







Abstract
- 单深度图像的手部姿态估计近年来取得了很大的进展,但目前的数据处理方法还不能满足人机交互等应用要求。 一个可能的原因是现有的方法试图学习所有类型手部深度图像的一般回归函数。 为了解决这个问题,我们提出了一种新的“分而治之”方法,包括分类步骤和回归步骤。 首先,使用卷积神经网络分类器将输入手深图像分类为不同类型。然后,利用一个有效且有效的多路径级联随机森林回归器来估计手关节的三维位置。 实验证明,该方法在具有挑战性的数据集上达到了最先进的性能。此外,该方法可以很容易地与其他回归方法相结合。
Introduction
- 近年来,无标记视觉观测中的人体和手等三维关节物体姿态估计问题因其在人机交互、增强现实(AR)、运动感知游戏、机器人控制等方面的广泛应用而得到了广泛的研究。在早期阶段,研究人员估计了2D RGB图像或视频的手势。随着硬件技术的发展,特别是近年来出现了MicroSoft Kinect,PrimeSense和Intel RealSense等低成本商品深度相机。在引入深度传感器之后,RGB-D数据的人体和手姿势估计已经显着进步。
- 由于人手具有较大的视点方差,自我遮挡和手指之间的相似性,基于无标记视觉观察的手姿势估计仍然是一项具有挑战性的任务。尽管这是一个极其困难的问题,但近年来已经提出了许多关于手姿态估计的文献。 在调查[27]中,基于视觉的无标记手部跟踪算法大致分为两种类型,基于模型和基于外观的方法。
- 基于模型的方法通常为输入数据建立一个手模板来估计手的姿势。姿态估计可以表述为一个优化问题或最近邻搜索问题。 最近,Sridhar等人在多摄像机设置中提出了一种精确的基于模型的手部跟踪方法,目的是解决严重的自我遮挡问题。虽然多个摄像机设置可以实现更精确的姿势恢复,但复杂的采集设置和手动校准不太适合消费级应用。在[4,16,31,32]中,3D手姿势通过逆运动学技术重建,这种技术优化了非常难以找到全局最小值的非线性能量函数。上述方法的数值优化算法通常复杂,耗时且易于陷入局部极小值。 因此,它限制了它们在实时和准确应用中的用途。
- 另一方面,基于外观的方法使用直接映射技术,该技术试图学习从输入图像空间到输出姿势空间的直接映射。在过去几年中,基于最近邻搜索[20,28],决策森林[5,6,8,18,33,34]或卷积网络[21,23,26,35]的众多基于外观的方法已有 被开发用于手姿势估计。在[5]中,Keskin等人介绍了一个多层次的随机决策森林框架。他们将整个分类任务划分为两个分类阶段,只关注不同的学习任务,使整个学习任务更加高效准确。最近,Sun等人提出了一种具有3D姿态索引特征的级联层次回归方法。 虽然3D姿势索引功能实现了近似严格的3D不变性,但级联框架增强了学习能力。仅通过一个回归模型处理复杂的手势估计是非常困难的。 因此,通过引入多路回归模型来提高整体学习能力是一个不错的选择。
- 在本文中,我们提出了一种新的“分而治之”分类引导回归学习框架来估计单一深度图像的手势。首先,为了减少回归的搜索空间,引入基于卷积网络的分类器来预测手势类型。针对不同手势类型的级联随机森林回归器在训练数据集的不相交部分上进行训练。然后基于预测的分类器类别,选择相应的回归量来估计最终的手势。这意味着分类器将学习任务分开,而回归者则征服自己的任务。
- 我们的主要贡献如下:开发了一种新的分类引导手姿态回归框架。基于回归的训练数据集,我们训练一个分类器,将复杂和不同的回归学习任务划分为几个更容易的子问题。然后每个回归者只关注一部分训练数据,以使其更专业和准确。分类指导回归方法优于最先进的方法。更广泛地说,其他判别手姿态回归模型可以用作我们框架中的回归模块,并进一步提高姿势估计的准确性。

Methodology

- 我们从单个深度图像
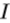 估计其关节的3D位置形式的手姿势
估计其关节的3D位置形式的手姿势 。我们用一个
。我们用一个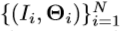 表示训练数据集,其中每个元素都是标有其对应的地面实况关节位置的深度图像。我们提出的方法将手姿势分类器和手姿态回归器集成到一个框架中。事先,回归的训练数据集被聚类成K个子集。并且基于聚类结果,在整个数据集上训练手姿势分类器,但是分别在每个子集上训练若干手姿势回归器。在测试阶段,手姿势分类器首先从深度图像推断出手姿势类k。 然后,对应于k级的手姿势回归量估计最终手姿势
表示训练数据集,其中每个元素都是标有其对应的地面实况关节位置的深度图像。我们提出的方法将手姿势分类器和手姿态回归器集成到一个框架中。事先,回归的训练数据集被聚类成K个子集。并且基于聚类结果,在整个数据集上训练手姿势分类器,但是分别在每个子集上训练若干手姿势回归器。在测试阶段,手姿势分类器首先从深度图像推断出手姿势类k。 然后,对应于k级的手姿势回归量估计最终手姿势 。
