










SDXS: Real-Time One-Step Latent Diffusion Models with Image Conditions
sign: 2024-4-28 💡
在看这个文章之前,首先要对 consistency model ,score-based model要有一定了解,以及相应的知识蒸馏,怎样去做单步生成的等等
扩散模型由于其迭代采样过程而导致显著的延迟。为了减轻这些限制,作者引入了一种双重方法,包括 模型小型化 和 减少采样步骤 ,旨在显著降低模型延迟。还是利用知识蒸馏来简化U-Net和图像解码器架构,并引入了一种利用特征匹配和分数蒸馏的创新的单步DM训练技术。
作者提出了两种模型,SDXS-512和SDXS-1024,分别在单个GPU上实现了大约100 FPS(比SD v1.5快30倍)和30 FPS(比SDXL快60倍)的推理速度。此外,我们的训练方法在图像条件控制中提供了有前途的应用,促进了有效的图像到图像的翻译。

1. Introduction
这是一篇小米的工作,实时进行图像到图像的生成。因为是要更多考虑手机的部署,所以要潜在解决的就是模型的大规模和多步骤采样的问题。
首先介绍一下什么是
NFE,即 Number of Function Evaluations,模型评估次数。对于常见的文生图模型,成本可以近似地计算为总延迟,其中包括文本编码器、图像解码器和去噪模型的延迟,乘以函数评估次数(NFEs)。
这里是直观的一个对比:

本文主要考虑减小 VAE解码器 和 UNet 的规模,两者都是资源密集型组件。作者还是通过蒸馏的 Loss 和 GAN Loss 来轻量化。
🤔这应该是和 stability 的那个 Turbo,UFO-Gen 的原理差不多
另外,为了减少 NFEs, 作者提出了一个快速和稳定的训练方法:
- 首先,我们建议通过将蒸馏损失函数替换为所提出的特征匹配损失函数,调整采样轨迹并将多步模型快速微调为一步模型。
- 然后,拓展了 Diff-Instruct 训练策略,利用特征匹配损失的梯度取代分数蒸馏在时间步长的后半部分提供的梯度。
💡 从预训练的扩散模型进行知识蒸馏(分数蒸馏) 都是 来自于 DreamFusion 这篇工作,感兴趣可以看看。
Diff-instruct: A universal approach for transferring knowledge from pre-trained diffusion models.
2. Preliiminaries
Score-based Model
