






#创作灵感:r语言跑代码的时候需要删除AB两列同一行的数据相同值,但是网上给的代码都是一些duplicated()、distinct()、以及unique(),找了好久都没有找到我想要的,就自己写了点简单的代码跑成功了,我准备把遇到表格里删除相同值的情况进行汇总分享给大家!#
一共分为以下几种情况:(PS:背景是有AB两列)

-
目录
-
以列为角度的相同:
-
列列之间数值相同,去除
-
单列之间数值相同,去除
-
以行为角度的相同:
-
行行之间数值相同,去除
-
第一种情况:以列为角度的相同----列列之间数值相同,去除
setwd("D:\\get")#设置工作目录
rm(list = ls()) #清空空间
install.packages("openxlsx")#因为我是提取xlsx表格,所以需要安装这个包
library(openxlsx)
D <- read.xlsx("EXPLORE.xlsx",2)#这里的2是指我这个文件里的sheet2嘿嘿~
D <- D[D$A != D$B,]#这里$是指从D中提取某一列
#这样就欧卡啦~结果展示:

第二种情况:以列为角度的相同----单列之间数值相同,去除
A方法:用unique()函数
解释一下unique()函数,如果你指定某一列进行重复值删除,那么结果输出也只是针对此列。
和duplicated()函数和distinct()函数不同,下面会有展示和解释哦~
unique(D$A)结果展示:

B方法:用 duplicated()函数
解释一下duplicated()函数,如果你指定某一列进行重复列删除,那么结果输出的这一整行的删除。
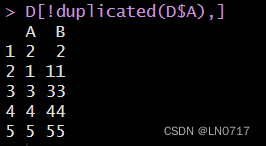
D[!duplicated(D$A),]#此处!是指删除重复值的意思结果展示:
C方法: 用distinct()函数
解释一下distinct()函数,如果你指定某一列进行重复列删除,那么结果输出的这一整行的删除。
library(dplyr)#distinct函数是属于dplyr包哦~
distinct(D,A,.keep_all= TRUE)#它的语法格式就是distinct(此文件,选中的哪一列(可以同时多选,只要多加一个,即可),.keep_all= TRUE)结果展示:

第三种情况:以行为角度的相同----行行之间数值相同,去除
A方法:用unique()函数
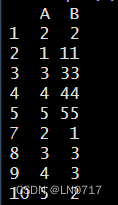
unique(D)结果展示:(原本第一行和第七行都是2,2,现在第七行去掉啦~)
B方法:用 duplicated()函数
结果和运行同A方法哦,这里就不展示啦~
C方法: 用distinct()函数
library(dplyr)
distinct(D,A,B,.keep_all= TRUE)#这里需要两列都选上哈~结果展示:

结束!虽然内容很少,但搞起来确实累不乎的,第一次弄这个,开心开心开心,希望能帮助大家‘啦~
















 579
579











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









