









CoMat: Aligning Text-to-Image Diffusion Model with Image-to-Text Concept Matching
图文一致性的原因还是因为文本的 token 的激活注意值不高,导致文本的 token 无法激活图像的区域,从而导致图文不一致。作者将这种现象归因于扩散模型的训练方式对条件的利用不足,所以提出了 CoMat,是一种 端到端的扩散模型微调策略。

1. Introduction
缺陷
其实上图所展现出来的还是很基础的目标丢失问题
补充一下:
这个问题归因于视觉概念的的激活值不够大而被其他物体的注意力淹没,导致了视觉概念的丢失。之前也有一些相关工作,像:Atten-and-Excite,Structur Diffusion 等
这里也有一个关于问题的分析:
作者将 token 对应的交叉注意图进行了分析,这里采用的做法是:
- 将预训练UNet对带有文本标题的噪声图像进行降噪。然后记录每个文本token的激活值,并在空间维度上取平均值
可以看到带有 Comat 的,里面的所有激活值都有了提高
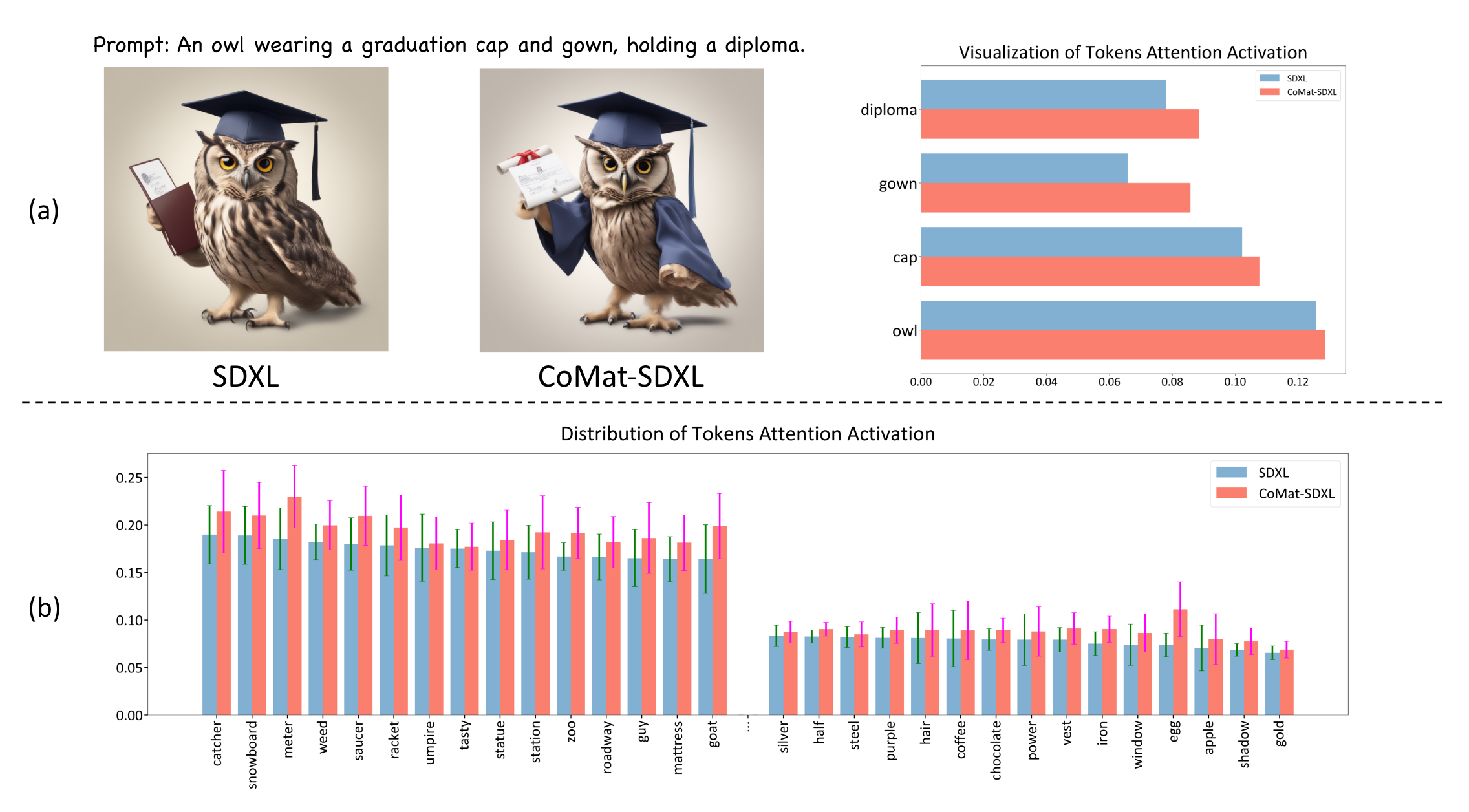
多说一句🤔
看到这里和之前的工作并没有什么不同,像 Atten-and-Excit 是将主题视觉概念的 token 去最大化响应值,这里貌似最后的结果也是一样的
2. Method
作者一共包括三个模块:
- Concept Matching
- Attribute Concentration
- Fidelity Preservation