所使用的损失函数的核心是分数匹配(SM)损失,其目的是使模型估计的分数与数据的真实分数之间的差异最小化:
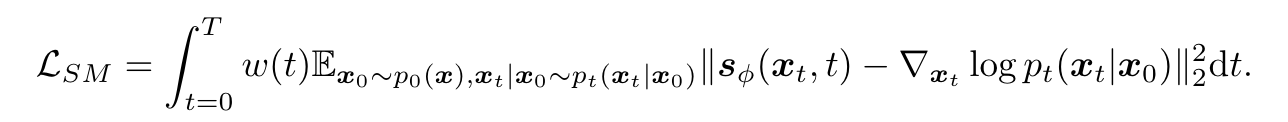
Diff-Instruct
Diff-Instruct 通过 Integral Kullback-Leibler (IKL)散度,将分数蒸馏引入到图像的生成过程,扩散模型其实实在拟合 p , q p, q p,q两个分布之间的差异。这里我们可以定义优化目标为:
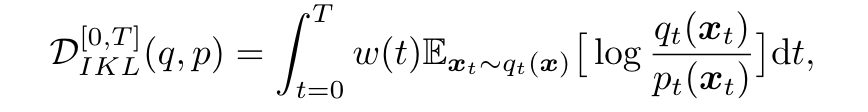
其中 q t q_t qt 和 p t p_t pt 代表 t t t 时刻扩散过程的边缘概率密度, q 0 q_0 q0 和 p 0 p_0 p0 之间的 IKL 梯度可以表示为:
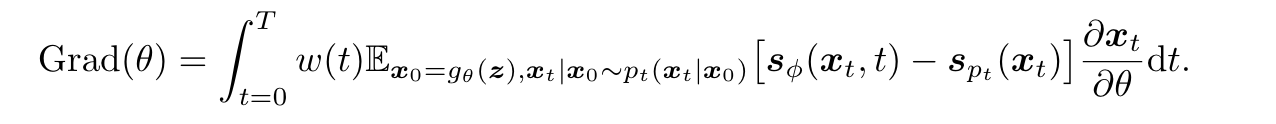
其中 x 0 = g θ ( z ) \boldsymbol{x}_0=g_\theta(\boldsymbol{z}) x0=gθ(z) 表示随机采样的高斯噪声 z z z 通过单步生成的 x 0 x_0 x0. s ϕ \boldsymbol{s}_\phi sϕ 和 s p t s_{p_t} spt 分别表示在线训练 Diffusion Model 和预训练 Diffusion Model的分数函数。
Diff-Instruct 直接使用这个梯度来更新模型,当两个分数函数的输出一致时,单步步生成器输出的边缘分布与预训练DM的边缘分布一致。
3. Method
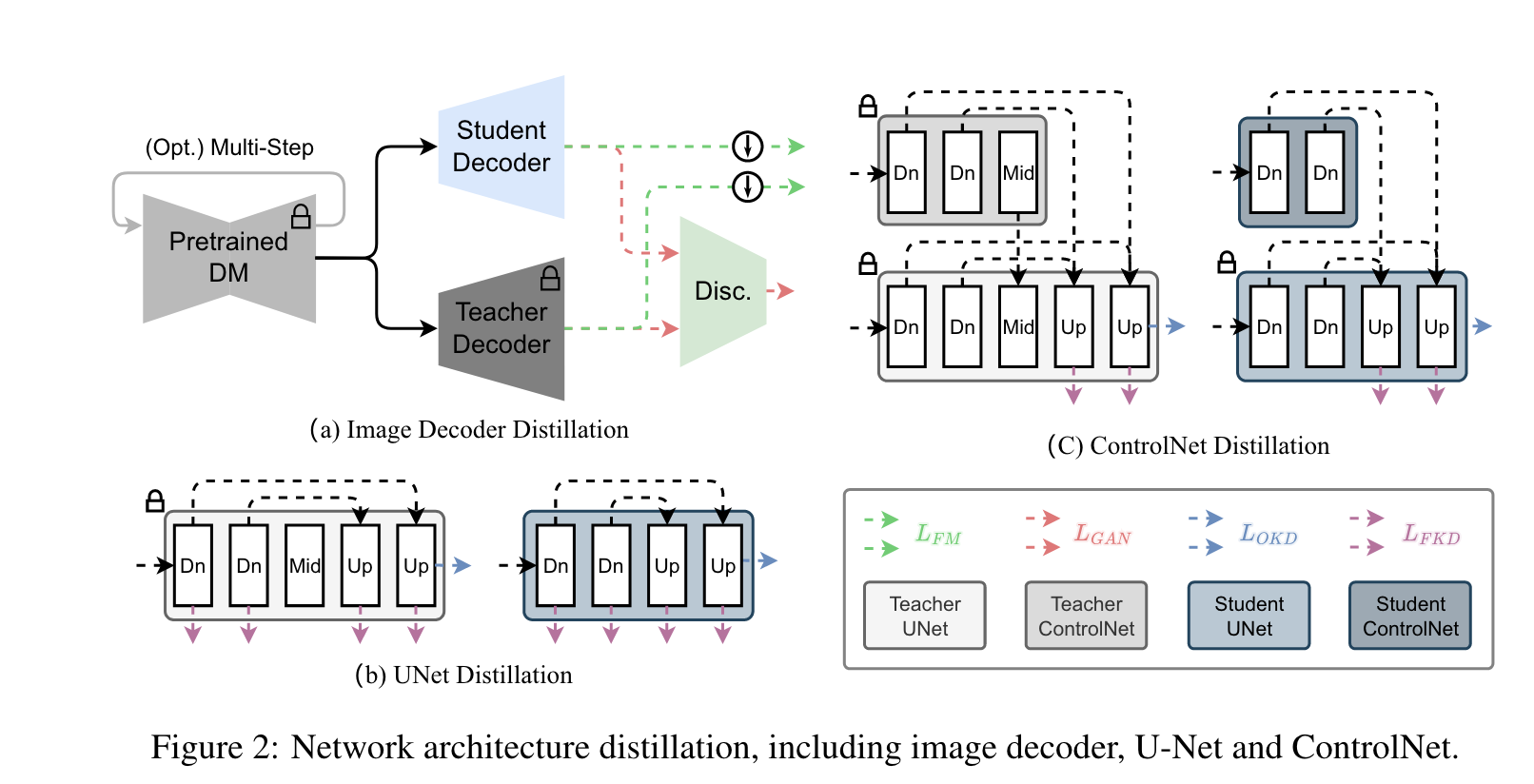
Architecture Optimization
VAE Decoder Distillation
原始的 VAE是通过平衡三种损失来优化的:重建、Kullback-Leibler (KL)散度和GAN损失。然而,在训练过程中平等地对待所有样本会引入冗余。利用预训练的扩散模型 F F F 对隐编码 z z z 进行采样,并利用预训练的VAE解码器对图像 x ~ \tilde{\boldsymbol{x}} x~ 进行重构,我们引入了VAE蒸馏(VD)损失来训练一个微小的图像解码器G:
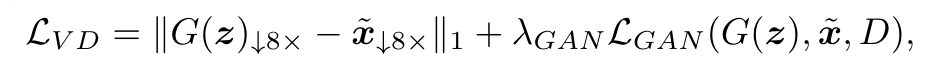
