



注意力机制
名词来源:
人们会把注意力更多投入到人的脸部,文本的标题以及文章首句等位置,这样使人类能够利用有限的注意力资源从大量信息中快速获取高价值的信息,极大地提升了大脑处理信息的效率。
注意力机制(Attention Mechanism)的定义:
机器学习中的一种数据处理方法,允许机器学习模型在处理输入数据时,动态地选择性地关注与当前任务最相关的部分,同时忽略无关信息。其核心思想是通过计算输入元素的重要性权重,将有限的资源集中在关键信息上,从而提升模型的性能和解释性。
例如,在机器翻译任务中,当我们把一段源语言文本翻译成目标语言时,注意力机制能够让模型在生成目标语言每个词的时候,自动地、有侧重地回溯到源语言句子中与之最相关的词或短语部分,而不是机械地逐词对应翻译。它就好像是给模型配备了一种 “聚焦” 能力,使得模型可以优先聚焦于那些对当前任务来说最重要的输入信息片段,从而提高信息处理的效率和效果,让模型的输出更加精准、合理且符合语义逻辑等要求。
注意力机制的原理:
注意力机制对不同信息的关注程度(重要程度)由权值来体现,注意力机制可以视为查询矩阵(Query)、键(key)以及加权平均值(Value)构成了多层感知机。计算:给定Target中的某个元素Query,通过计算Query和各个Key的相似性或相关性,得到每个Key对应Value的权重系数,然后对Value进行加权求和,即得到最终的Attention数值。
Attention从大量信息中有选择地筛选出少量重要信息并聚焦到这些重要信息上,忽略大多不重要的信息。聚焦的过程体现在权重系数的计算上,权重越大,越聚焦在对应的Value值上,即权重代表了信息的重要性,而Value是其对应的信息。
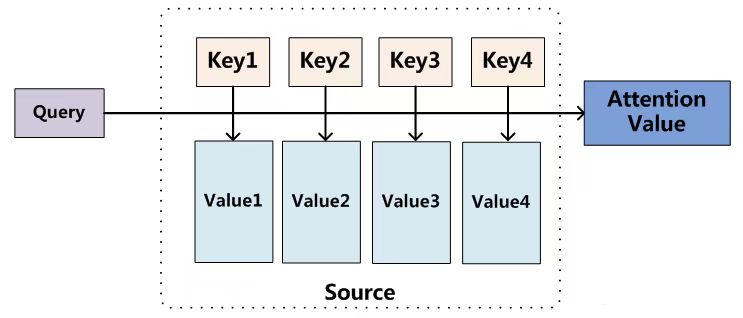
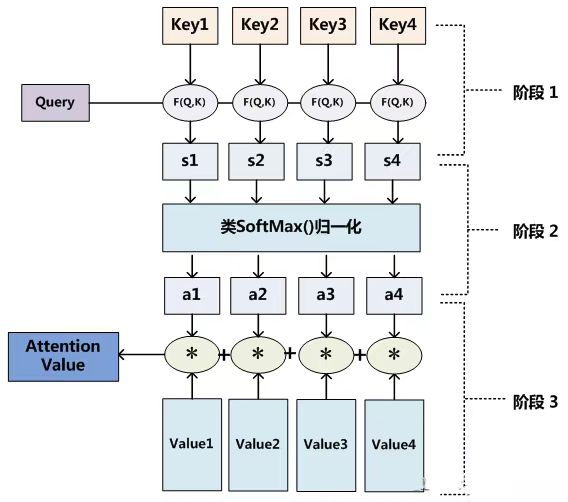
注意力机制的计算过程:
大多数方法采用的注意力机制计算过程可以细化为如下三个阶段。
三阶段的注意力机制计算流程:
-
第一阶段,计算 Query和不同 Key 的相关性,即计算不同 Value 值的权重系数;
-
第二阶段,对上一阶段的输出进行归一化处理,将数值的范围映射到 0 和 1 之间。
-
第三阶段,根据权重系数对Value进行加权求和,从而得到最终的注意力数值。
注意力机制是一种在信息处理过程中,动态地对输入的不同部分分配不同程度关注权重的机制,它在多个领域都有广泛应用,并且具有一定的优缺点,以下是具体介绍:
注意力机制的应用:
-
自然语言处理:在机器翻译任务中,注意力机制能够让模型在生成目标语言每个词的时候,自动地、有侧重地回溯到源语言句子中与之最相关的词或短语部分,从而生成更准确、自然的翻译结果。在文本生成任务中,如写作文、创作故事等,注意力机制可以帮助模型更好地把握上下文的连贯性和逻辑性,生成更符合语义和主题的文本。此外,在情感分析、阅读理解等任务中,也能通过关注文本中的关键信息,提高模型的分析和理解能力。
-
计算机视觉:用于图像分类时,注意力机制可以自动聚焦于图像中与分类任务最相关的区域,例如在识别一张包含多种物体的图片时,模型能够将注意力集中在最有代表性的物体部分,从而提高分类的准确性。在目标检测任务中,有助于模型更精准地定位和识别出图像中的目标物体,减少误检和漏检的情况。对于图像生成任务,注意力机制可以使生成的图像更加逼真、合理,符合人们的视觉认知。
-
语音识别与合成:在语音识别过程中,注意力机制通过计算语音信号中不同帧之间的相关性,使模型能够更准确地识别出语音内容,尤其是一些带有口音、语速较快或较慢的语音信号。在语音合成方面,可以让合成的语音更加自然、连贯、富有情感,更好地模拟人类的语音表达。
-
图神经网络:在节点级别的任务中,注意力机制可以用来对节点之间的关系进行建模和加权,帮助模型更好地理解图中节点的相互作用。在图级别的任务中,可以用来对图中不同部分的重要性进行建模,从而提升图神经网络对图结构数据的处理能力。