。 - 为了训练手姿势分类器,我们利用手姿势回归的现有数据集
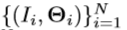 来生成训练数据集
来生成训练数据集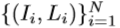 的分类器。因此,我们对手关节的位置矢量
的分类器。因此,我们对手关节的位置矢量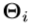 进行聚类,以产生深度图像
进行聚类,以产生深度图像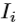 的相应目标标记
的相应目标标记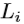 。具有刚性对齐的K-Means聚类算法用于聚类手部姿势。由于
。具有刚性对齐的K-Means聚类算法用于聚类手部姿势。由于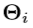 与相机视点有关,因此将刚性配准应用于手部姿势以消除由相机视点引起的影响。严格的注册程序如下:
与相机视点有关,因此将刚性配准应用于手部姿势以消除由相机视点引起的影响。严格的注册程序如下: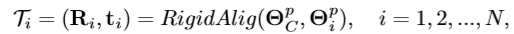
- 其中N是训练集的编号,
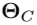 是规范的手姿势,其从
是规范的手姿势,其从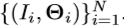 中任意选择。RigidAlig被称为刚性配准,它通过迭代最近点算法[36]实现,该算法用于计算规范手姿势和彼此手姿势的手掌关节之间的刚性变换。
中任意选择。RigidAlig被称为刚性配准,它通过迭代最近点算法[36]实现,该算法用于计算规范手姿势和彼此手姿势的手掌关节之间的刚性变换。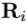 ,
,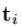 分别代表旋转和平移。刚性变换
分别代表旋转和平移。刚性变换 将训练数据集的每个手姿势
将训练数据集的每个手姿势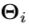 对准到由规范手姿势确定的特定坐标系。然后我们利用K均值聚类将聚集对齐的训练数据
对准到由规范手姿势确定的特定坐标系。然后我们利用K均值聚类将聚集对齐的训练数据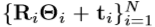 划分为K个类别。因此,深度图像
划分为K个类别。因此,深度图像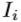 的目标标记
的目标标记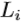 等于其对应的K-Means簇的手姿势
等于其对应的K-Means簇的手姿势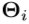 。
。 - 手姿势分类器为每个输入深度图像
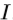 预测手姿势类型
预测手姿势类型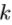 。由于手部姿势登记空间和摄像机视点的变化非常大且复杂,因此基于作为唯一输入信息的深度图像直接对手部姿势进行分类是很困难的。由于卷积神经网络(CNN)在复杂和大规模图像分类任务中的优异性能[37],我们采用CNN方法对手部姿势进行分类。
。由于手部姿势登记空间和摄像机视点的变化非常大且复杂,因此基于作为唯一输入信息的深度图像直接对手部姿势进行分类是很困难的。由于卷积神经网络(CNN)在复杂和大规模图像分类任务中的优异性能[37],我们采用CNN方法对手部姿势进行分类。 - 在本文中,手姿势分类器基于标准的CNN框架。CNN与完全连接的神经网络类似,执行端到端的特征学习,并使用反向传播算法进行训练。但是,它们在许多方面都不同,最显着的是局部连接、权重共享、局部池化。 前两个属性显着减少了自由参数的数量,并且需要在输入的不同位置学习重复的特征检测器。 第三个属性使学习的表示对输入的小变换不变。

