







最近在研究RocketMQ,小有心得,在此记录一下
首先给大家看下rocketmq的大体架构图
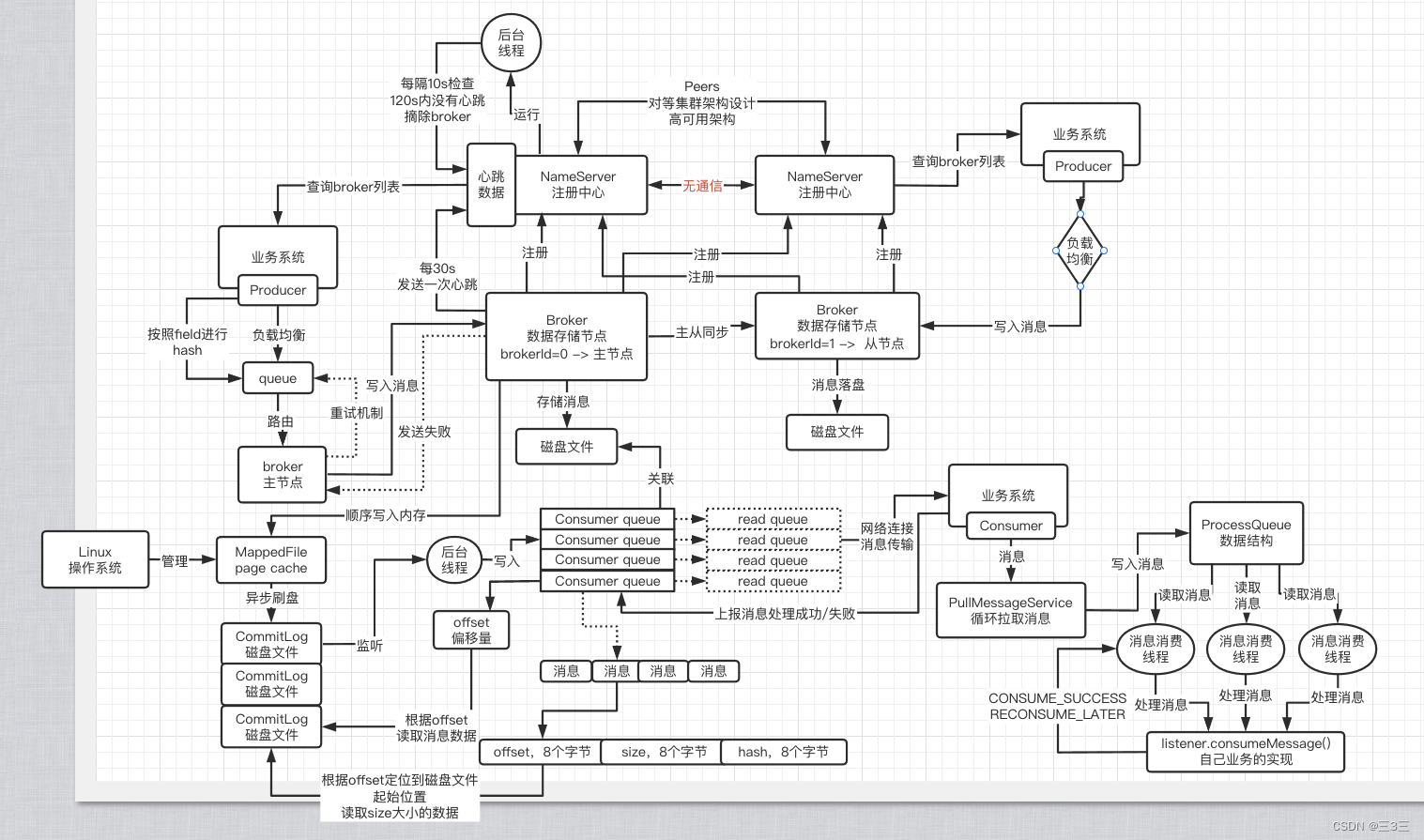
乍一看有些复杂,不要慌,我们来逐步分析他的各个环节
1.核心的主从架构模式
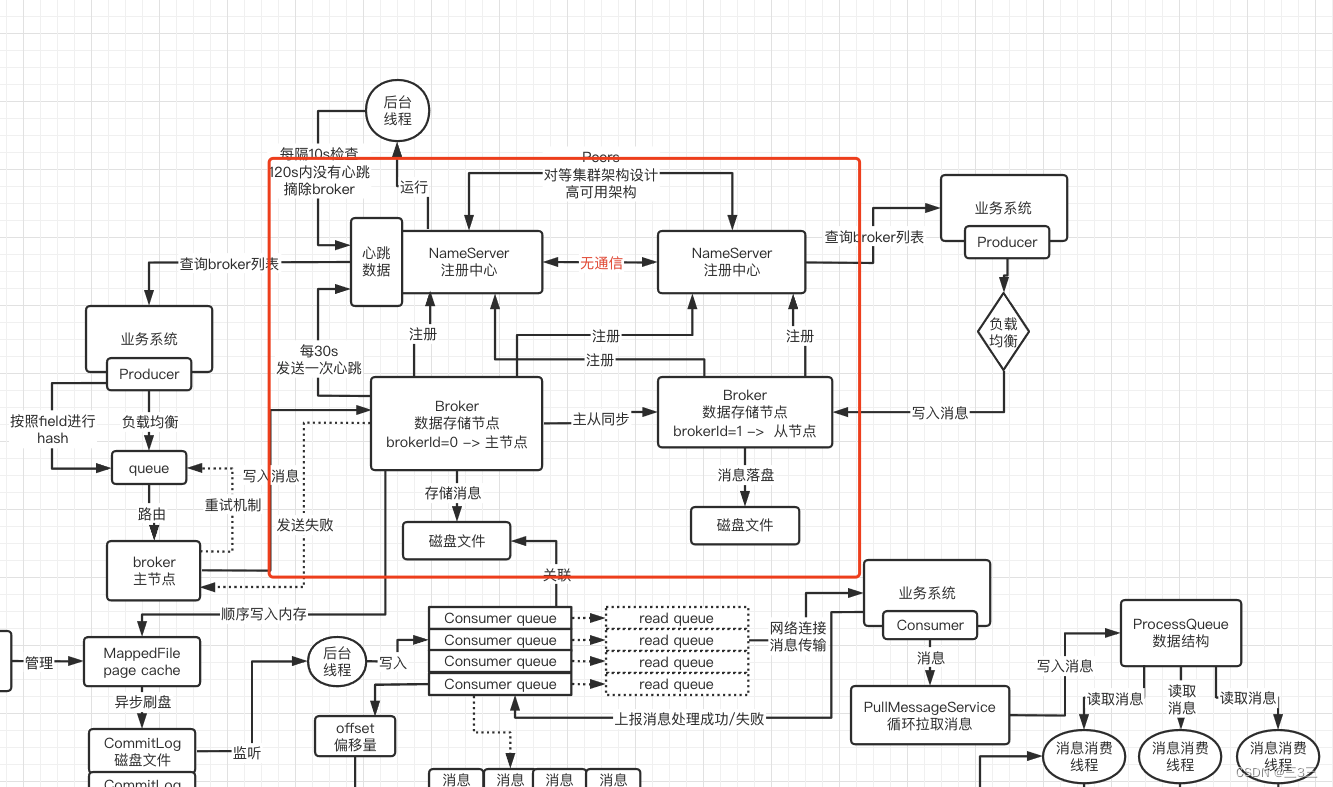
rocketmq主要分为4部分,NameServer、Broker、Consumer、Producer;其中最为关键的是NameServer和Broker。为了保证这两块的高可用,NameServer采用了Peers的集群模式,每个注册中心之间没有任何通信,每个Broker启动的时候,都会向所有的NameServer上报自己的信息,这种架构模式的好处就是实现简单,并且如果出现某个NameServer挂掉,其他的NameServer也能继续承担起注册中心的大梁,从而实现高可用。
上图Broker也是采用主从架构的模式,一般会有一个master节点,两个slave节点,主节点负责读写,slave节点只负责读。RocketMq4.5版本之前,主节点挂掉,需要人为干预,重新设置配置文件参数、重启机器,才能将slave节点设置成主节点,只是半高可用,4.5版本之后,新加入了Dledger模式,在该模式下,主节点挂掉之后,rocktemq会在slave中自动选举出一个master节点,不需要运维人员的参与,真正实现了高可用的模式。
一般消息写入都是直接写入到master节点,然后再由master节点将消息同步给其他的slave节点。读取消息会根据master节点的负载情况和消息同步进度,由master告知consumer下次应该到哪台broker上拉取剩余消息。
Broker会每隔30s向所有NameServer发送心跳,以此来告知NameServer哪些broker处于健康状态,而NameServer也会每隔10s就检查一遍所有的broker,查看是否存在120s内没有发送心跳的broker,如果存在,则将其从broker路由列表摘除。
2.RocketMq是如何保证大批量消息写入的呢?又是如何保证消息不丢失?