D D D 是 GAN 的判别器, λ G A N \lambda_{GAN} λGAN 用来平衡两个损失项, ∥ G ( z ) ↓ 8 × − x ~ ↓ 8 × ∥ 1 \|G(\boldsymbol{z})_{\downarrow8\times}-\tilde{\boldsymbol{x}}_{\downarrow8\times}\|_1 ∥G(z)↓8×−x~↓8×∥1 通过 8x 下采样的图像计算的 L1 损失来保持图像的细节。
UNet Distillation
受启发于 BK-sdm 的知识蒸馏策略,即有选择性地从U-Net中去除残余和Transformer块,旨在训练一个更紧凑的模型,该模型仍然可以有效地再现原始模型的中间特征映射和输出。图2 (b)说明了提取微小U-Net的训练策略。知识蒸馏通过输出知识蒸馏(OKD)和特征知识蒸馏(FKD)损失实现:
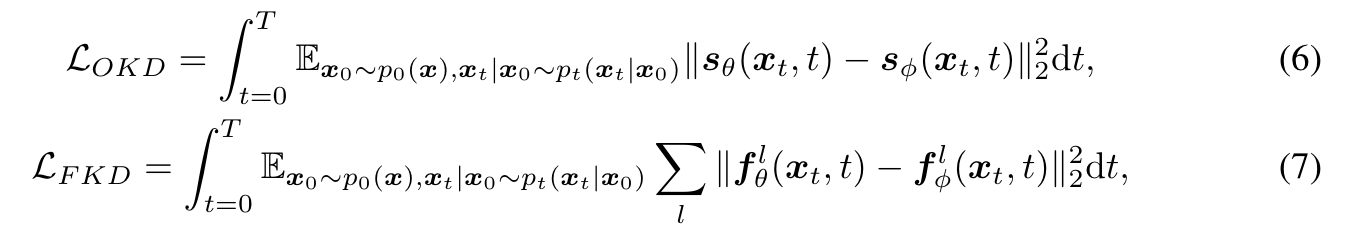
总体损失是两个损失函数的结合:

ControlNet
这里提一下 ControlNet。 ControlNet通过在现有的文本到图像框架中嵌入空间引导来增强扩散模型,从而实现图像到图像的任务,如素描到图像的翻译、绘画和超分辨率。它复制了U-Net的编码器架构和参数,增加了额外的卷积层来整合空间控制。尽管继承了U-Net的参数并使用零卷积来增强训练稳定性,ControlNet的训练过程仍然昂贵,并且受到数据集质量的显著影响。
为了解决这些挑战,我们提出了一种蒸馏方法,将原始U-Net的控制网提炼成相应的微型U-Net的控制网。如图2 (b)所示,我们不是直接提取ControlNet的零卷积输出,而是将ControlNet与U-Net结合起来,然后提取U-Net的中间特征映射和输出,这使得蒸馏后的ControlNet和微小的U-Net能够更好地协同工作。考虑到ControlNet不影响U-Net编码器的特征映射,特征蒸馏只应用于U-Net的解码器
One-Step Training
虽然dm在图像生成方面表现出色,但即使使用先进的采样器,它们对多个采样步骤的依赖也会带来显著的推理延迟为了解决这个问题,之前的研究引入了知识蒸馏技术,如渐进式蒸馏和一致性蒸馏,旨在减少采样步骤并加速推理。然而,这些方法通常只能通过4 ~ 8个采样步骤产生清晰的图像,这与GAN中的一步生成过程形成鲜明对比。
探索将GAN整合到DM训练体系中已经显示出增强图像质量的希望。然而,GAN也有自己的挑战,包括对超参数的敏感性和训练不稳定性。对于一步生成模型,有必要寻求一种更稳定的训练策略。
Feature Matching Warmup
通常做法是是训练一个单步模型,即:初始采样一个噪声 ϵ \epsilon ϵ,然后使用常微分方程求解器 ψ \psi ψ 来进行采样最终得到生成图像 x ^ 0 \boldsymbol{\hat{x}}_{0} x^0。