- CNN分类器如图3所示。在原始深度图像中,背景像素的比例远大于手像素。因此,我们从原始深度图像中裁剪手区域的边界框,并根据输入数据的要求调整其大小。然后通过五个阶段的卷积和子采样处理输入,这些阶段使用整数线性单位(ReLU)和最大池化。 第一卷积层的卷积内核步长为4,其他为零。五个卷积层的填充分别为0,2,1,1和1。内部池化层有助于降低计算复杂性并提高小输入图像转换的分类容差。不幸的是,池化也会导致空间精度的降低。由于可以通过足够的训练样本学习输入变换的不变性,因此我们只选择步幅为2的三个阶段的池化。
- 在五个卷积和子采样层之后,顶层的池化将被视为一个向量并由三个完全连接的层处理。这些输出级中的每一个都由线性矩阵 - 向量乘法和学习偏差组成,然后是逐点非线性(ReLU)。Dropout [40]用于每个完全连接的线性级的输入,以减少限制大小训练集的过度补偿。在前两个完全连接的层后面有两个漏失率为0.5的丢失层。 输出层具有K-way softmax单元,其产生K个手姿势类的分布。
- 为了估计手姿势
 ,我们采用级联随机回归森林方法,这是[33]中提出的最先进的手姿态估计方法,作为手姿态回归。通过一系列后续随机森林回归量
,我们采用级联随机回归森林方法,这是[33]中提出的最先进的手姿态估计方法,作为手姿态回归。通过一系列后续随机森林回归量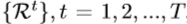 逐步估计最终手姿势
逐步估计最终手姿势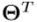 ,其具有姿态索引特征,其取决于来自前一阶段的估计姿势
,其具有姿态索引特征,其取决于来自前一阶段的估计姿势 。为了便于理解,我们将在本节的其余部分简要介绍此方法。
。为了便于理解,我们将在本节的其余部分简要介绍此方法。 - 级联随机回归森林需要深度图像I和初始手势
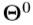 作为输入。在每个阶段
作为输入。在每个阶段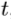 中,它逐渐将当前姿势估计
中,它逐渐将当前姿势估计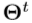 更新为
更新为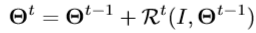 ,上述公式表示在相应的深度图像
,上述公式表示在相应的深度图像 的3D相机坐标系中更新手姿势。当固定3D摄像机视点时,可以使用特定的姿势手模型来生成不同的深度图像,以实现不同的3D刚性变换。在训练阶段,我们计算与3D摄像机坐标系无关的手姿态残差
的3D相机坐标系中更新手姿势。当固定3D摄像机视点时,可以使用特定的姿势手模型来生成不同的深度图像,以实现不同的3D刚性变换。在训练阶段,我们计算与3D摄像机坐标系无关的手姿态残差 。因此,有必要将姿势
。因此,有必要将姿势 与由规范手姿势
与由规范手姿势 确定的规范坐标系对齐。对于给定的手姿势
确定的规范坐标系对齐。对于给定的手姿势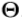 ,我们计算其自身与规范手姿势
,我们计算其自身与规范手姿势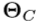 之间的3D刚性变换
之间的3D刚性变换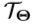 。
。 - 在训练阶段,学习阶段回归
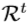 以近似当前姿势残差
以近似当前姿势残差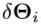 ,其是在所有训练样本
,其是在所有训练样本 上的地面实况姿势与先前姿态估计
上的地面实况姿势与先前姿态估计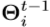 之间的差异。值得注意的是,
之间的差异。值得注意的是,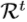 的特征取决于前一阶段的估计姿势
的特征取决于前一阶段的估计姿势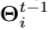 。类似于先前用于图像处理的随机森林方法[1,5,6,8,34],也使用像素差异特征,即两个随机像素的差异。3D姿势索引特征构造如下:
。类似于先前用于图像处理的随机森林方法[1,5,6,8,34],也使用像素差异特征,即两个随机像素的差异。3D姿势索引特征构造如下:
- 在规范坐标系中,随机选择3D球体内的点对
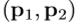 ,其中心是手点云的质心,半径是R,这与实际3D手模型的大小有关。