2.1 Concept Matching
这里引入了图像字幕模型,即 Caption Model ,该模型可以根据给定的文本提示准确识别生成图像中不存在的概念。
在 Caption Model 的监督下,扩散模型被迫重新访问文本标记以搜索被忽略的条件信息,并为先前被忽略的文本概念分配重要性,以获得更好的文本-图像对齐。具体来说,做法是:
- 给定文本提示 P \mathcal{P} P, 以及相应的 词tokens { w 1 , w 2 , … , w L } \{w_1, w_2, \dots, w_{L}\} {w1,w2,…,wL};
- 对于一张在经过
T
\mathbf{T}
T 步去噪厚的图像,这个冻结的
Caption ModelC C C 会以对数似然的形式对图文一致性进行打分,训练目标就是最小化这个分数,标记为 L cap \mathcal{L}_{\text{cap}} Lcap:
L cap = − log ( p C ( P ∣ I ( P ; ϵ θ ) ) ) = − ∑ i = 1 L log ( p C ( w i ∣ I , w 1 : i − 1 ) ) . \begin{aligned}\mathcal{L}_{\text{cap}}&=-\log(p_{\mathcal{C}}(\mathcal{P}|\mathcal{I}(\mathcal{P};\epsilon_{\theta})))=-\sum_{i=1}^{L}\log(p_{\mathcal{C}}(w_{i}|\mathcal{I},w_{1:i-1})).\end{aligned} Lcap=−log(pC(P∣I(P;ϵθ)))=−i=1∑Llog(pC(wi∣I,w1:i−1)).
这个优化方式是通过 DPOK 这个方法做的;
作者说这个概念匹配模块可以缓解物体存在、复杂关系等多种错位问题。
2.2 Attribute Concentration