然而,这种方法经常导致产生低质量的图像。潜在的问题是使用来自预训练DM的ODE采样器生成的噪声图像对的采样轨迹中的交叉,导致不适定问题。整流通过调整采样轨迹解决了这一挑战。它取代了训练目标,并提出了一个“回流”策略来完善配对从而最小化轨迹交叉。相反,我们注意到采样轨迹的交叉会导致一个噪声输入对应于多个真地图像,导致训练模型生成的图像是多个可行输出的加权和,权重为 w ( y ) w(y) w(y):
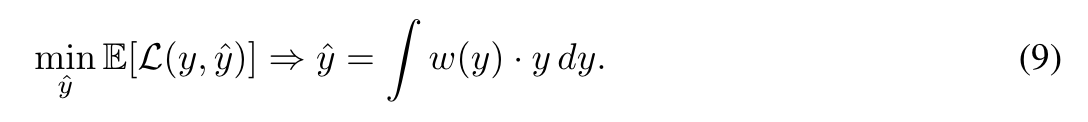
对于最常用的均方误差(mean square error, MSE)损失,该模型在包含多个可行目标的情况下,倾向于输出多个可行解的平均值,以使整体误差最小化,从而导致生成的图像模糊。 为了解决这个问题,我们探索了替代损失函数,改变加权方案,优先考虑更清晰的图像。在大多数情况下,我们可以使用L1损失、感知损失和LPIPS损失来改变权重的形式。我们建立在特征匹配方法的基础上,该方法涉及计算编码器模型生成的中间特征映射上的损失。具体来说,我们从dist损失中获得灵感,在这些特征映射上应用结构相似指数(SSIM),以获得更精细的特征匹配损失:
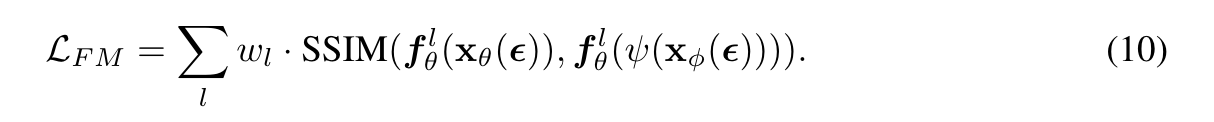
其中
w
l
w_l
wl 是 SSIM 损失的权重,通过编码器
f
θ
\boldsymbol{f_\theta}
fθ 编码的第 l-th 中间特征上计算得到的 SSIM 损失,
x
θ
(
ϵ
)
\boldsymbol{x_\theta(\epsilon)}
xθ(ϵ) 是由微型的 U-Net
x
θ
\boldsymbol{x_\theta}
xθ 生成的图像,
ψ
(
x
ϕ
(
ϵ
)
)
\boldsymbol{\psi(x_\phi(\epsilon))}
ψ(xϕ(ϵ)) 是由原始的 U-Net
x
ϕ
\boldsymbol{x_\phi}
xϕ 用ODE采样器
ψ
\boldsymbol{\psi}
ψ 生成的图像。在实践中,我们发现使用预训练的CNN骨干网、ViT骨干网和DM U-Net编码器都能获得良好的效果,与MSE损失的对比如图6所示。此外,我们还利用现有的微调方法(如LCM)拉直模型的轨迹以缩小可行输出的范围,或者直接使用公开可用的少步模型。我们将单独使用
L
F
M
L_{FM}
LFM来训练一步模型作为热身,只依赖少量的训练步骤。
Segmented Score Distillation.
