









记录以前发现一个很有意思的事情,当用pandas 读取excel或者其他类型的数据时,发现表里面原来有空值的地方用nan来补充了:
import pandas as pd
df = pd.read_excel('example_nan.xlsx')
df.head()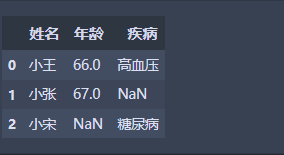
我把它们都装进列表里是这样的格式:
lis = []
for i in df.values:
lis.append([i[0],i[1],i[2]])
print(lis)
很多时候,我们都需要对里面的nan值判断,那么问题来了,它是什么类型的数据呢?打印一些类型看一看:
print(lis[1][2])
print(type(lis[1][2]))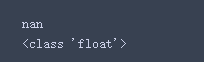
没错!他就是float(浮点)类型的格式,那么判断方法一:
if type(lis[1][2]) == float:
print('yes')![]()
判断方法二:
if lis[1][2] != lis[1][2]:
print('yes') ![]()
总结,在处理文本数据时,判断nan是非常重要的,因为文本数据都是str,而nan是float,所以一定要记住哦~~~
















 1274
1274











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