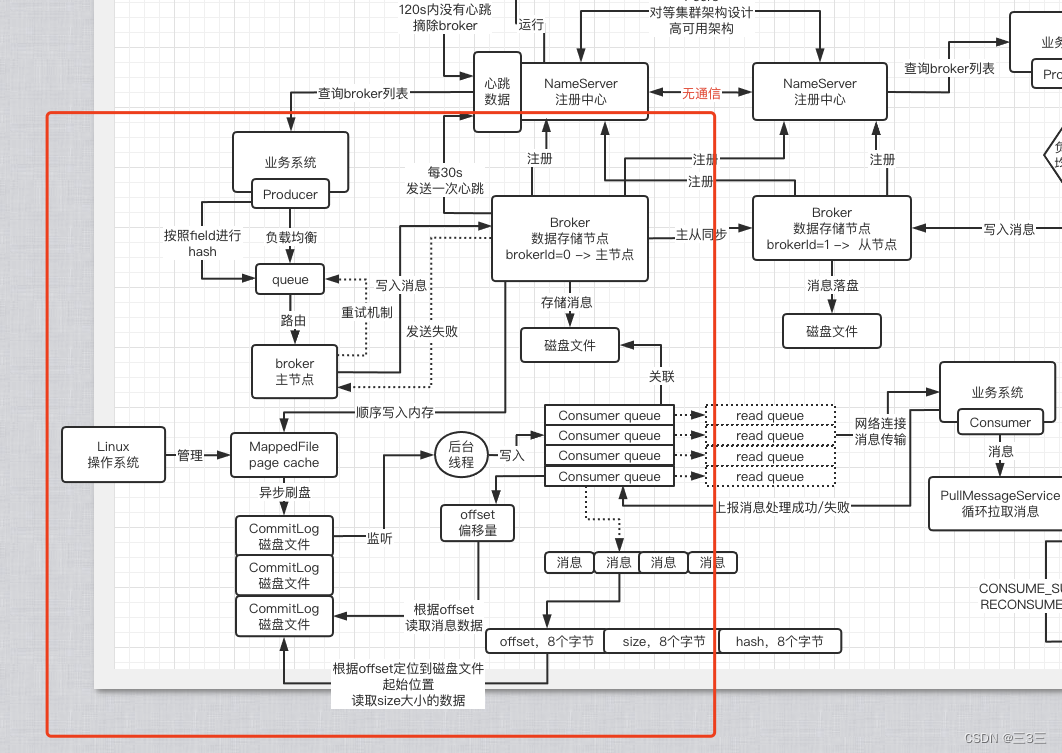
Producer启动时会与NameServer集群中的随机选择一个节点建立TCP长连接,获取所有的Broker数据,然后与所有Broker建立连接,每个长连接都会有心跳机制保活。并且定期从NameServer读取Topic路由信息,并将路由信息保存在本地内存中;当Producer向Broker写入消息时,会先从本地的messageQueue缓存列表里通过负载均衡算法选择一个,然后写入broker中。broker收到写入消息,会先顺序写入page cache缓存内,然后通过后台线程异步输入磁盘。
这里的page cache是os系统的缓存,如果broker挂了,这里的缓存不会丢失,除非linux也挂掉了,那么缓存内的数据才会丢失。因为是顺序写入缓存内,然后异步落盘,这种消息处理速度直接飞起,这也是rocketmq能支持高并发消息写入的原因。
那么如何保证消息不丢失呢?关键点就是page cache。如果你的业务需要保证消息不能丢失,那么你就配置broker跳过写入缓存的操作,直接写入磁盘文件中,等消息写入磁盘中再通知producer消息写入成功,这样消息就不会丢失了。不过这样做的弊端就是会直接影响mq的吞吐量,虽然顺序写入磁盘的速度也很快,但是和直接写入缓存还是有所差别的,并发量越高,这点性能就越突出。
3.Consumer是如何消费消息的?