如上图所示,基于SDXL模型,单词“红”和“蓝”的注意力大多在背景中被激活,其对应对象的对齐很少。 我们的概念匹配模块可以在一定程度上缓解这一问题。然而,由于标题模型对对象属性不敏感,性能提升有限。这里,为了从更细粒度的视图将实体与其属性对齐,我们引入了属性集中,将实体的文本描述的注意力集中在图像中的区域上。
这里看下具体做法:
- 使用 spacy 解析库,提取文本提示中所有的名词和其修饰语,定义为实体 { e 1 , … , e N } \{e_1, \dots, e_N\} {e1,…,eN},而每个实体又可以定义为元组 即 e i = ( n i , a i ) e_i = (n_i,a_i) ei=(ni,ai)
- 然后手动过滤抽象的名词(例如:场景、氛围、语言),难以识别区域的名词(例如:阳光、噪音等),描述背景的(例如:早餐、浴室、派对等)
- 然后使用 Grounded-SAM 模型来风格出相应的区域 Mask, { M 1 , … , M N } \{M^1, \dots, M^N\} {M1,…,MN},这里只给名词拿来分割,原因是因为扩散模型会导致错误的属性绑定,那样就会导致不准确
- 然后就是集中同一区域内每个实体
e
i
e_i
ei的名词
n
i
n_i
ni 和
a
i
a_i
ai的注意力,用一个
M
a
s
k
i
Mask^i
Maski 来表示,总的来说包括两个优化目标:
- token-level attention loss
- pixel-level attention loss
token-level attention loss 就是强制激活 n i ∪ a i n_i \cup a_i ni∪ai的区域
L token = 1 N ∑ i = 1 N ∑ k ∈ n i ∪ a i ( 1 − ∑ u , v A u , v k ⊙ M i ∑ u , v A u , v k ) \begin{aligned}\mathcal{L}_{\text{token}}&=\frac{1}{N}\sum_{i=1}^N\sum_{k\in n_i\cup a_i}\left(1-\frac{\sum_{u,v}A_{u,v}^k\odot M^i}{\sum_{u,v}A_{u,v}^k}\right)\end{aligned} Ltoken=N1i=1∑Nk∈ni∪ai∑(1−∑u,vAu,vk∑u,vAu,vk⊙Mi)
pixel-leval attention loss 是通过二元交叉熵损失进一步迫使区域中的每个像素只关注对象令牌:
L
pixel
=
−
1
N
∣
A
∣
∑
i
=
1
N
∑
u
,
v
[
M
u
,
v
i
log
(
∑
k
∈
n
i
∪
a
i
A
u
,
v
k
)
+
(
1
−
M
u
,
v
i
)
log
(
1
−
∑
k
∈
n
i
∪
a
i
A
u
,
v
k
)
]
,
\begin{aligned}\mathcal{L}_\text{pixel}=-\frac{1}{N|A|}\sum_{i=1}^N\sum_{u,v}\left[M_{u,v}^i\log(\sum_{k\in n_i\cup a_i}A_{u,v}^k)+(1-M_{u,v}^i)\log(1-\sum_{k\in n_i\cup a_i}A_{u,v}^k)\right],\end{aligned}
Lpixel=−N∣A∣1i=1∑Nu,v∑[Mu,vilog(k∈ni∪ai∑Au,vk)+(1−Mu,vi)log(1−k∈ni∪ai∑Au,vk)],
其中|A|是注意力图上的像素数。而提示符中的某些对象可能由于不对齐而无法出现在生成的图像中。在这种情况下,像素级的注意力丧失仍然有效。当掩码完全为零时,它表示没有任何像素应该参与当前图像中缺失的对象标记。此外,考虑到计算成本,在在线模型的图像生成过程中,我们只在随机选择的r个时间步上计算上述两个损失。
2.3 Fidelity Preservation

由于目前的微调过程纯粹是由图像字幕模型和属性与实体之间关系的先验知识主导的,扩散模型可能会很快过拟合奖励,失去原有的能力,产生劣化的图像,如图6所示。为了解决这个 reward hacking 问题,作者引入了一种新的对抗损失,通过使用鉴别器来区分由预训练和微调扩散模型生成的图像。
这个好像还挺新奇的🤔(可以阅读 UFOGen)
对于判别器 D ϕ D_\phi Dϕ,用Stable Diffusion模型中预训练的UNet初始化,该模型与在线训练模型共享相似的知识,有望更好地保持其能力。在我们的实践中,这也使得对抗损失可以直接在潜在空间而不是图像空间中计算。此外,重要的是要注意,我们的微调模型不利用真实世界的图像,而是利用原始模型的输出。这种选择的动机是我们的目标是保持原始的生成分布,并确保更稳定的训练过程。
最后,在给定单个文本提示的情况下,我们分别使用原始扩散模型和在线训练模型来生成图像 latent z ^ 0 \hat{z}_0 z^0 和 z ^ 0 ′ \hat{z}_0' z^0′。对抗性损失计算如下:
L a d v = log ( D ϕ ( z ^ 0 ) ) + log ( 1 − D ϕ ( z ^ 0 ′ ) ) . \begin{aligned}\mathcal{L}_{adv}=\log\left(D_\phi\left(\hat{z}_0\right)\right)+\log\left(1-D_\phi\left(\hat{z}_0'\right)\right).\end{aligned} Ladv=log(Dϕ(z^0))+log(1−Dϕ(z^0′)).
2.4 联合训练

实验
Caption Model 是用 BLIP 在 COCO 数据集上 finetune 的
训练集包括 T2I-ComBench, HRS-Bench 以及 在 ABC-6K上随机采用的 5000 个 prompt,一共 2W 个图像
训练是在 Unet 里面插入 Lora 模块(包括原始 diffusion 和 判别器),其余全部冻住。 在 8 块 A100 80G 上训练 2000iters,50 步去噪,其中只有 5 步有梯度反馈。
实验效果还是不错的,重点还是看看这篇工作解决方式的方法。解决的问题还是一样的激活值不够,但是作者借用了很多模块包括 BLIP 、 SAM 等,但是 Atten-and-Excite 只用了一个最大化 Loss,估计还是效果和方法的一个 trade-off 。这篇工作感觉还是做的很复杂。















 702
702











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









