







摘要
在本篇文章中,少奶奶将详细的讲解如何把自定义训练的网络模型转换成TensorFlow Lite能识别的模型,并嵌入到手机设备中,让大家能够摆脱只能使用Google官网提供的模型的苦恼。此次教程使用的是MNIST数据集,在下一篇文章中,少奶奶将会使用YOLOV3模型来训练更为复杂的模型结构。当然,若有小伙伴不理解YOLOV3模型,少奶奶也会在近期使用浅显易懂的方式讲解一下YOLOV3.但总的来说,无论你是使用官网提供的模型还是自定义训练的模型,其整体思路是不变的。还请大家细心浏览和理解。
感谢前辈的分享
备注:大家在实践过程中有什么问题,可以在评论区留言,少奶奶会定期回复。
思路
1,使用Python实现一个简单的识别MNIST数据集的神经网络,得到网络模型结构和网络模型参数。
2,通过tensorboard查看网络模型图结构。
3,手动剪裁drop层。
4,模型转换。
5,边缘设备接入。
开发环境
window 10,pycharm、TensorFlow 1.13.0、Python 3.6、anaconda、android studio3.6
自定义网络模型(MNIST数据集)
下述代码会自动下载MNIST数据集(二进制),大家只需要配好环境,然后运行即可。少奶奶强烈建议大家阅读一下这套代码。关键的地方,少奶奶都写了注解。
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.python.framework import graph_util
from tensorflow.python.platform import gfile
# 定义初始化权重的函数
def weight_variavles(shape):
w = tf.Variable(tf.truncated_normal(shape, stddev=0.1))
return w
# 定义一个初始化偏置的函数
def bias_variavles(shape):
b = tf.Variable(tf.constant(0.1, shape=shape))
return b
def model():
# 1.建立数据的占位符 x [None, 784] y_true [None, 10]
with tf.variable_scope("date"):
x = tf.placeholder(tf.float32, [None, 28,28,1],"input_node")
y_true = tf.placeholder(tf.float32, [None, 10])
# 2.卷积层1 卷积:5*5*1,32个filter,strides= 1-激活-池化
with tf.variable_scope("conv1"):
# 随机初始化权重
w_conv1 = weight_variavles([5, 5, 1, 32])
b_conv1 = bias_variavles([32])
# 对x进行形状的改变[None, 784] ----- [None,28,28,1]
# x_reshape = tf.reshape(x, [-1, 28, 28, 1]) # 不能填None,不知道就填-1
# [None,28, 28, 1] -------- [None, 28, 28, 32]
x_relu1 = tf.nn.relu(tf.nn.conv2d(x, w_conv1, strides=[1, 1, 1, 1], padding="SAME") + b_conv1)
# 池化 2*2,步长为2,【None, 28,28, 32]--------[None,14, 14, 32]
x_pool1 = tf.nn.max_pool(x_relu1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 3.卷积层2 卷积:5*5*32,64个filter,strides= 1-激活-池化
with tf.variable_scope("conv2"):
# 随机初始化权重和偏置
w_conv2 = weight_variavles([5, 5, 32, 64])
b_conv2 = bias_variavles([64])
# 卷积、激活、池化
# [None,14, 14, 32]----------【NOne, 14, 14, 64]
x_relu2 = tf.nn.relu(tf.nn.conv2d(x_pool1, w_conv2, strides=[1, 1, 1, 1], padding="SAME") + b_conv2)
# 池化 2*2,步长为2 【None, 14,14,64]--------[None,7, 7, 64]
x_pool2 = tf.nn.max_pool(x_relu2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding="SAME")
# 4.全连接层 [None,7, 7, 64] --------- [None, 7*7*64] * [7*7*64, 10]+[10] = [none, 10]
with tf.variable_scope("arg"):
w_fc1 = weight_variavles([1024, 10])
b_fc1 = bias_variavles([10])
keep_prob = tf.placeholder("float", name='keep_prod')
with tf.variable_scope("fc"):
# 随机初始化权重和偏置:
w_fc = weight_variavles([7 * 7 * 64, 1024])
b_fc = bias_variavles([1024])
# 修改形状 [none, 7, 7, 64] ----------[None, 7*7*64]
x_fc_reshape = tf.reshape(x_pool2, [-1, 7 * 7 * 64])
h_fc1 = tf.matmul(x_fc_reshape, w_fc) + b_fc
h_fc1 = tf.nn.relu(h_fc1)
with tf.variable_scope("drop"):
# 在输出之前加入dropout以减少过拟合
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)
with tf.variable_scope("output"):
# 进行矩阵运算得出每个样本的10个结果[NONE, 10],输出
y_predict = tf.nn.softmax(tf.matmul(h_fc1_drop, w_fc1) + b_fc1,name="softmax_tensor")
return x, y_true, y_predict, keep_prob
# return x, y_true, y_predict
def conv_fc():
# 获取数据,MNIST_data是楼主用来存放官方的数据集,如果你要这样表示的话,那MNIST_data这个文件夹应该和这个python文件在同一目录
mnist = input_data.read_data_sets('MNIST_data', one_hot=True)
# 定义模型,得出输出
x, y_true, y_predict, keep_prob = model()
# x, y_true, y_predict = model()
# 进行交叉熵损失计算
# 3.计算交叉熵损失
with tf.variable_scope("soft_cross"):
# 求平均交叉熵损失,tf.reduce_mean对列表求平均值
loss = -tf.reduce_sum(y_true * tf.log(y_predict))
# 4.梯度下降求出最小损失,注意在深度学习中,或者网络层次比较复杂的情况下,学习率通常不能太高
with tf.variable_scope("optimizer"):
train_op = tf.train.AdamOptimizer(1e-4).minimize(loss)
# 5.计算准确率
with tf.variable_scope("acc"):
equal_list = tf.equal(tf.argmax(y_true, 1), tf.argmax(y_predict, 1))
# equal_list None个样本 类型为列表1为预测正确,0为预测错误[1, 0, 1, 0......]
accuray = tf.reduce_mean(tf.cast(equal_list, tf.float32))
init_op = tf.global_variables_initializer()
saver = tf.train.Saver()
# 开启会话运行
with tf.Session() as sess:
sess.run(init_op)
for i in range(3000):
mnist_x, mnist_y = mnist.train.next_batch(50)
mnist_x = mnist_x.reshape(-1,28,28,1)
if i % 100 == 0:
# 评估模型准确度,此阶段不使用Dropout
train_accuracy = accuray.eval(feed_dict={x: mnist_x, y_true: mnist_y, keep_prob: 1.0})
# train_accuracy = accuray.eval(feed_dict={x: mnist_x, y_true: mnist_y})
print("step %d, training accuracy %g" % (i, train_accuracy))
# 训练模型,此阶段使用50%的Dropout
train_op.run(feed_dict={x: mnist_x, y_true: mnist_y, keep_prob: 0.5})
# train_op.run(feed_dict={x: mnist_x, y_true: mnist_y})
# 将模型保存在你自己想保存的位置
# write_meta_graph=False 设置是否在生成ckpt时 生成图结构
# saver.save(sess, "./fcc_model.ckpt",write_meta_graph=False)
# tf.train.write_graph(sess.graph_def,"./","nsfw-graph.pb",as_text=False)
output_graph_def = graph_util.convert_variables_to_constants(
sess, sess.graph.as_graph_def(), ['output/softmax_tensor'])
with gfile.FastGFile('./frozen_model_str.pb', 'wb') as f:
f.write(output_graph_def.SerializeToString())
return None
if __name__ == "__main__":
conv_fc()
# 备注:输出名称是fc/softmax_tensor 而不是softmax_tensor 是因为原文中加入了with tf.variable_scope("fc"):
特别留意:由于,我们使用的数据集是二进制结构。所以,少奶奶在喂数据时,先reshape成[-1,28,28,1]。其维度是一维,并不是三维。