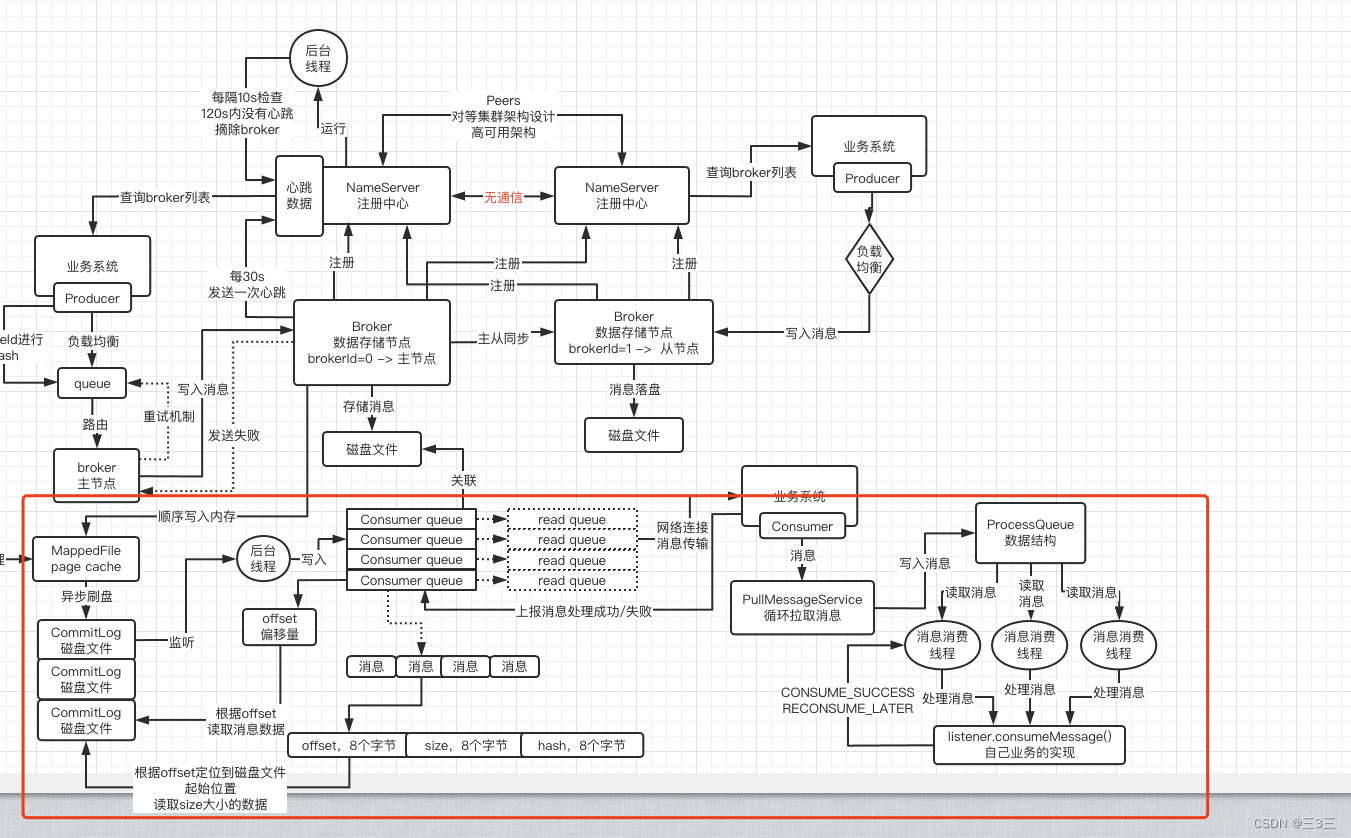
Consumer消费消息的方式有两种:
一种是push方式,Consumer注册到MessageListener后,会与Broker建立长连接,每当Broker接收到写入消息时,都会自动回调MessageListener的consumeMessage()方法,然后在Consumer端执行消费逻辑。对于Consumer来说,这个过程的消息是自动推送过来的。
另一种是pull方式,这种方式需要Consumer自己去Queue中拉取消息,Consumer首先会通过消费的Topic拿到MessageQueue集合,遍历MessageQueue集合,然后针对每个MessageQueue批量拉取消息。取完一次后,Consumer会记录MessageQueue下一次要取的起始offset,取完后再换下一个MessageQueue。该方式Consumer与Broker建立的是短连接。
我们上图用的就是第二种pull方式拉取消息的。
ConsumerQueue中会存储一个个的message,这个message中会记录3个主要参数,一个是offset,占8个字节,用来定位消息在磁盘中的位置;一个是size,占4个字节,用来记录消息的长度大小;一个是hash,占8个字节,用来记录消息在哪个磁盘文件中;当Consumer去Queue中拉取消息时,会通过hash找到是哪个磁盘文件,然后通过offset定位该条消息在磁盘文件中的位置,读取size长度的数据,这样就获取到message的数据了。之后可以将消息统一放到ProcessQueue里,然后定义多个线程去消费,处理完业务逻辑之后,再返回处理结果,有两种返回值,CONSUME_SUCCESS和RECONSUME_LATER,一种是成功,一种失败。如果是失败的话可以进行重试或者配置死信队列,重试到一定次数之后,放到死信队列中,人工干预。














 807
807











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