-
多模态学习:注意力机制可以对齐不同模态之间的语义关联,例如在视觉和文本模态的多模态内容理解中,通过对齐两者的语义信息,使模型能够更全面、深入地理解多模态内容,有助于实现更高效的跨模态信息交互和融合。
缺点
-
注意力权重解释难度大:虽然注意力机制可以提供一定的可解释性,但注意力权重的计算对人类来说可能并不直观,存在被误解的风险,有时权重分布可能并不符合人们的直觉或预期,可能导致对模型决策过程的错误解读。
-
过拟合风险:在训练数据有限的情况下,注意力机制可能会过拟合训练数据,导致模型在面对新的、未见过的数据时性能下降,泛化能力受限。
-
数据依赖性:通常需要大量的数据进行训练,以便网络能够学习到正确的注意力权重,如果数据量不足或数据质量不高,可能会影响模型的性能和稳定性。
-
模型复杂性增加:引入注意力机制会使模型的结构和参数数量增多,增加了模型的复杂性,这可能会导致训练难度增大,调参过程更加复杂,同时也对模型的部署和维护提出了更高的要求。
自注意力机制(Self-Attention Mechanism)
概念:
自注意力机制(Self-Attention)作为注意力机制中的一种,也被称为intra Attention(内部Attention),是Transformer的重要组成部分。内部注意力机制,顾名思义,是一种将单个序列的不同位置关联起来以计算同一序列的表示的注意机制。
通过对注意力机制的学习我们知道,在一般任务的Encoder-Decoder框架中,输入Source和输出Target内容是不一样的,比如对于英-中机器翻译来说,Source是英文句子,Target是对应的翻译出的中文句子,Attention机制发生在Target的元素Query和Source中的所有元素之间(即Attention机制与自身还有关注对象都有关系)。
而Self-Attention顾名思义,指的不是Target和Source之间的Attention机制,而是Source内部元素之间或者Target内部元素之间发生的Attention机制,也可以理解为Target=Source这种特殊情况下的注意力计算机制。(即Self-Attention只关注输入本身or只关注关注对象本身)
例子:
以下是一个实际的例子来说明自注意力机制(Self - Attention)和普通注意力机制(Attention)的区别:
场景设定
假设我们需要将英文句子翻译成中文:
-
英文输入(编码器输入):
The animal didn't cross the street because it was too tired. -
中文输出(解码器生成):
那只动物没有过马路,因为它太累了。
1. 自注意力(Self-Attention)的作用
应用位置:编码器内部(处理输入序列内部的关系) 目标:理解英文句子中每个词与其他词的关系,解决指代和长距离依赖问题。
具体例子
-
问题:英文句中的
it指代的是animal还是street? -
自注意力过程:
-
编码器在处理
it时,会计算it与句子中所有其他词(如animal,street,tired等)的关联性。 -
通过注意力权重发现:
it与animal和tired的关联性更高,而与street关联性较低。 -
结果:编码器最终将
it的语义表示为与animal和tired相关的上下文信息,从而正确理解it指代的是animal。
-
关键特点
-
输入和输出在同一序列:所有查询(Query)、键(Key)、值(Value)均来自同一个英文句子。
-
捕捉内部结构:通过词与词之间的关联,解决指代消解、语义依赖等问题。
2. 普通注意力(跨注意力,Cross-Attention)的作用
