









Pandas是多数数据处理的首选库,它能使数据清洗和分析工作变得高效快捷。pandas经常和其它工具一同使用,如数值计算工具NumPy 和SciPy,分析库statsmodels和scikit-learn,和数据可视化库matplotlib。pandas是基于NumPy数组构建的,特别是基于数组的函数和不使用for循环的数据处理。
导入Pandas模块:
一.应用DataFrame创建数据
DataFrame是一个表格型的数据结构,它含有一组有序的列,每列可以是不同的值 类型(数值、字符串、布尔值等)。DataFrame既有行索引也有列索引,它可以被 看做由Series组成的字典(共用同一个索引)。DataFrame中的数据是以一个或多个二维块存放的(而不是列表、字典或别的一维数据结构)。
导入pandas模块和查看版本:
import pandas as pd
pd.__version__结果:
![]()
自己在数据分析的过程中,构建dataframe:
"""创建DataFrame数据:最常用的一种是直接传入一个由等长列表或NumPy数 组组成的字典"""
data = {'name':['zhangsan','lisi','wangwu','hanhan','huahua'],
'gender':['男','男','男','女','男'],
'yearsOld':['13','15','19','25','18']}
dataframe = pd.DataFrame(data)
#df.head()函数默认显示前5行
dataframe.head()结果:

如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
#如果指定了列序列,则DataFrame的列就会按照指定顺序进行排列:
df_01 = pd.DataFrame(data,columns=['gender','name','yearsOld'])
df_01.head()结果:

指定列名称和行标题,指定显示前三列
#指定列名称和行标题,指定显示前三列
df_02 = pd.DataFrame(data,columns=['gender','name','yearsOld'],index=['one','two','three','four','five'])
df_02.head(3)结果:

选取一列转化为列表,以下有3种思路:
#选取一列转化为列表,以下有3种思路
a = df_02.name.to_list()
b = df_02['name'].to_list()
c = [i[1] for i in df_02.values]
print('a',a)
print('b',b)
print('c',c)结果:

dataframe添加新的一列,并赋值:
#dataframe添加新的一列。并赋值
df_02['weight'] = '100kg'
df_02.head(5)结果:

二. dataframe数据选取
基本和numpy相同,但是要注意.iloc和loc、iat和at的区别,iloc中括号里面填写数字表示位置,如[0,0]表示第1行的第1列,loc中括号里面要填写具体的列名称和行名称,如['one','name']表示‘one’行和‘name’列,at同loc,iat同iloc:
#dataframe切片,选取‘weight’列
df_02['weight']结果:
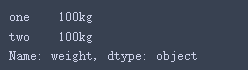
选取第一行
df_02.iloc[0,:]结果:
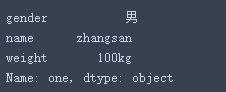
选取第一行,第一个元素:
df_02.iloc[0,0]结果:
![]()
返回第⼀⾏,即“one”行(索引为默认的数字时,⽤法同df.iloc)
df_02.loc['one',:]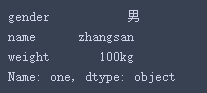
df_02.loc['one','name']结果:
![]()
选择索引排序为3,字段排序为0的数据:
df_02.iat[3,0]结果:
![]()
del删除一列:
#del删除一列
del df_02['yearsOld']
#查看列名称
df_02.columns结果:
![]()
三.dataframe外部导入数据
导入excel数据表,在当前文件夹下,相对路径即可,也可以是绝对路径
#导入excel数据表,在当前文件夹下,相对路径即可,也可以是绝对路径
df_11 = pd.read_excel('drug_use.xlsx')
df_11.head(2)结果:

查看⾏数和列数:
df_11.shape ![]()
查看DataFrame对象的最后n行:
df_11.tail(2) 
查看数值型列的汇总统计,这个一般做计数统计,不适用与nlp处理
df_11.describe()
查看是否有缺失值
df_11.isnull().any() 
查看column_name字段数据重复的个数
df_11[df_11['entityId'].duplicated()] .count()
导入其他格式的数据,CSV、txt、sql、json等格式数据方式:
#同理,从CSV⽂件导⼊数据,示例是导入该目录data文件下的该文件
df_12 = pd.read_csv('.data/niupi.csv')
#导入txt
df_13 = pd.read_csv('.data/niupi.txt',engine='python',encoding='utf-8')
# 从SQL表/库导⼊数据
df_15 = pd.read_sql(query,connection_object)
# 从JSON格式的字符串导⼊数据
df_16 = df.to_json(filename)四.存储数据
导出数据到CSV⽂件
df.to_csv(filename)
导出数据到Excel⽂件
df.to_excel(filename)导出数据到SQL表
df.to_sql(table_name,connection_object)以Json格式导出数据到⽂本⽂件
df.to_json(filename)五.数据处理和数据合并
df.drop_duplicates #去除重复数据
df.columns= ['a','b','c'] # 重命名列名(需要将所有列名列出,否则会报错)
pd.isnull() # 检查DataFrame对象中的空值,并返回⼀个Boolean数组
pd.notnull() # 检查DataFrame对象中的⾮空值,并返回⼀个Boolean数组
df.dropna() # 删除所有包含空值的⾏
df.dropna(axis=1) # 删除所有包含空值的列
df.dropna(axis=1,thresh=n) # 删除所有⼩于n个⾮空值的⾏
df.fillna(value=x) # ⽤x替换DataFrame对象中所有的空值,⽀持
df[column_name].fillna(x)
df.rename(columns=lambdax:x+1) # 批量更改列名
df.rename(columns={'old_name':'new_ name'}) # 选择性更改列名
df.set_index('column_one') # 将某个字段设为索引,可接受列表参数,即设置多个索引
df.reset_index("col1") # 将索引设置为col1字段,并将索引新设置为0,1,2...
df.rename(index=lambdax:x+1) # 批量重命名索引
df.sort_index().loc[:5] # 对前5条数据进⾏索引排序
df.sort_values(col1) # 按照列col1排序数据,默认升序排列
df.sort_values(col2,ascending=False) # 按照列col1降序排列数据
df.sort_values([col1,col2],ascending=[True,False]) # 先按列col1升序排列,后按col2降序排列数据
df.groupby(col) # 返回⼀个按列col进⾏分组的Groupby对象
df.groupby([col1,col2]) # 返回⼀个按多列进⾏分组的Groupby对象
df.groupby(col1)[col2].agg(mean) # 返回按列col1进⾏分组后,列col2的均值,agg可以接受列表参数,agg([len,np.mean])
df.pivot_table(index=col1,values=[col2,col3],aggfunc={col2:max,col3:[ma,min]}) # 创建⼀个按列col1进⾏分组,计算col2的最⼤值和col3的最⼤值、最⼩值的数据透视表
df.groupby(col1).agg(np.mean) # 返回按列col1分组的所有列的均值,⽀持
df.groupby(col1).col2.agg(['min','max'])
data.apply(np.mean) # 对DataFrame中的每⼀列应⽤函数np.mean
data.apply(np.max,axis=1) # 对DataFrame中的每⼀⾏应⽤函数np.max
df.groupby(col1).col2.transform("sum") # 通常与groupby连⽤,避免索引更改
df1.append(df2) # 将df2中的⾏添加到df1的尾部
df.concat([df1,df2],axis=1,join='inner') # 将df2中的列添加到df1的尾部,值为空的对应⾏与对应列都不要
df1.join(df2.set_index(col1),on=col1,how='inner') # 对df1的列和df2的列执⾏SQL形式的join,默认按照索引来进⾏合并,如果df1和df2有共同字段时,会报错,可通过设置lsuffix,rsuffix来进⾏解决,如果需要按照共同列进⾏合并,就要⽤到set_index(col1)
pd.merge(df1,df2,on='col1',how='outer') # 对df1和df2合并,按照col1,⽅式为outer
pd.merge(df1,df2,left_index=True,right_index=True,how='outer') #与 df1.join(df2, how='outer')效果相同
敲黑板:pandas是数据处理的基础,在机器学习和深度学习领域,其往往和numpy模块合并使用,常用的功能我们记住即可,其他功能我们我可边用边查。
常用功能:1.读取和保存excel,txt,csv文件;
2.创建dataframe,并利用索引选取数据,并转化为列表字典等相应格式;
3.去除重复数据、空值,group分组,merge、concat合并等;
应用示例:nlp常用功能,excel两列数据转化为字典,转化为“GROUP_CODE”为key,“GROUP_ICD_NAME”为value的字典:
import pandas as pd
df_01 = pd.read_excel('03-GX_GROUP_PACKAGE.xlsx')
df_01.head(2)
dic = {}
for i in df_01.values:
try:
dic[i[5]].append(i[3])
except:
dic[i[5]] = [i[3]]
查看一下结果:
dic
















 949
949











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











