









系统概述
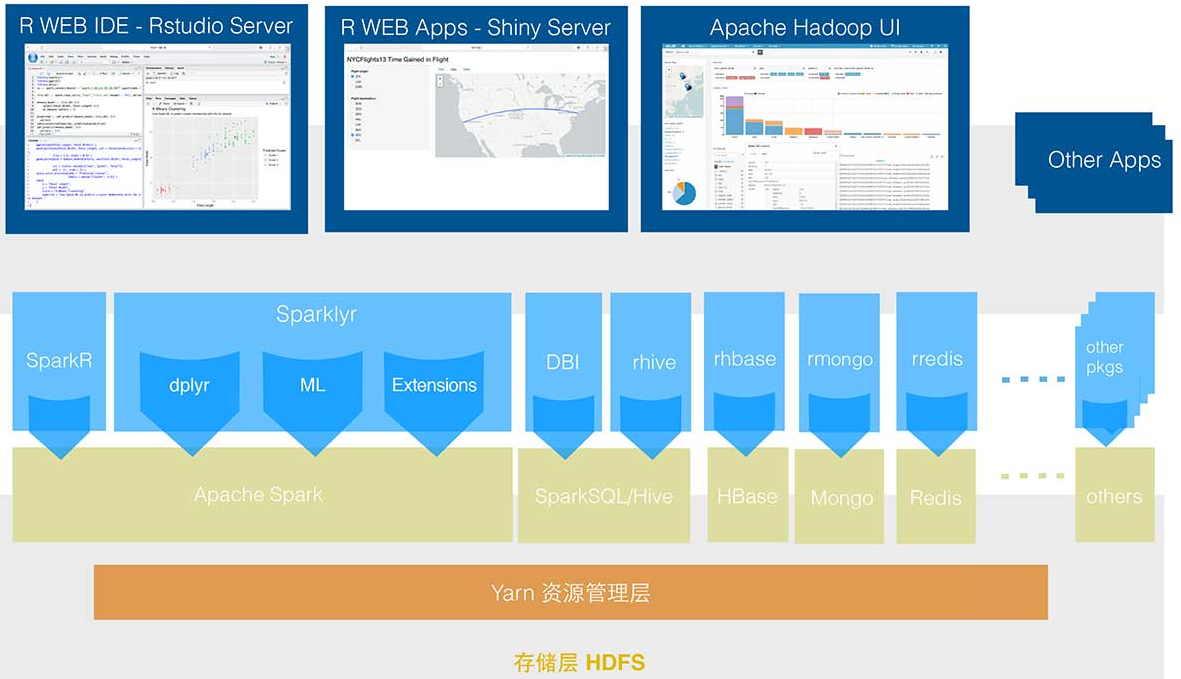
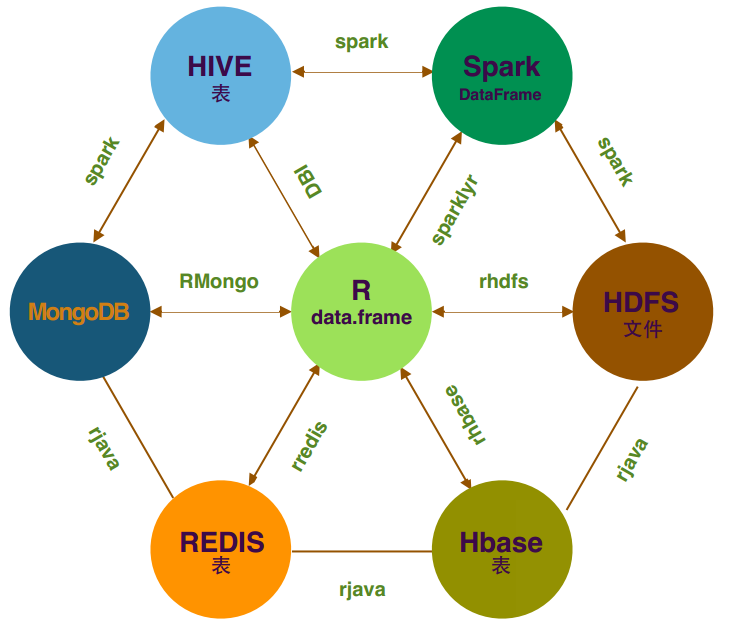
在日常业务分析中, R是非常常用的分析工具,而当数据量较大时,用R语言需要需用更多的时间来完成训练模型,spark作为大规模数据计算框架,采用内存计算,可以短时间内完成大量的数据的处理及计算模型,但缺点是不能图形展示, R语言的sparkly则提供了R语言和Spark的接⼝,实现了在数据量大的情况下,应用Spark的快速数据分析和处理能力结合R语言的图形化展示功能,方便业务分析,模型训练,同时R语言还可以与Hadoop,HDFS,Hbase,redis,MongoDB等大数据平台数据实现交互,以及作业递交与分析,本文主要介绍平台的架构方法,以及各个组件基本使用方法。
系统构建与调试
基础环境介绍:操作系统 RHEL 6.5 / CentoOS 6.5
已安装软件 Hadoop Hbase Hive Spark Redis MongoDB Mysql 等大数据应用软件
























 784
784

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









