









活动地址:CSDN21天学习挑战赛
上一个章节,跟着老师博文学习lxml模块和Xpath,这一章节,从Python的解析器BeautifulSoup4来做解析。
1 简介和安装
1.1 什么是Beautiful Soup 4
借用官网的解释,Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时甚至数天的工作时间。
官方地址:https://www.crummy.com/software/BeautifulSoup/
官方文档地址(最新版本v4.4.0):https://beautifulsoup.readthedocs.io/zh_CN/v4.4.0/
官方Github地址:https://github.com/DeronW/beautifulsoup
在官方文档中出现的例子在Python2.7和Python3.2中的执行结果相同。寻找 Beautiful Soup3 的文档,Beautiful Soup 3 目前已经停止开发,我们推荐在现在的项目中使用Beautiful Soup 4。
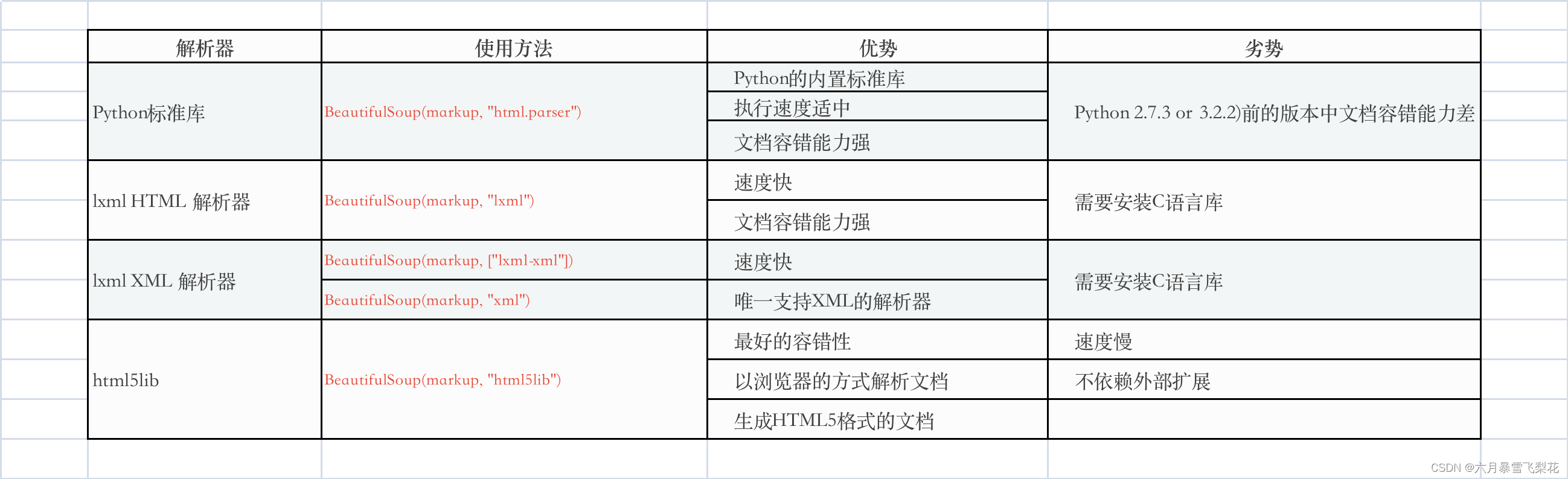
上一个章节,已经安装了lxml,这个也是最常用的解析器,除了这个还有纯Python实现的 html5lib解析库。
各个解析器的优缺点:
1.2 安装 Beautiful Soup
- Debain或ubuntu系统
$ apt-get install Python-bs4
Beautiful Soup 4 通过PyPi发布,所以如果你无法使用系统包管理安装,那么也可以通过 easy_install 或 pip 来安装.包的名字是 beautifulsoup4 ,这个包兼容Python2和Python3。
如果不能使用apt-get获取安装,则可以使用pip或easy_install安装
$ easy_install beautifulsoup4
$ pip install beautifulsoup4
注意:如果是使用了beautifulsoup,而不是beautifulsoup4,那么可能安装了beautifulsoup3,而不是beautifulsoup4这个版本。所以,在安装时,一定要选择合适的版本。
我们同样在自己机器打开终端,输入安装命令,这个安装比较快,比起昨日学习的lxml以及xpath,速度快了很多。如下:
Aion.Liu $ python -m pip install beautifulsoup4
Collecting beautifulsoup4
Downloading beautifulsoup4-4.11.1-py3-none-any.whl (128 kB)
━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━━ 128.2/128.2 kB 122.6 kB/s eta 0:00:00
Collecting soupsieve>1.2
Downloading soupsieve-2.3.2.post1-py3-none-any.whl (37 kB)
Installing collected packages: soupsieve, beautifulsoup4
Successfully installed beautifulsoup4-4.11.1 soupsieve-2.3.2.post1
1.3 使用过程中可能出现的问题
Beautiful Soup发布时打包成Python2版本的代码,在Python3环境下安装时,会自动转换成Python3的代码,如果没有一个安装的过程,那么代码就不会被转换。
1、ImportError 的异常: “No module named HTMLParser”
问题定位:在Python3版本中执行Python2版本的代码。
2、ImportError 的异常: “No module named html.parser”
问题定位:在Python2版本中执行Python3版本的代码。
3、上述两种情况都在
重新安装库。
2 实验和操作
2.1 简单实例
首先,我们需要创建一个实验文档文件c18.html,然后在里面输入内容<html>data<html>。这样子,我们简单创建了一个网页文件。
然后我们使用bs4来解析文件和字符串。
>>> from bs4 import BeautifulSoup
>>> soup_html = BeautifulSoup(open("c18.html"))
>>> soup_string = BeautifulSoup("<html>data2</html>")
>>>
>>> print(soup_html)
<html><body><p>data</p></body></html>
>>>
>>> print(soup_string)
<html><body><p>data2</p></body></html>
2.2 bs4的对象种类
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
Tag,NavigableString,BeautifulSoup,Comment。其中,前三个几乎覆盖了html和xml中的所有内容,但是还有一些特殊对象,需要使用Comment。
2.3 bs4的对象|Tag
