








我们在看 HashMap 的源码的时候经常能看到 tab[i = (n - 1) & hash]) 这么一串代码。他是专门用来计算当前 key 存储的位置,并获取当前存储位置的元素,进行后续的判断。
让我们用图的形式更直观的看一下它是如何怎么计算的吧。
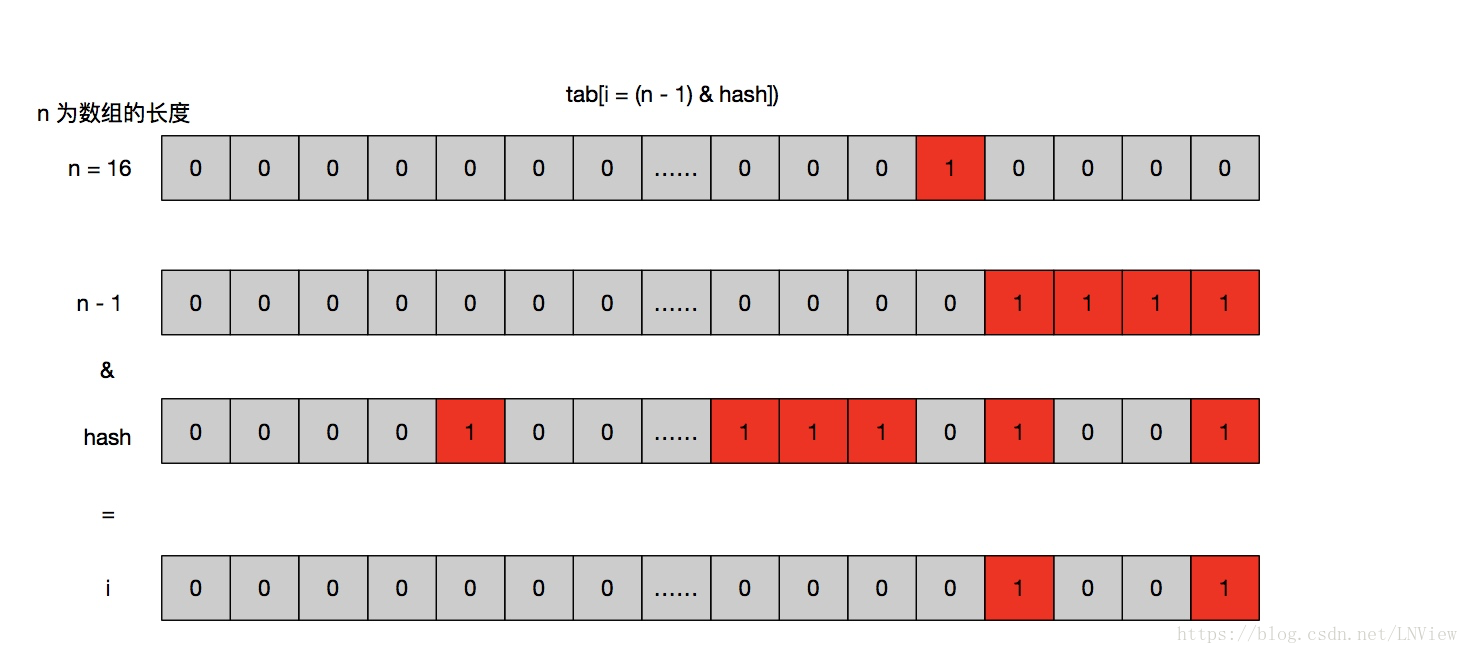
i = 9 即 tab[9]
这就是 HashMap 的精华所在,不论是 get() 还是 put() 都是通过上述的方法计算当前位置是否存在值或获取当前位置的值。这也是 HashMap 为什么数组的长度都为 2^n 的原因,这种操纵字节的计算方法具有足够的高效性。
所以这段代码
p = tab[i = (n - 1) & hash]可以理解为,将 hash 的 bit 位截取到 (n - 1) 的 bit 位长度。并找到该字节对映的 node 数组坐标中的值。
也间接的证明的 key 的存储位置和 key 的 hash 低位有着紧密的联系(因为通常情况下,我们的 Map 也不会太大)
相比较而言:但是因为和低位关系紧密,所以造成的碰撞的几率会大很多。对于不同的 key ,如果高位不同的多,低位相同的多,碰撞概率相应的也增加了。
而 HashMap 为了解决这方面问题,用了两个位运算方法将计算出来的 hashCode 通过高位的不同也影响到低位变化,使低位的最终结果是通过高位和低位计算得到的。
static final int hash(Object key) {
int h;
return (key == null) ? 0 :(h = key.hashCode()) ^ (h >>> 16);
}
^的意思就是位运算中,同一位置两个值相同的为 0 ,不同为的 1
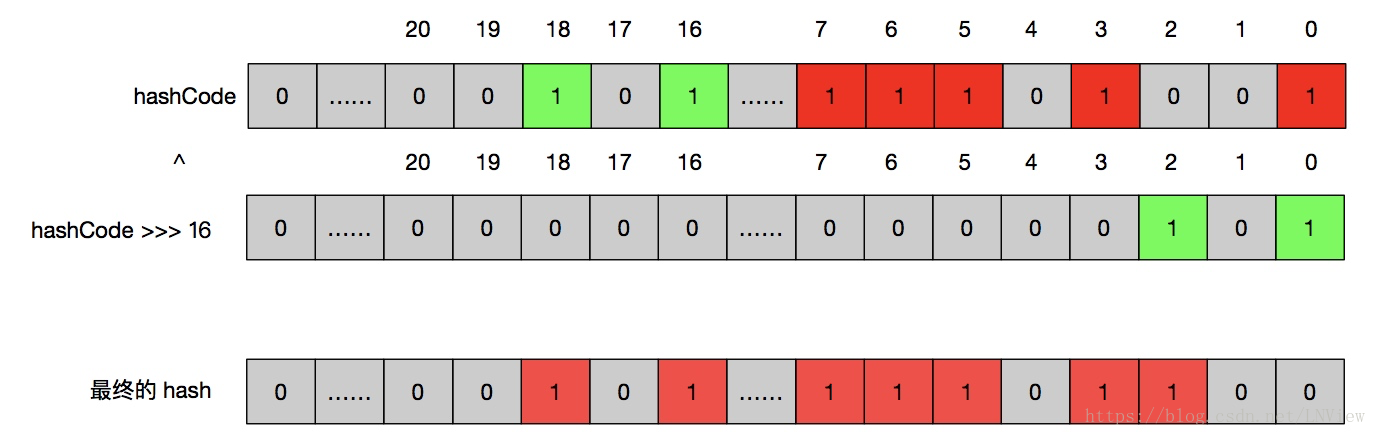
这就可以真正的动一位则动全身。不论高位还是低位,只要有一位不同,计算存储位置相同的概率就会大幅度降低(但是还是有的)。
Map (一) HashMap 构造函数的秘密
Map (二) HashMap put()方法详细解刨
Map (三) HashMap 如何利用 hash 计算存储位置
Map (四) HashMap 已故事的角度理解 resize()
Map (五) HashMap get()

















 562
562

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









