






本文基于version 5.7版本讨论,版本查看
SELECT VERSION();
可按如下两种方式检查你的MySQL服务器是否支持分区。
命令
SHOW PLUGINS;如图:

或者
SELECT
PLUGIN_NAME as Name,
PLUGIN_VERSION as Version,
PLUGIN_STATUS as Status
FROM INFORMATION_SCHEMA.PLUGINS
WHERE PLUGIN_TYPE='STORAGE ENGINE';
如果看到结果中Name有partition,Status值为ACTIVE,说明你的MySQL服务器支持分区。
同一个分区表的所有分区必须使用相同的存储引擎;例如,你不能对一个分区使用MyISAM而对另一个分区使用InnoDB。MySQL分区不能与MERGE、CSV或FEDERATED存储引擎一起使用。分区名称不区分大小写。
RANGE分区
RANGE分区指的是按照某种方式将同属于一个范围的行分到一个分区中,每个分区包含分区表达式值位于给定范围内的行。这些范围应该是连续的,但不能重叠。使用“VALUES LESS THAN”操作符定义的。下面举个例子:
普通建表语句如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
);现在如果我们希望按照store_id的值范围将行进行分区,可以如下建立分区表:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);这样,store_id值满足store_id<6的行将存储到p0分区,store_id值满足6≤store_id<11的行存储到p1分区,等等。注意到每个分区的范围是有顺序的,从小到大。我们调换p0和p1的顺序,如下:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p1 VALUES LESS THAN (11),
PARTITION p0 VALUES LESS THAN (6),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21)
);
分区表会创建失败,如图:

可以将分区范围理解成Java中 if ... elseif ...。创建好分区表后,我们执行如下语句,向分区表中插入一条记录,如下:
insert into employees VALUES(72, 'Mitchell', 'Wilson', '1998-06-25','2021-06-25', 2, 21); 执行结果如下:
我们要写入行的store_id=21,p0到p3分区中并没有一个分区可以存储该行。就是说需要一个分区覆盖store_id≥21的行,可如下使用MAXVALUE创建分区:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT NOT NULL,
store_id INT NOT NULL
)
PARTITION BY RANGE (store_id) (
PARTITION p0 VALUES LESS THAN (6),
PARTITION p1 VALUES LESS THAN (11),
PARTITION p2 VALUES LESS THAN (16),
PARTITION p3 VALUES LESS THAN (21),
PARTITION p4 VALUES LESS THAN MAXVALUE
);这样,store_id≥21的行将全部存储到分区p4中。MAXVALUE表示一个整数值,这个整数值总是大于可能的最大整数值的,在数学中,其实就是最小上确界(a least upper bound)。
注意到,上面用于分区的store_id的类型是INT,也可以在VALUES LESS THAN子句中使用表达式。然而,MySQL必须能够计算表达式的返回值作为LESS THAN(<)比较的一部分。例如,我们可以如下建立分区表:
CREATE TABLE employees (
id INT NOT NULL,
fname VARCHAR(30),
lname VARCHAR(30),
hired DATE NOT NULL DEFAULT '1970-01-01',
separated DATE NOT NULL DEFAULT '9999-12-31',
job_code INT,
store_id INT
)
PARTITION BY RANGE ( YEAR(separated) ) (
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUE
);也可以基于TIMESTAMP类型的列,使用UNIX_TIMESTAMP()函数,例如:
CREATE TABLE quarterly_report_status (
report_id INT NOT NULL,
report_status VARCHAR(20) NOT NULL,
report_updated TIMESTAMP NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP
)
PARTITION BY RANGE ( UNIX_TIMESTAMP(report_updated) ) (
PARTITION p0 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-01-01 00:00:00') ),
PARTITION p1 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-04-01 00:00:00') ),
PARTITION p2 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-07-01 00:00:00') ),
PARTITION p3 VALUES LESS THAN ( UNIX_TIMESTAMP('2008-10-01 00:00:00') ),
PARTITION p4 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-01-01 00:00:00') ),
PARTITION p5 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-04-01 00:00:00') ),
PARTITION p6 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-07-01 00:00:00') ),
PARTITION p7 VALUES LESS THAN ( UNIX_TIMESTAMP('2009-10-01 00:00:00') ),
PARTITION p8 VALUES LESS THAN ( UNIX_TIMESTAMP('2010-01-01 00:00:00') ),
PARTITION p9 VALUES LESS THAN (MAXVALUE)
);
注意其他使用TIMESTAMP类型的函数都是不允许的。
范围分区特别有用,看几个场景:
(1)删除“旧”数据。
ALTER TABLE employees DROP PARTITION p0;可以将分区p0中的行全部删除。
(2)经常运行直接依赖于用于分区表的列的查询。例如:
SELECT COUNT(*) FROM employees WHERE separated BETWEEN '2000-01-01' AND '2000-12-31' GROUP BY store_id;如果我们按照separated创建的分区表(看前面的例子),分区情况如下:
PARTITION p0 VALUES LESS THAN (1991),
PARTITION p1 VALUES LESS THAN (1996),
PARTITION p2 VALUES LESS THAN (2001),
PARTITION p3 VALUES LESS THAN MAXVALUEMySQL可以快速确定只有分区p2需要被扫描,因为剩余的分区不能包含任何满足WHERE子句的记录。可以查看执行计划,如图:

RANGE分区可以在如下类型的列上使用:
(1)整数类型的列,TINYINT, SMALLINT, MEDIUMINT, INT (INTEGER), 和BIGINT,不支持DECIMAL或者 FLOAT;
(2) TIMESTAMP类型的列,使用UNIX_TIMESTAMP()函数返回整数;
(3)DATE, TIME, 或者 DATETIME类型的类,使用YEAR()等函数返回整数;
RANGE COLUMNS分区
RANGE COLUMNS分区和RANGE分区很类似,可以看成是RANGE分区的一个变种。与RANGE分区也有如下不同:
(1)RANGE COLUMNS分区不能使用表达式,只可以是列名称;
(2)RANGE COLUMNS分区可以是一个或者多个列名称;
(3)RANGE COLUMNS分区列不限于整数类型列,字符串(包括CHAR, VARCHAR, BINARY和VARBINARY,不支持TEXT 和 BLOB)、DATE和DATETIME列也可以用作分区列。
创建RANGE COLUMNS分区表的一般语法如下:
CREATE TABLE table_name
PARTITION BY RANGE COLUMNS(column_list) (
PARTITION partition_name VALUES LESS THAN (value_list)[,
PARTITION partition_name VALUES LESS THAN (value_list)][,
...]
);其中中括号[]表示可选,column_list表示列名列表,多个使用逗号隔开,value_list是列值列表,多个使用逗号隔开,如下:
column_list:
column_name[, column_name][, ...]
value_list:
value[, value][, ...]
如果column_list有N个列,对应的value_list有N个值,每个列都要满足VALUES LESS THAN。
例如:
CREATE TABLE rcx (
a INT,
b INT,
c CHAR(3),
d INT
)
PARTITION BY RANGE COLUMNS(a,d,c) (
PARTITION p0 VALUES LESS THAN (5,10,'ggg'),
PARTITION p1 VALUES LESS THAN (10,20,'mmm'),
PARTITION p2 VALUES LESS THAN (15,30,'sss'),
PARTITION p3 VALUES LESS THAN (MAXVALUE,MAXVALUE,MAXVALUE)
);那么数据是如何通过VALUES LESS THAN比较存储到分区中的呢?在RANGE分区中,是通过比较单个值,而在RANGE COLUMNS分区中通过比较元组(多个列的值)来确定行存储到哪个分区中。下面举个例子
CREATE TABLE rc1 (
a INT,
b INT
)
PARTITION BY RANGE COLUMNS(a, b) (
PARTITION p0 VALUES LESS THAN (5, 12),
PARTITION p1 VALUES LESS THAN (MAXVALUE, MAXVALUE)
);INSERT INTO rc1 VALUES (3,10);
可以看到(3,10)存储到p0分区中,
继续写入如下一条数据:
INSERT INTO rc1 VALUES (3,12);
(3,12)存储到p0分区中。
继续写入如下数据:
INSERT INTO rc1 VALUES (5,10); 
(5,10)依然写入到p0分区。
INSERT INTO rc1 VALUES (5,12);
INSERT INTO rc1 VALUES (3,13); 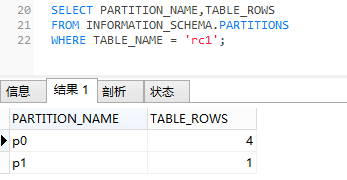
INSERT INTO rc1 VALUES (6,10);
如上我们可以看到行最后存储到哪个分区,可以通过如下方式进行元组比较:
















 228
228











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