下图是模型入口节点,名称为"input_node"。

下图是模型出口节点,名称为"output/softmax_tensor"。
 备注:我们必须为入口节点和出口节点设置节点名称,因为在模型转换时,需要用到这些名称。
备注:我们必须为入口节点和出口节点设置节点名称,因为在模型转换时,需要用到这些名称。
下图中的代码,可以直接把网络模型结构图和网络模型权重参数冻结(绑定)在一起。若不用该接口,我们就需要存放图结构的pb文件和存放权重的ckpt文件进行冻结成新的pb文件。
tensorboard查看生成的网络图结构
运行下面的代码,然后在pycharm的终端中,激活anaconda虚拟环境,输入tensorboard --lodg/即可在浏览器中查看生产的图结构。
import tensorflow as tf
model = 'frozen_model_str.pb' #pb文件名称
# model = 'frozen_model_str.pb' #pb文件名称
graph = tf.get_default_graph()
graph_def = graph.as_graph_def()
graph_def.ParseFromString(tf.gfile.FastGFile(model, 'rb').read())
tf.import_graph_def(graph_def, name='graph')
summaryWriter = tf.summary.FileWriter('log/', graph) #log存放地址
# 网站中查看图结构 tensorboard --logdir log/
如下图所示,我们可以看出自定义网络模型的图结构,其中,少奶奶使用了dropout,在转换成tflite时,需要删除掉该节点。