虽然特征匹配损失可以产生几乎清晰的图像,但不能达到真正的分布匹配,所以训练好的模型只能作为正式训练的初始化。为了解决这一差距,我们详细阐述了diffi - directive中使用的训练策略,该策略旨在通过匹配时间步长的边际分数函数,使模型的输出分布与预训练模型的输出分布更接近。然而,由于需要在 t → T t \to T t→T处加入高水平的噪声才能计算目标分数,因此此时估计的分数函数是不准确的。我们注意到扩散模型的采样轨迹从粗到细,这意味着 t → t t \to t t→t,分数函数提供低频信息的梯度,而 t → 0 t \to 0 t→0,它提供高频信息的梯度。因此,将时间步长分为 [ 0 , α T ] [0, \alpha T] [0,αT] 和 ( α T , T ] (\alpha T, T] (αT,T]两段,后者用 L F M L_{FM} LFM 代替,因为它能提供足够的低频梯度。这一策略可以正式表示为:
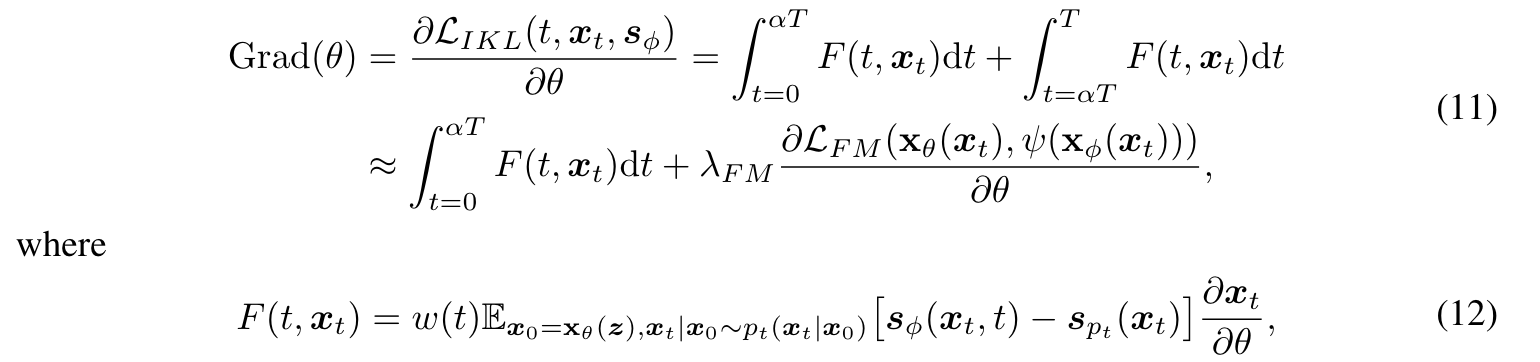
λ F M \lambda_{FM} λFM 用于平衡两段的梯度, α ∈ [ 0 , 1 ] \alpha \in [0, 1] α∈[0,1]。我们有意将 α \alpha α 设置为接近1, λ F M \lambda_{FM} λFM 设置为较高值,以确保模型的输出分布平滑地与预训练分数函数预测的分布对齐。