应用位置:解码器与编码器之间(连接输入序列与输出序列) 目标:在生成中文翻译时,动态关注英文输入中的相关部分。
具体例子
-
问题:解码器生成中文词
它时,需要知道对应的英文词是it。 -
跨注意力过程:
-
解码器生成
它时,将当前解码器位置(它)作为查询(Query)。 -
用 Query 与编码器的所有输出(英文词的 Key)计算相似度,得到注意力权重。
-
权重最高的英文词是
it,因此解码器会聚焦于编码器中it对应的信息(Value)。 -
结果:解码器正确将
它翻译为it的指代内容(即animal)。
-
关键特点
-
输入和输出在不同序列:Query 来自解码器(中文生成位置),Key 和 Value 来自编码器(英文输入)。
-
对齐不同模态:建立源语言(英文)和目标语言(中文)之间的对应关系。
| 特性 | 自注意力(Self-Attention) | 普通注意力(Cross-Attention) |
|---|---|---|
| 输入来源 | 同一序列(如编码器的英文输入) | 不同序列(编码器的输出 vs 解码器的输入) |
| 目标 | 理解序列内部关系(如指代消解) | 对齐不同序列(如翻译中的词对齐) |
| 应用位置 | 编码器内部或解码器内部 | 编码器与解码器之间 |
| Q/K/V来源 | Q、K、V均来自同一序列 | Q来自解码器,K、V来自编码器 |
| 典型任务 | 捕捉长距离依赖(如Transformer编码器) | 机器翻译、文本生成(如Transformer解码器) |
直观类比
-
自注意力:像阅读一篇文章时,反复回顾前文,理清句子内部的逻辑关系(如“它”指代谁)。
-
普通注意力:像翻译时,每写一个目标语言的词,就回头查看原文中对应的关键部分(如“它”对应原文的“it”)。
通过这种对比,可以清晰看到自注意力关注内部结构理解,而普通注意力关注跨序列信息对齐。两者结合(如Transformer模型)能显著提升模型对复杂任务的处理能力。
总结
-
计算对象 :普通注意力机制计算的是解码器状态和编码器输出之间的关系,自注意力机制计算的是输入序列内部各单词之间的关系。
-
应用场景 :普通注意力机制多用于序列到序列的模型,如机器翻译、文本生成等;自注意力机制则在 Transformer 架构中广泛应用于自然语言处理的各个任务,如文本分类、阅读理解等,也可用于其他需要对序列内部关系进行建模的场景。
多头注意力(Multi-Head Attention)
因为一段文字可能蕴含了比如情感维度、时间维度、逻辑维度等很多维度的特征,为了能从不同的维度抓住输入信息的重点,chatGPT使用了多头注意力机制(multi-head attention)
而所谓多头注意力,简单说就是把输入序列投影为多组不同的Query,Key,Value,并行分别计算后,再把各组计算的结果合并作为最终的结果,通过使用多头注意力机制,ChatGPT可以更好地捕获来自输入的多维度特征,提高模型的表达能力和泛化能力,并减少过拟合的风险。
多头注意力机制的目的是为了从多个维度捕捉提取更多的特征,从多个“头”得到不同的Self-Attention Score,提高模型表现。
多头注意力机制(Multi-Head Attention)是注意力机制的一种扩展形式,通过并行运行多个独立的注意力头,从不同子空间(subspace)捕捉输入序列中多样化的关联模式。它与普通的单头注意力(如自注意力或跨注意力)的核心区别在于:多视角建模和信息融合能力。
以下通过一个机器翻译的实例,对比说明多头注意力与普通单头注意力的区别:
场景设定
任务:将英文句子翻译为中文:
-
输入(编码器):
The cat sat on the mat because it was soft. -
输出(解码器):
猫坐在垫子上,因为它很柔软。
关键问题:
-
英文中的
it指代cat还是mat? -
如何捕捉
soft与mat的修饰关系?
