







 本文从LR到决策树,详细介绍了决策树模型的总体流程、核心数学概念,包括信息量、熵,以及ID3、C4.5、CART三种决策树学习算法。讨论了决策树的过拟合问题和剪枝策略,最后引入了Bootstraping、Bagging和随机森林的概念,解释了随机森林的工作原理。
本文从LR到决策树,详细介绍了决策树模型的总体流程、核心数学概念,包括信息量、熵,以及ID3、C4.5、CART三种决策树学习算法。讨论了决策树的过拟合问题和剪枝策略,最后引入了Bootstraping、Bagging和随机森林的概念,解释了随机森林的工作原理。
从LR到决策树
思考一下一个分类问题:是否去相亲,logistic回归的解决办法可能是这样的
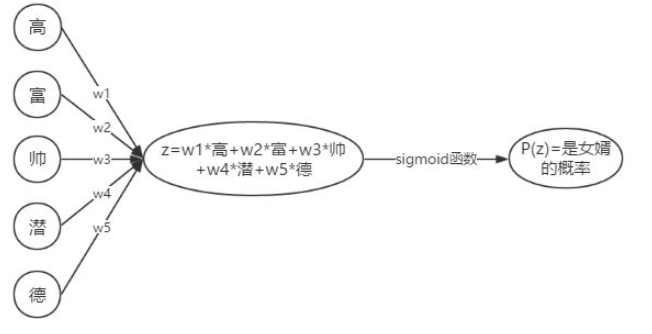
可是有时候,人更直观的方式是这样的
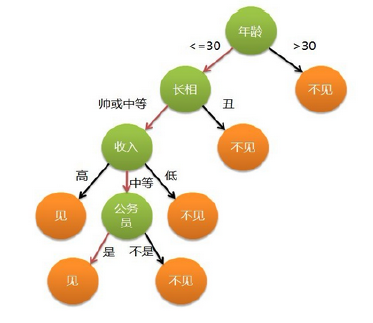
决策树模型
(决策树)分类决策树 模型是一种描述对实例进行分类的树形结构.决策树由结点(node)和有向边(directed edge)组成.结点有两种类型:内部结点(intemal node)和叶结点(leaf node).内部结点表示一个特征或属性,叶结点表示一个类
用决策树分类,从根结点开始,对实例的某一特征进行测试,根据测试结果,将实例分配到其子结点:这时,每一个子结点对应着该特征的一个取值.如此递归地对实例进行测试并分配,直至达到叶结点.最后将实例分到叶结点的类中.
下图是一个决策树的示意图,图中圆和方框分别表示内部结点和叶结点.
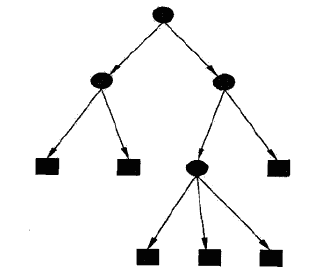
决策树基于“树”结构进行决策
- 每个“内部结点”对应于某个属性上的‘“测试”
- 每个分支对应于该测试的一种可能结果(即该属性的某个取值)
- 每个“叶结点”对应于一个“预测结果”
学习过程:通过对训练样本的分析来确定‘‘划分属性”(即内部结点所对应的属性)
预测过程:将测试示例从根结点开始,沿着划分属性所构成的“判定测试序列”下行,直到叶结点
总体流程
“分而治之”(divide- and-conquer)
自根至叶的递归过程
在每个中间结点寻找一个“划分”(split or test)属性
三种停止条件
- 当前结点包含的样本全属于同一类别,无需划分;
- 当前属性集为空,或是所有样本在所有属性上取值相同,无法划分;
- 当前结点包含的样本集合为空,不能划分。
伪代码

核心数学概念
定义信息量
- 某事件发生的概率小,则该事件的信息量大。
- 如果两个事件X和Y独立,即p(xy)=p(x)p(y) ,假定X和Y的信息量分别为h(X)和h(Y),则二者同时发生的信息量应该为h(XY)=h(X)+h(Y)。
定义随机变量X的概率分布为p(x),从而定义X信息量: h ( x ) = − l o g 2 p ( x ) h(x)=-log_2p(x) h(x)
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