在概率密度达到显著重叠后,我们逐渐降低 α \alpha α 和 λ F M \lambda_{FM} λFM。图3直观地描述了我们的训练策略,其中离线DM表示预训练DM的U-Net,在线DM从离线DM初始化,并通过Eq.(1)对生成的图像进行微调。在实践中,在线DM和学生DM交替训练,如算法1所示。

LoRA
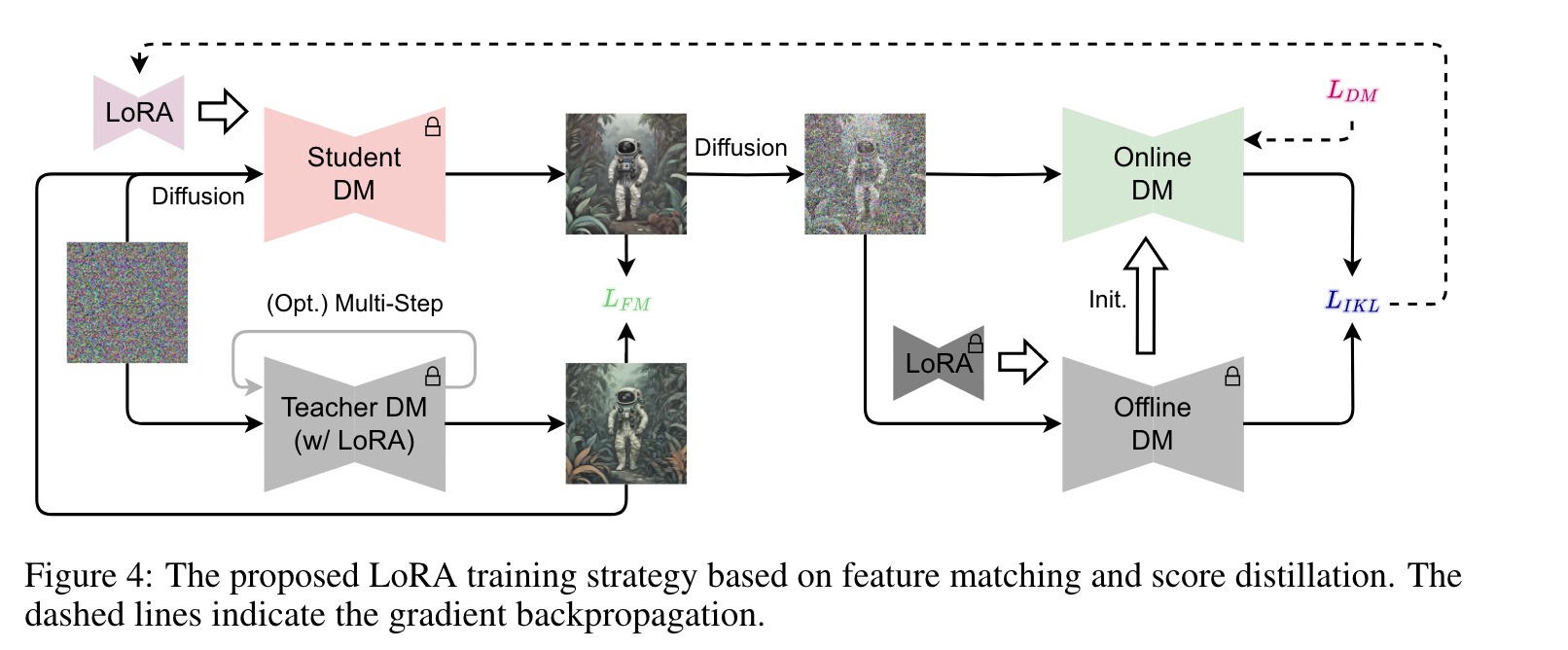
一旦训练了一步DM,就可以像其他DM一样对其进行微调,以调整生成图像的样式。我们将LoRA与提出的分段分数蒸馏(Segmented Score Distillation)结合起来,对一步DM进行微调,如图4所示。
具体来说,我们将预训练的LoRA插入到离线DM中,如果它也与教师DM兼容,它也被插入到离线DM中。值得注意的是,我们没有将LoRA插入到在线DM中,因为它对应于一步DM的输出分布。然后,我们使用与一步训练相同的训练过程,但跳过特征匹配预热,因为LoRA微调比完全微调稳定得多。此外,当Teacher DM不能包含预训练的LoRA时,我们使用简化的λF M。通过这种方式,可以将预训练的LoRA提取到SDXS的LoRA中。
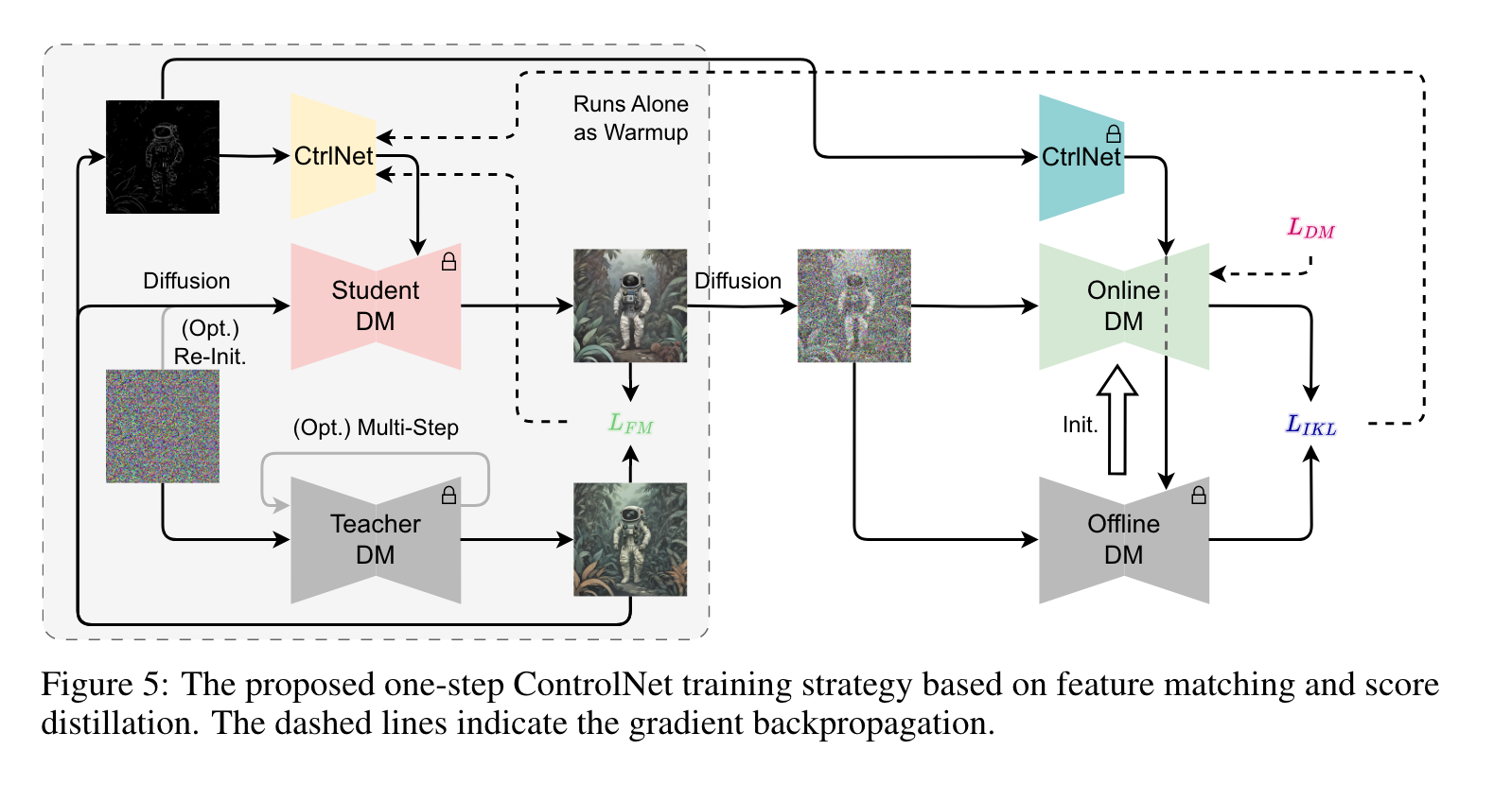
ControlNet
