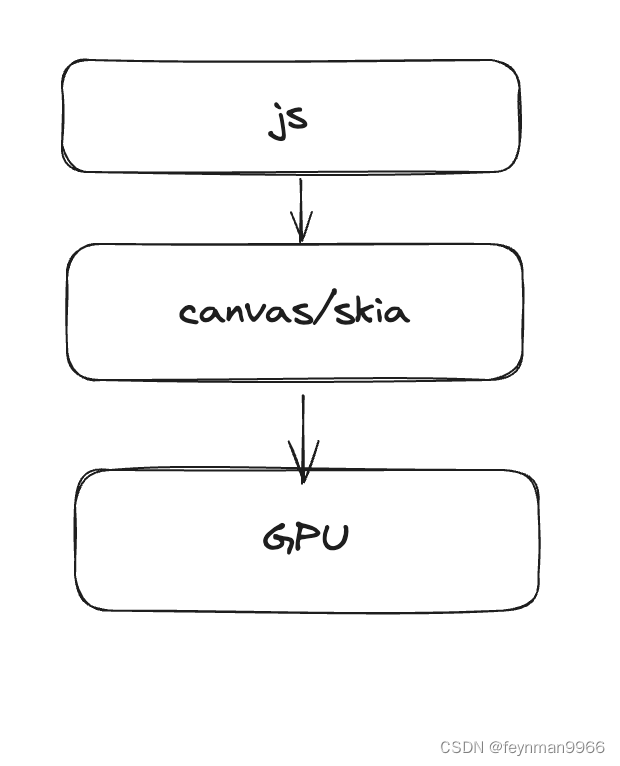
gpu 如何加速图型渲染的呢?
我们知道 gpu 和 cpu 不同,他有许许多多的小核心来并发处理像素。
另外 gpu 主要有 2 种着色器,顶点着色器和片元着色器,这里我们可以简单认为就是处理顶点位置偏移和像素颜色的小函数。
cpu 会将计算好的每个点的位置(或颜色纹理)放到一个连续的内存空间下。
gpu 对这段连续的内存进行并发吞吐。数百数千个核心同时工作。对每个点可以单独分配一个核心进行着色器计算。
这样就可以利用gpu 着色器来合成像素颜色等操作。大大节省了 cpu 的运算。
我们也发现了,要想提高效率,能让 gpu 做的就决不让 cpu 去做。我们把 gpu 能做的操作都给他就行啦~
其实现在的电脑无论是核显还是独显,性能都很强大了。普通的 intel 核显都能流畅跑一些网络游戏。
gpu具体能做什么?
相比 cpu,他能做的事其实非常少!
skia 能画矩形,这部分想让gpu 来做,直接画一个矩形,行吗?抱歉不行。
opengl的绘制流程:
以 openGl 为例,看一下绘制一个图形的主要流程如下:
// 创建并编译着色器
GLuint vertexShader = glCreateShader(GL_VERTEX_SHADER);
glShaderSource(vertexShader, 1, &vertexShaderSource, NULL);
glCompileShader(vertexShader);
GLuint fragmentShader = glCreateShader(GL_FRAGMENT_SHADER);
glShaderSource(fragmentShader, 1, &fragmentShaderSource, NULL);
glCompileShader(fragmentShader);
// 创建着色器程序
GLuint shaderProgram = glCreateProgram();
glAttachShader(shaderProgram, vertexShader);
glAttachShader(shaderProgram, fragmentShader);
glLinkProgram(shaderProgram);
// 创建并填充缓冲区
GLuint VBO;
glGenBuffers(1, &VBO);
glBindBuffer(GL_ARRAY_BUFFER, VBO);
glBufferData(GL_ARRAY_BUFFER, sizeof(vertices), vertices, GL_STATIC_DRAW);
// 创建并使用顶点数组对象
GLuint VAO;
glGenVertexArrays(1, &VAO);
glBindVertexArray(VAO);
glVertexAttribPointer(0, 3, GL_FLOAT, GL_FALSE, 3 * sizeof(float), (void*)0);
glEnableVertexAttribArray(0);
// 绘制图形
glUseProgram(shaderProgram);
glBindVertexArray(VAO);
glDrawArrays(GL_TRIANGLES, 0, 3);