Tag 对象与XML或HTML原生文档中的tag(标签)相同。举例说明:
>>> tag_html = soup_string.html
>>> print(type(tag_html))
<class 'bs4.element.Tag'>
>>>
>>> print(tag_html)
<html><body><p>data2</p></body></html>
Tag有很多方法和属性,现在介绍一下tag中最重要的属性: name和attributes。一个tag可能有很多个属性,这个也符合我们通常使用的HTML。
>>> soup_string2 = BeautifulSoup("<html><div class='.user-name'><span>XiaoMing</span></div></html>")
>>> tag = soup_string2.div
>>> print(tag.name)
div
>>> print(tag['class'])
['.user-name']
>>>
>>> print(tag.attrs)
{'class': ['.user-name']}
>>>
tag支持添加、修改和删除。比如,现在我想给div增加一个属性id,值为user-div,那么可以这样子操作:
>>> # 新增
>>> tag['id'] = 'user-div'
>>> print(tag)
<div class=".user-name" id="user-div"><span>XiaoMing</span></div>
>>> # 删除
>>> del tag['class']
>>> print(tag)
<div id="user-div"><span>XiaoMing</span></div>
>>> # 修改
>>> tag['class'] = ''
>>> print(tag)
<div class="" id="user-div"><span>XiaoMing</span></div>
>>> tag['class']='user-first-name'
>>> print(tag)
<div class="user-first-name" id="user-div"><span>XiaoMing</span></div>
>>>
当然,在实际的使用过程中,class的属性值可能会有多个,这里我们可以解析为list。随意找一个网页,我们都可以发现
>>> soup_string3 = BeautifulSoup("<html><div class='body user-name'><span>XiaoMing</span></div></html>")
>>> tag = soup_string3.div
>>>
>>> print(tag['class'])
['body', 'user-name']
当然,也可以针对这个属性进行list列表方式新增(本义上是覆盖原来的属性)。
>>> tag['class'] = ['body', 'table', 'tr', 'td']
>>> print(tag)
<div class="body table tr td"><span>XiaoMing</span></div>
>>>
2.3 bs4的对象|NavigableString
主要是用来获取标签对象内的文本,或替换文本。下面获取div的文本内容,然后看下这个类型。注意,这里获取内容后,会忽略span这个标签。
>>> print(tag.string)
XiaoMing
>>> print(type(tag.string))
<class 'bs4.element.NavigableString'>
>>>
一个 NavigableString 字符串与Python中的Unicode字符串相同,并且还支持包含在 遍历文档树 和 搜索文档树 中的一些特性。通过 unicode() 方法可以直接将 NavigableString 对象转换成Unicode字符串:
NavigableString 对象支持 遍历文档树 和 搜索文档树 中定义的大部分属性,并非全部.尤其是,一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
2.4 bs4的对象|BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容,大部分时候,可以把它当作 Tag 对象,它支持 遍历文档树 和 搜索文档树 中描述的大部分的方法。
因为 BeautifulSoup 对象并不是真正的HTML或XML的tag,所以它没有name和attribute属性。但有时查看它的 .name 属性是很方便的,所以 BeautifulSoup 对象包含了一个值为 “[document]” 的特殊属性 .name。
>>>
>>> print(soup_string3.name)
[document]
>>>
2.5 bs4的对象|Comment
Comment 对象是一个特殊类型的 NavigableString 对象。
3 遍历文档树和搜索文档树
这个,暂时学习到这里吧。下一个章节再来学习补充。
















 2093
2093











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