,其中心是手点云的质心,半径是R,这与实际3D手模型的大小有关。 - 使用反向刚性变换
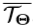 将点对变换为相机坐标系。
将点对变换为相机坐标系。 - 将变换后的点对投影到深度图像上以获得其对应的像素
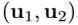 ,然后计算像素差异特征。
,然后计算像素差异特征。
- 姿势索引功能写为
 。
。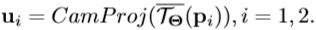 。
。 - 在本文中,我们使用整体回归算法作为我们的手姿态回归量,其在每个阶段回归整个手姿势Θ。对于[33]的层次回归算法,在我们的框架中直接替换整体算法是完全可行的,并且可以进一步提高准确性。虽然我们在框架中使用整体回归算法,但我们的方法也比没有分类步骤的分层回归算法表现更好。整体级联回归的训练算法如算法1所示:

Experiments
- 在本节中,我们评估MSRA手姿态数据集[33]上提出的方法,这是一个真实的基于深度的数据集。 我们首先描述分类器和回归器的实现细节。 然后我们介绍数据集和评估指标,并使用最先进的方法定量和定性地评估所提出的方法。
- CNN分类器在CAFFE [41]框架中实现,这些参数通过使用误差反向传播进行优化。 我们选择衰减参数为0.2,并将批量大小设置为64,动量为0.9,权重衰减为0.0005。 学习率在大约10个时期衰减并以0.005开始,并且网络训练50个时期。 我们选择参数K为17,并且在GPU模式下训练分类器。
- 手姿态回归的初始手姿势Θ0类似于[33]。 每个手姿态回归量由6个级联阶段组成,每个手姿态回归的随机回归森林由10棵树组成。 树样本的每个分割节点540随机特征点对,并且我们选择一个在姿势残差的所有维度上产生最大方差减小的一个。 树节点分裂,直到节点包含少于10个样本。
- 在本文中,我们提出了一种仅基于右手训练数据集的启发式和有效的左右手姿态估计方法。 首先,左右手二进制分类器用于预测手的二进制标签。 除了输出层是双向softmax单元之外,二进制分类器具有与手姿态CNN分类器(在2.3节中)相同的体系结构。 二元分类器的训练数据集是通过移动回归训练数据集的右手图像来构建的,以生成左手深度图像。 在测试阶段,将深度图像I放入二进制分类器中以预测左手或右手。 如果预测的类是左手,则原始深度图像被水平地移动。 这意味着手的点云关于Y OZ平面对称投影:
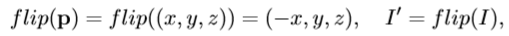 其中
其中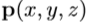 是原点云中的一个点。 然后将伪右深度图像
是原点云中的一个点。 然后将伪右深度图像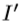 放入右手姿势分类器中以获得预测的手姿势类k。 第k级级随机森林回归器估计右手关节的3D位置
放入右手姿势分类器中以获得预测的手姿势类k。 第k级级随机森林回归器估计右手关节的3D位置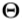 。 最后,我们可以回到左手姿势,即
。 最后,我们可以回到左手姿势,即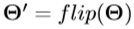 。
。 - 存在一些用于手姿势估计的基于公共真实世界深度的数据集。 然而,数据集[7]的深度图像包括导致可怕的初始化的前臂,其通常在姿势估计中产生大的误差,并且数据集[34]具有受限的视点范围和地面实况手姿势的大注释误差。 数据集[16,17,29]提供的训练数据太少,无法训练有意义的模型。 以上数据集不适合我们的任务。MSRA Hand Pose Dataset [33]是一种用于手姿态估计的大规模且具有挑战性的真实世界基准。 它由76,500个深度图像组成,具有准确的地面真实手势。 从9个对象捕获深度图像,并且每个对象包含17个手势。 该数据集具有较大的视点变化(偏航几乎跨越整个[-90,90]范围并且在[-10,90]度内变化)。 因此,我们选择MSRA Hand Pose Dataset来评估我们提出的方法。
- 虽然MSRA Hand Pose Dataset在[33]中训练手姿态回归器表现良好,但是训练一个表现良好的CNN模型来分类具有大变化范围视点的复杂手部姿势是不够的。 为了避免过度配置并提高分类精度,应用数据增强来改善数据集的多样性。 在MSRA手形姿态数据集中,每个深度图像在+ 10°, - 10°,+ 20°, - 20°,+ 30°, - 30°,+ 40°, - 40°范围内旋转,以生成8个深度图像。 然后,数据集从前一个扩展8次。