glDrawArrays 绘制图形
glDrawArrays函数可以绘制图形。但只能绘制:点,线,三角形。想绘制一个矩形只能用 2 个三角形拼出来。
同理,如果想绘制一个圆形,就必须手动绘制一个连续的线段围成一个圆形,或者n 个三角形绕一圈形成一个原型。具体需要多少个三角形,这个 skia 会根据当前绘制的大小和屏幕自动进行处理。像素越高,尺寸越大,为了保证看起来是圆形,三角形就越多。
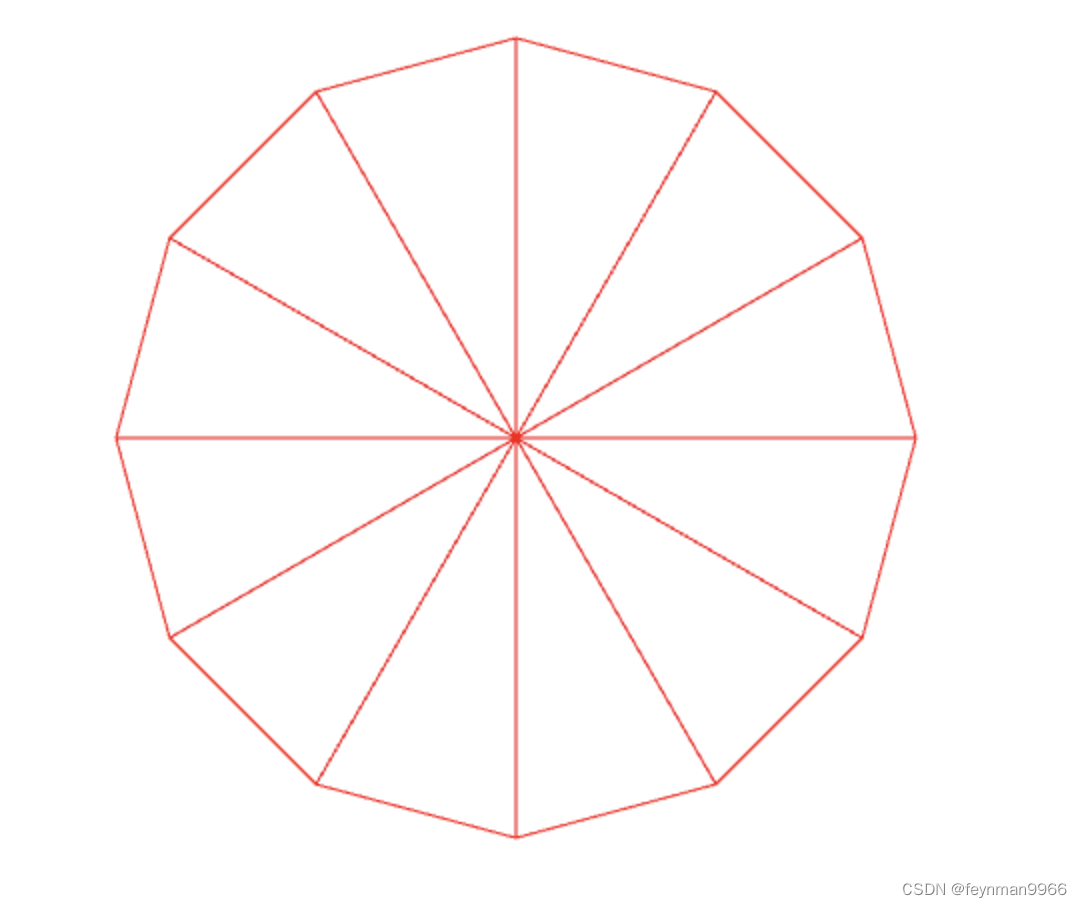
着色器能做那些工作呢?
顶点着色器
对于顶点着色器,我们可以对点的位置进行计算,gpu主要用途是 3d 渲染,而 3d 渲染里的近大远小,最终渲染到2d 的显示器上,其实就是一次对顶点的齐次坐标变换而已!
顶点坐标系天生就是处理向量变换的。
此时比如想让一个矩形缩小,可以利用如下的着色器:
#version 300 es
precision mediump float;
// 输入的顶点位置
in vec2 a_position;
// 输出的顶点位置
out vec2 v_position;
void main() {
// 将顶点位置缩小一半
v_position = a_position * 0.5;
// 将处理后的顶点位置传递给片元着色器
gl_Position = vec4(v_position, 0.0, 1.0);
}
片元着色器
对于片元着色器,我们可以用他进行像素点颜色计算,比如将像素点变成半透明:
#version 300 es
precision mediump float;
// 输入的颜色
uniform vec4 u_color;
// 输出的颜色
out vec4 outColor;
void main() {
// 将颜色的alpha值设置为0.5
outColor = vec4(u_color.rgb, 0.5);
}
或者进行像素模糊的滤镜:
precision mediump float;
uniform sampler2D u_image;
uniform vec2 u_textureSize;
varying vec2 v_texCoord;
void main() {
vec2 onePixel = vec2(1.0, 1.0) / u_textureSize;
vec4 color = (
texture2D(u_image, v_texCoord - onePixel) +
texture2D(u_image, v_texCoord) +
texture2D(u_image, v_texCoord + onePixel)
) / 3.0;
gl_FragColor = color;
}
处理纹理
另外opengl 还能加载图片作为纹理。
// 假设你已经加载了图片数据,并创建了一个纹理
GLuint texture;
glGenTextures(1, &texture);
glBindTexture(GL_TEXTURE_2D, texture);
glTexImage2D(GL_TEXTURE_2D, 0, GL_RGBA, width, height, 0, GL_RGBA, GL_UNSIGNED_BYTE, imageData);
// 创建和编译着色器
// ...