在这篇文章中,使用了optimize_for_inference和freeze_graph之类的工具对dropout节点进行剪裁,但奇怪的是,少奶奶使用这些命令后并没有对dropout节点进行剪裁。所以采用手动剪裁的方式实现。具体如下:
from __future__ import print_function
from tensorflow.core.framework import graph_pb2
import tensorflow as tf
def display_nodes(nodes):
for i, node in enumerate(nodes):
print('%d %s %s' % (i, node.name, node.op))
[print(u'└─── %d ─ %s' % (i, n)) for i, n in enumerate(node.input)]
# read frozen graph and display nodes
graph = tf.GraphDef()
with tf.gfile.Open('frozen_model_str.pb', 'rb') as f:
data = f.read()
graph.ParseFromString(data)
display_nodes(graph.node)
运行上述代码,可以得到自定义网络的模型结构,找到第一个以drop开头的节点和最后一个以drop结尾的节点,这两个节点就是我们需要剪裁drop节点的起始位置和结束位置,

运行下述代码进行图结构的剪裁
from __future__ import print_function
from tensorflow.core.framework import graph_pb2
import tensorflow as tf
# Connect 'MatMul_1' with 'Relu_2'
graph.node[46].input[0] = 'fc/Relu'
# Remove dropout nodes
nodes = graph.node[:31] + graph.node[46:]
# del nodes[1] # 1 -> keep_prob
# Save graph
output_graph = graph_pb2.GraphDef()
output_graph.node.extend(nodes)
with tf.gfile.GFile('./frozen_model_without_dropout.pb', 'w') as f:
f.write(output_graph.SerializeToString())
再次运行tensorboard代码,可以看到drop节点已经被剪裁掉了

tflite模型转换
执行一下代码,实现pb转tflite模型
# -*- coding:utf-8 -*-
import tensorflow as tf
in_path = "frozen_model_without_dropout.pb"
# in_path = "frozen_mnist.pb"
out_path = "frozen_graph.tflite"
# out_path = "./model/quantize_frozen_graph.tflite"
# 模型输入节点
input_tensor_name = ["date/input_node"]
input_tensor_shape = {"date/input_node":[1, 28,28,1]}
# 模型输出节点
classes_tensor_name = ["output/softmax_tensor"]
converter = tf.lite.TFLiteConverter.from_frozen_graph(in_path,
input_tensor_name, classes_tensor_name,
input_shapes = input_tensor_shape)
converter.post_training_quantize = True
converter.allow_custom_ops=True
tflite_model = converter.convert()
with open(out_path, "wb") as f:
f.write(tflite_model)
备注:
1,转换模型时,需要网络模型中输出层和输入层的名称,这些名称可以到对应py文件中查找。
2,由于我们在训练时,是直接使用了MNIST官网中的文件,并没有转化成图片,所以,输入图片尺寸是1x28x28x1。
APP设备的移植
步骤一:下载Google官网的花卉识别模型android代码,并使用android studio导入。
代码下载
 这些代码是Google官网提供给开发者使用的花卉分类示例代码,大家可以使用这套代码重训练花卉识别模型,并嵌入app中,少奶奶写过一篇关于该套代码的使用教程[放上链接]。在本章中,我们只需要导入android文件夹中的代码即可。
这些代码是Google官网提供给开发者使用的花卉分类示例代码,大家可以使用这套代码重训练花卉识别模型,并嵌入app中,少奶奶写过一篇关于该套代码的使用教程[放上链接]。在本章中,我们只需要导入android文件夹中的代码即可。
步骤二:导入模型和标签,修改示例代码中的细节
标签制作

导入模型文件和标签
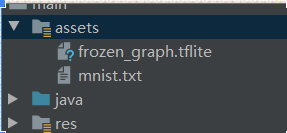
修改细节

修改ImageClassfier.java文件中的参数

备注:IMAGE_MEAN和IMAGE_STD分别是均值和方差,用于对图片数据进行标准化操作,由于少奶奶的自定义网络模型没有进行标准化或者归一化操作,所以设置为0和1.0f。且找到如下代码,注释前面两行,因为我们的输入是[1,28,28,1],既1通道,所以在获取数据时,只需要获取一个通道即可,若大家使用的是[1,28,28,3],那么就不能注释前面两行(imgData.putFloat()执行了三次,代表读取三通道的数据)。

步骤三:运行代码,真机调试,测试结果
使用usb数据线把手机和电脑进行连接,并打开手机的开发者模式,android studio会自动识别手机驱动,点击运行后,手机会自动下载安装app
 以下是测试结果
以下是测试结果

总结
自此,自定义网络实现MNIST数据集的训练和边缘设备迁移教程完结。大家在实践过程中会遇到很多问题,出现很多bug,但这是很正常的现象。记住要静下心来多看看博客,多查查资料。在下一篇中,少奶奶将为大家介绍一些关于YOLOV3模型的知识,并实现自定义YOLOV3训练模型使用TensorFlow Lite嵌入手机设备中。















 629
629











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