- 与之前的工作[33,34]类似,手姿态估计有两个准确度指标。 第一个是所有测试样本中来自地面实况的整个预测关节的平均欧几里德距离,即
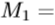
 其中
其中 和
和 分别是预测的关节和地面真实关节。第二个度量是成功率,即所有关节在最大距离阈值ε内的帧的百分比,即
分别是预测的关节和地面真实关节。第二个度量是成功率,即所有关节在最大距离阈值ε内的帧的百分比,即
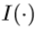 是一个指标函数。很明显,第二个指标比第一个指标更严格。
是一个指标函数。很明显,第二个指标比第一个指标更严格。 - 我们提出的方法通过留一主题交叉验证来评估。 对于左右分类和手势分类器,平均分类精度分别为95.0%和91.2%。

- 为了证明我们的管道效率,我们实现了两个基线。第一个基线直接评估手部姿势,而不使用手部姿势分类器。 我们将此基线称为我们的w / o clasfer。我们提出的方法在平均误差距离和成功率指标方面基本上优于第一个基线。 但是当最大距离阈值ε大于75 mm时,我们的方法的成功率略低于图5(b)中的第一个基线。原因是手姿势分类器预测了不正确的类,因此导致对不正确的回归量的不良估计。
- 众所周知,分类器具有接收器操作特性曲线。 当top-1标签的概率更高时,分类器预测真阳性结果的概率更高。为了解决不正确的预测手姿势类导致估计不良的问题,我们提出了第二个基线,一个具有预测概率判断的分类引导回归流水线,这意味着增加了对手姿势分类器的预测概率的判断,以决定是否信任预测的标签。我们将此基线称为我们的概率判断。 如果预测概率大于给定概率阈值,我们信任预测标签并使用k标签回归量。 否则,我们不信任预测的标签,并使用在整个训练数据集上训练的回归量。
- 在所有的实验中,我们选择=99%作为预测概率的阈值。我们手部姿势分类的平均真阳性率为97.4%。如图5所示,第二基线在大距离阈值ε∈[50,80]上的性能优于我们提出的方法。这是因为我们只信任具有高预测概率的样本,而不强制执行具有低预测概率的分类引导回归方法。
- 我们将我们的管道与MSRA Hand Pose Dataset上最先进的方法[10,33,26]进行比较。 如图6所示,我们的方法完全和基本上比级联分层回归更好。这是因为手姿势分类器将整体复杂和不同的学习任务划分为几个相对容易学习的任务,这些任务适用于随机森林回归。对于协同过滤[10],我们在大多数阈值间隔内实现了出色的精度预测,特别是当距离阈值ε在50 mm以内时。 当距离阈值ε大于55 mm时,我们的方法的性能会比[10]差。 这是因为我们的方法受到由不正确的预测标签引起的不良手姿态估计的影响。与多视图CNN [26]相比,我们的方法在几乎所有距离阈值区间内表现都更好,特别是在最高和最低阈值区间。 我们只需使用整体手姿态回归器来实现最先进的精确性能。 此外,通过在我们的框架中用多视图CNN替换回归量,它将实现比[26]更好的性能。
- 我们还比较了我们提出的方法和图7中的两种方法[26,33]的不同视角的平均误差距离度量。我们提出的方法比所有偏航和俯仰角度的级联分层回归具有更小的平均误差, 并且在大多数偏航视点角度和部分俯仰视角角度上比多视角CNN表现得更好。我们提出的算法在Intel i5 3.3GHz和运行Ubuntu 14.04的NVIDIA GTX980 GPU上进行了测试。 整个手部姿势估计管道在CPU上的单个线程上运行,除了在GPU模式下测试左右分类器和手姿势分类器。 左手分类器和手姿势分类器总共花费7.1毫秒,手姿势估计回归器花费0.7毫秒。 因此,我们的方法的总计算时间约为8毫秒。 如此高的性能足以满足实时应用的需求。 就方法效率而言,所提出的算法比大多数现有方法[5,7,8,10,17,26,29]更快。
Conclusions
- 在本文中,提出了一种分类引导回归学习框架,用于从单个深度图像估计手关节的3D位置。 为了简化具有挑战性的任务,应用训练有素的CNN分类器来识别手势类型。 基于预测的分类器类别,使用准确且高效的级联随机森林回归器来估计最终的手关节位置。 我们的分类器减少了回归的搜索空间并加快了手势估计。 实验表明,所提出的方法在具有挑战性的数据集上实现了最先进的性能。 我们提出的方法是有效的,具有很强的可扩展性,易于将分类器和回归器集成到单个管道中。 更广泛地说,任何判别性手姿势回归模型都可以用作我们框架中的回归模块。 同样,我们的分类器可以用任何类型的高效分类模型代替。
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