// 设置纹理采样器
glUniform1i(glGetUniformLocation(shaderProgram, "u_texture"), 0);
// 绘制矩形
glDrawArrays(GL_TRIANGLES, 0, 6);
处理图片的时候, gpu也是将图片数据放到缓冲区中然后并发处理每个图片的每个像素点。
其他功能:
opengl 还能进行抗锯齿处理,这种功能在很多 gpu 驱动中都自带了。
目前 gpu 的主要功能就是这些了,
其实上面说的并不完全绝对,具体还需要根据不同的 GPU ,驱动,系统平台等情况而定。比如近些年的很多 gpu和驱动支持了 MeshShader,这种着色器可以对字体渲染优化一点。
并不能完全依靠GPU:
另外,具体形状的变换等一些操作也不会完全依赖着色器,因为 skia 本身也需要用到图形的宽高 位置等信息,需要在skia内存中也有一份数据,因此很多变形应该也是 skia 本身去处理的。
GPU能渲染文字吗?
目前不能。
只能在外部计算好文字各种信息,然后再给 gpu。另外文字整形是一个比较重的操作,包括颜色,字重,斜体,对其,宽度等处理,都需要在 skia 用 cpu 去计算。这也就解释了,为什么canvas 的优化中建议我们少用 text render。
回望前面没懂的优化原理:
到这里,我们也终于明白了上面的没弄懂的优化手段了:
- 为什么少用 text render?
答:如上所说:文字是skia 用 cpu 计算的,比较重的操作。 - 为什么将卡片绘制变成图片后,重绘就能立竿见影的流畅不少。
答:这个卡片中有大量的圆角矩形,描边,阴影,文字。而圆角矩形,文字都是需要 cpu 大量计算。圆角矩形描边有很多的三角形拼成的。但是如果cache 成一个图片,那重绘时 gpu 就直接拿到图片纹理,进行并发的像素渲染了。速度快得多。即使图片里的像素再复杂也无所谓了。但是同样也有缺点。因为文字也变成图片了,就不是矢量图形了,仔细看的话,可能看起来和 skia 直接渲染的文字,在微小像素上有少许差异。另外就是内存占用会增多一些。 - 为什么建议css 缩放而不是canvas 内部缩放。
答:canvas内部需要重新计算图形的位置大小。但是在 css 中变形,也是有硬件加速的,也相当于直接利用 gpu 的着色器去缩放 canvas 这个“图片”,会减少一些 cpu 的计算。 - 为什么“将画布的函数调用集合到一起(例如,画一条折线,而不要画多条分开的直线)”?
答:gpu 对数据处理是整块整块并发吞吐的,一次性喂给他的数据越多,越整齐,他的效率也越高,而不是每次给他一点。另外重复调用 canvas api也会有一些损失。 - 为何“避免不必要的画布状态改变”
答:每次状态的声明比如fillStyle,从 GPU 角度,其实可以看成相当于声明或修改了一次着色器。虽然 gpu 并发很高,但是我们也尽量少的声明不必要的着色器。
其他优化手段:
- 对于图形中有很多带曲线的复杂图形,GPU 是当做很多三角形来处理的。所以在缩放到很小的时候,我们可以对这些曲线进行简化成多边形。比如将圆角矩形处理成 8 边形。亦或是将文字渲染成简单的形状。毕竟肉眼已经看不出来了。这其实和3d游戏优化一样,远处的物体模型会简化!