我们的方法也可以用于训练ControlNet,使微小的一步模型能够将图像条件合并到其图像生成过程中,如图5所示。与文本到图像生成的基本模型相比,这里训练的模型是蒸馏的ControlNet,伴随着前面提到的微小的U-Net, U-Net的参数在训练过程中是固定的。重要的是,我们需要从教师模型采样的图像中提取控制图像,而不是从数据集图像中提取,以确保噪声、目标图像和控制图像形成配对三元组。此外,原始的多步U-Net附带的预训练控制网与在线U-Net和离线U-Net集成,但不参与培训。与文本编码器类似,该函数仅限于作为预训练的特征提取器。这样,为了进一步降低L,训练后的ControlNet就是学习利用从目标图像中提取的控制图像。同时,分数蒸馏鼓励模型匹配边缘分布,增强生成图像的上下文相关性。值得注意的是,我们发现用新初始化的噪声替换U-Net的一部分噪声输入可以增强控制能力。
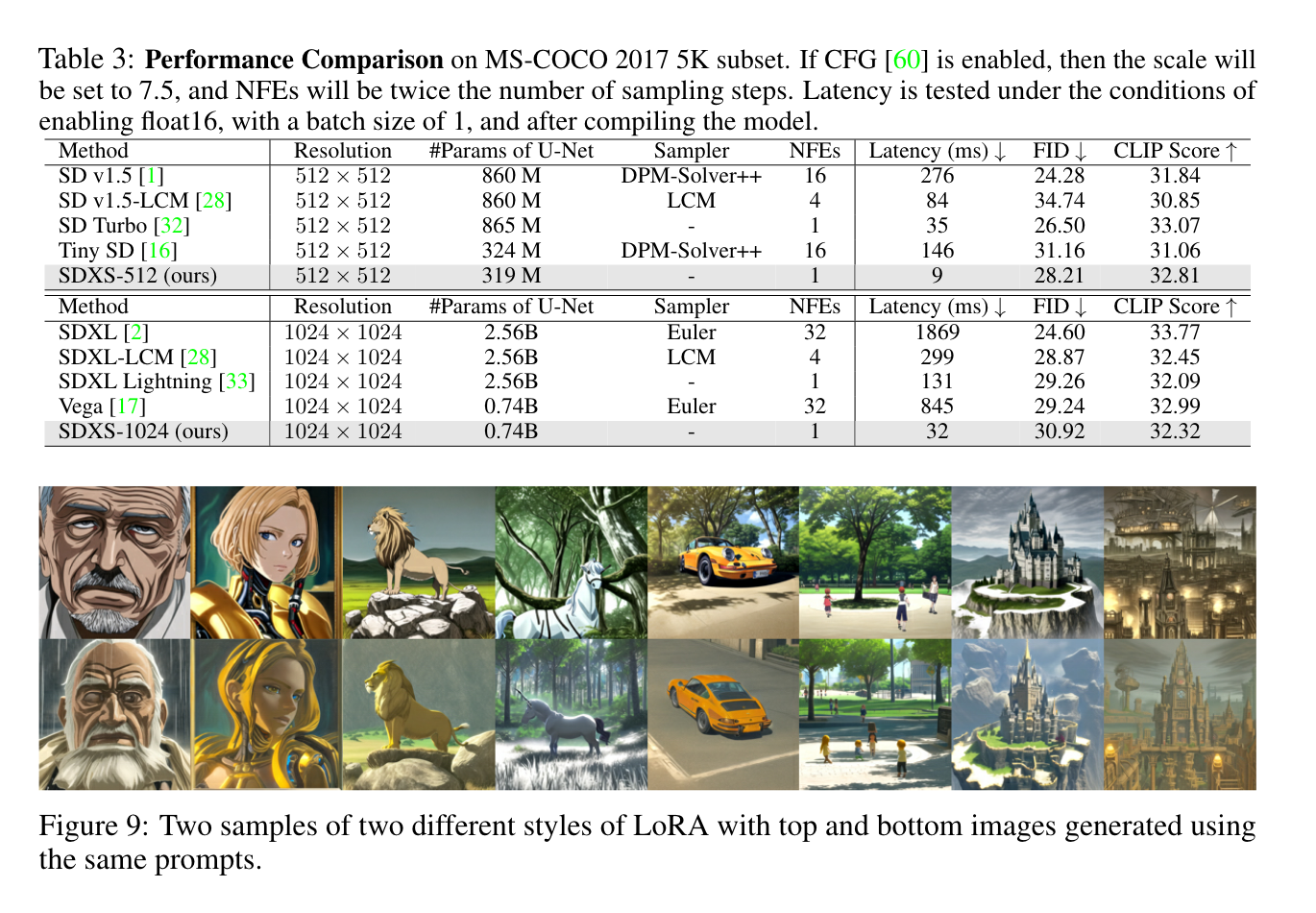
4. Experiments
实现细节。我们的代码是基于diffusers库开发的。由于我们无法访问SD v2.1 base和SDXL的训练数据集,因此整个训练过程几乎是无数据的,仅依赖于可公开访问的数据集中的提示(Laion-5B)。必要时,我们使用开源预训练模型与这些提示相结合来生成相应的图像。为了训练我们的模型,我们将训练小批大小配置为1024到2048。为了在可用硬件上容纳这个批处理大小,我们在必要时战略性地实现梯度累积。值得注意的是,我们发现所提出的训练策略导致模型生成的图像纹理较少。因此,在训练之后,**我们利用GAN损失和极低秩的LoRA进行短时间的微调。**当需要GAN损失时,我们使用StyleGAN-T中的投影GAN损失,基本设置与ADD一致。对于SDXS-1024的训练,我们使用SDXL的精简版Vega作为在线DM和离线DM的初始化,以减少训练开销。



5. Conclusion
本文探讨了基于大规模扩散的文本到图像生成模型的升华,使其能够在gpu上进行实时推理。首先,我们使用知识蒸馏来压缩U-Net架构和图像解码器。随后,我们引入了一种新的训练策略,利用特征匹配和分数蒸馏将采样过程减少到一步。这种方法允许在单个GPU上实时生成1024×1024图像,保持与原始模型相当的质量。此外,我们提出的训练方法也可以适应涉及图像条件生成的任务,避免了预训练的ControlNet的直接适应。我们相信,在边缘设备上部署高效的图像条件生成代表了未来研究的一个有希望的途径,并计划探索其他应用,如喷漆和超分辨率。















 731
731











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