1. 普通单头注意力(以自注意力为例)
-
单头注意力过程: 编码器在处理
it时,通过单一注意力头计算与所有输入词的关联权重。-
可能发现
it与cat(主语句子主语)和soft(形容词)的关联性较高。 -
但由于单头注意力仅通过一个权重矩阵建模,可能无法同时明确区分指代关系和属性修饰关系。
-
局限性: 单一注意力头可能混合多种语义关系(如语法依赖、指代、修饰等),导致信息模糊。
2. 多头注意力机制
-
多头设计:
-
将输入向量拆分为多个子空间(例如4个头),每个头独立学习不同的注意力模式。
-
每个头的查询(Query)、键(Key)、值(Value)通过不同的权重矩阵生成。
-
最终将所有头的输出拼接后线性变换,形成最终结果。
-
具体例子分析
假设使用 4个注意力头,在处理英文输入时,不同头可能捕捉以下关系:
头1:主语-代词指代
-
关注
it与cat的指代关系,权重集中在cat上。 -
作用:明确
it指代的是cat(而非mat)。
头2:属性修饰关系
-
关注
soft与mat的关联,权重集中在mat上。 -
作用:理解
soft是描述mat的属性。
头3:动作-位置关系
-
关注
sat与on the mat的位置关系,权重集中在sat和mat上。 -
作用:建立动作与位置的关联(猫坐在垫子上)。
头4:因果逻辑
-
关注
because连接的前后因果关系,权重分布在cat sat和soft之间。 -
作用:理解句子中的因果逻辑(因为垫子软,所以猫坐下)。
多头注意力的优势
| 对比维度 | 普通单头注意力 | 多头注意力 |
|---|---|---|
| 建模能力 | 单一视角捕捉全局关系 | 多视角捕捉语法、指代、逻辑等多样化关系 |
| 鲁棒性 | 易受噪声干扰(如歧义指代) | 多个头共同投票,降低错误权重的影响 |
| 信息融合 | 所有信息混合在一个注意力分布中 | 不同头独立学习后再融合,保留多样性 |
| 并行计算 | 单线程计算 | 多个头可并行计算,提升效率 |
直观对比示例
假设输入句子为:The bank of the river is covered with sand.
-
单头注意力:可能混淆
bank的两种含义(河岸 vs 银行)。 -
多头注意力:
-
头1:根据
river和sand,确定bank指“河岸”。 -
头2:捕捉
covered with与sand的修饰关系。 -
头3:分析
of the river的介词结构。 -
头4:排除无关语义(如“银行”)。
-
总结
-
多头注意力 vs 普通注意力: 多头机制通过并行化多组注意力头,使模型能够同时关注输入序列中不同类型的依赖关系(如语法、语义、逻辑),而单头注意力只能通过单一视角建模。
-
实际应用: 在Transformer模型中,多头注意力是核心组件,例如:
-
编码器自注意力:多视角分析输入句子的内部结构。
-
解码器跨注意力:多视角对齐源语言(输入)和目标语言(输出)。
-
多头注意力通过分治策略(不同头关注不同模式)和信息融合(拼接后线性变换),显著提升了模型对复杂语义关系的建模能力。
注意力机制、自注意力机制与多头注意力机制的对比总结
| 特性 | 注意力机制 (Attention) | 自注意力机制 (Self-Attention) | 多头注意力机制 (Multi-Head Attention) |
|---|---|---|---|
| 定义 | 动态选择输入中与当前任务相关的部分,忽略无关信息。 | 同一序列内部元素间计算注意力,捕捉长程依赖。 | 并行运行多个自注意力头,捕捉多样化的关联模式。 |
| 输入来源 | 不同序列(如编码器输入与解码器输出)。 | 同一序列(如编码器的输入或解码器的中间状态)。 | 同一序列(通过多个子空间拆分)。 |
| 核心目标 | 对齐不同序列的关键信息(如跨语言翻译)。 | 理解序列内部结构(如代词指代、语义依赖)。 | 多视角建模,捕捉不同维度的语义关系。 |
| 关键组件 | Query(目标序列)、Key/Value(源序列)。 | Query/Key/Value均来自同一序列。 | 多个独立的自注意力头,拼接后线性变换。 |
| 计算方式 | 计算目标元素(Query)与源元素(Key)的相似性。 | 计算序列内部元素之间的相似性。 | 每个头独立计算自注意力,结果拼接融合。 |
| 典型应用场景 | 机器翻译(编码器-解码器对齐)、文本生成。 | Transformer编码器、文本分类、长文本理解。 | Transformer模型(编码器和解码器均使用)。 |
| 优点 | 解决长距离依赖问题,提升跨序列对齐精度。 | 捕捉序列内部复杂关系,增强上下文感知。 | 提升模型表达能力,减少过拟合,支持并行计算。 |
| 缺点/挑战 | 依赖跨序列对齐质量,易受噪声干扰。 | 对计算资源需求高,长序列可能导致注意力分散。 | 参数增多,模型复杂度显著增加。 |
| 直观示例 | 翻译时生成“它”关注源句中的“it”。 | 确定“it”指代“animal”而非“street”。 | 同时捕捉“it”的指代关系、“soft”的修饰关系等。 |
核心区别总结
-
注意力机制:关注跨序列关系(如编码器-解码器),解决对齐问题。
-
自注意力:聚焦同一序列内部关系,解决长程依赖和语义理解。
-
多头注意力:通过多组自注意力并行计算,增强模型对复杂模式的捕捉能力。

















 468
468

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