- 重绘的时候可以只重绘变化的部分,这个和前面多图层同理。
一些质疑:
对于某些优化手段在我们普遍开启硬件加速的时代。我认为效果可能没以前那么显著了
比如:
- “不要用浮点数,避免抗锯齿计算”
抗锯齿 gpu 内部可以自动计算。而且 gpu 里面的数据很多都是浮点数! - ”不要在用
drawImage时缩放图像“
这种缩放图片用 gpu 的着色器可以做到,理论上图片纹理缩放应该对性能影响不大。
这部分我没有做实验,有兴趣的同学可以自己试试。
笔者在skia和 gpu 方面了解不是很多,如有不对的地方劳烦指正。
笔者在skia和 gpu 方面了解不是很多,如有不对的地方劳烦指正。
笔者在skia和 gpu 方面了解不是很多,如有不对的地方劳烦指正。
其中部分代码是 AI 说的。
============
实验:
我们可以手动下载一下skia 看看硬件加速效果:
How to download Skia | Skia
Skia Viewer | Skia
打开 Skia Viewer 测试用例后,我们按空格,可以配置。
默认 backend 是Raster,也就是纯 cpu 计算像素。我们改成另一个 GPU 驱动(opengl 或Vulkan 等),然后选择Slide 为 GM_animated-image-blurs,这是用 gpu 比较多的一个用例。
在下面的 Shaders 页签中选择 Compile,就是计算后给GPU的着色器了,虽然看不太懂里面的代码,但我们也能猜到,这些是用来分别处理不同的模糊程度的。
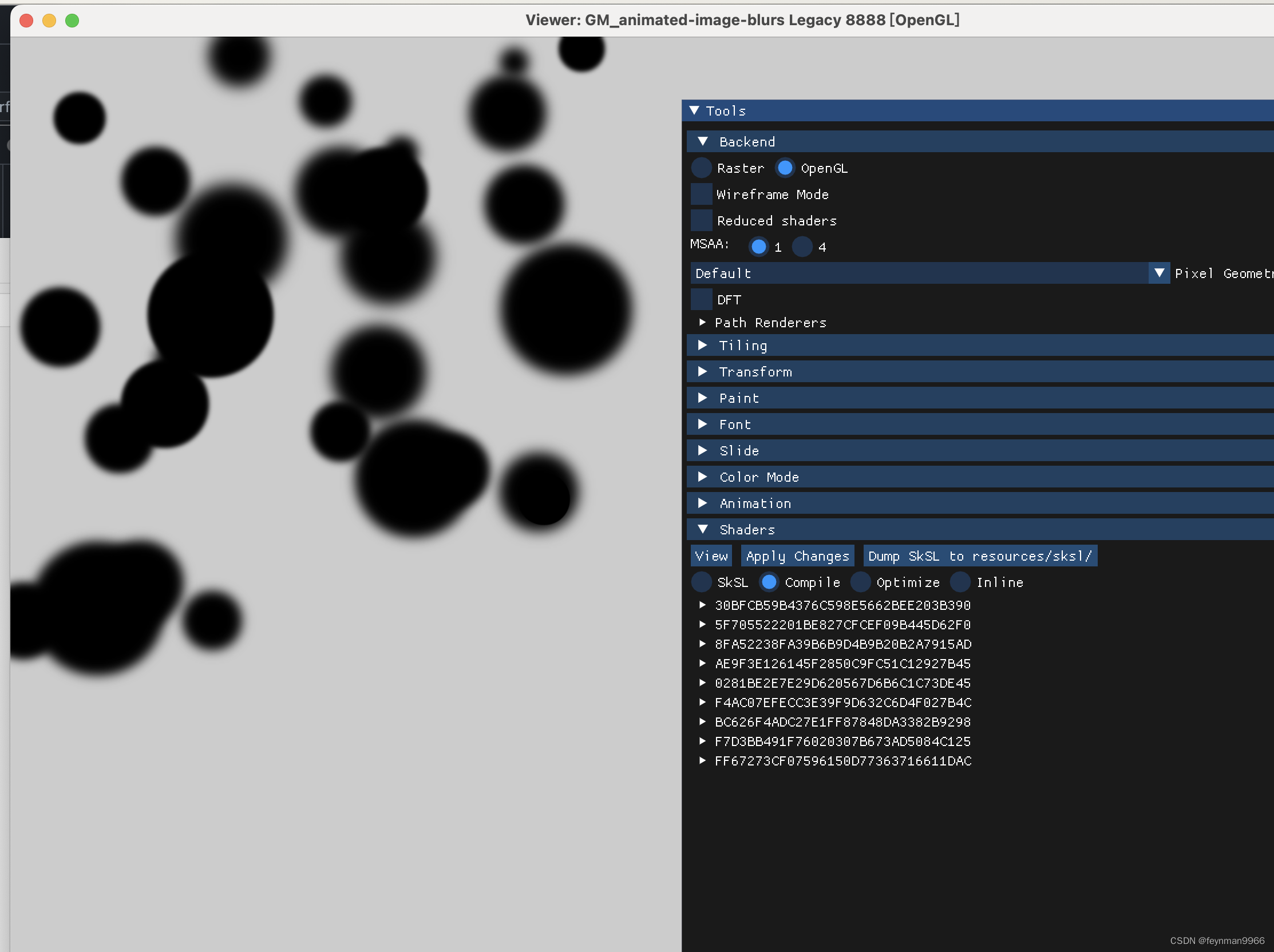
如果我们切换回 Rester 渲染,会发现直接卡主不动了。硬件加速效果还是很明显的。
参考:
Documentation | Skia
canvas 的优化 - Web API | MDN (mozilla.org)
HTML5 Canvas All Konva performance tips list | Konva - JavaScript 2d canvas library (konvajs.org)















 5089
5089

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









