







鲁棒的无监督StyleGAN图像恢复
一.创新点
现有的无监督方法必须针对每个任务和降级级别进行仔细调整。(这里每个任务都是什么?降级级别是什么?)
在这里使用StyleGAN图像恢复健壮,即单组超参数在宽范围的退化水平上起作用。(是不是说之前需要多组参数处理不同任务,现在只要一组超参数可以处理多个任务)
这样就可以处理几种退化的组合,而不需要重新调整
本论文的方法赖于一个3阶段渐进的潜在空间扩展和一个保守的优化器,这避免了需要任何额外的正则化条款。(3阶段渐进的潜在空间扩展和一个保守的优化器是什么?额外的正则化条款又是什么?)
大量的实验表明,在不同的退化水平下,修复,上采样,去噪和去伪影的鲁棒性,优于其他基于StyleGAN的反演技术。(是不是意味着也有其他基于StyleGAN的图像恢复技术,但我们的方法鲁棒性更强?)
我们的方法相比于,基于扩散的恢复有更好的恢复结果。(这种基于扩散的恢复是什么?)
二.详细说明本论文的背景
很多图像恢复任务是不同的,例如降噪,上采样,取出伪影等。现有的方法大多是针对不同任务专门设计数据集,在监督学习中解决。但这样就需要在每个任务上重新训练大型网络。(不同的任务都有专门的网络去解决,那这样遇到一个图片如果同时遭遇不同退化,那是不是就要几种大网络组合起来去恢复)
生成模型出现后,产生了很多无监督的图像恢复方法,不需要对特定任务进行训练,他利用反转生成过程以恢复干净的图像
假设已知(或近似)退化模型,优化过程因此尝试恢复既有以下两种情况的图像:1)在经历类似的退化模型(保真度)之后紧密匹配目标退化图像; 2)存在于由GAN学习到的真实图像空间中(realistic)。
StyleGAN [29-31]被发现对于无监督图像恢复特别有效,因为其潜在空间的优雅设计。事实上,这些方法利用风格反转技术来求解潜在向量,当将其提供给生成器时,创建接近退化目标的图像。不幸的是,只有当模型分布中实际存在这样的匹配时,这才有效,而实际上很少出现这种情况。(这里的潜在向量是什么?意思是不是说利用StyleGAN进行图像恢复时,把需要恢复的图像给StyleGAN,只有当StyleGAN模型中存在这样的恢复前与恢复后图像匹配,才能完成图像恢复过程?)
因此,有效的方法将学习到的潜在空间扩展到增加额外的自由度去容纳更多图像,这产生了对附加正则化损失的需要。因此,必须针对每个特定任务和降级级别仔细调整超参数。(是不是意味着要容纳更多的匹配,需要对每个任务进行调整)
这产生了对附加正则化损失的需要。因此,必须针对每个特定任务和降级级别仔细调整超参数。
在这项工作中,我们使无监督的StyleGAN图像反演恢复对退化的类型和强度具有鲁棒性。我们提出的方法在所有任务和级别上使用相同的超参数,并且不依赖于任何正则化损失。我们的方法依赖于两个关键思想。(成功引出本论文的特点)
三.本方法的关键思想
首先,我们依靠3阶段渐进式潜在空间扩展:
- 我们通过在学习的(全局)潜在空间上进行优化开始
- 然后在生成器的各个层上扩展它
- 并且最后在各个滤波器上进一步扩展它-其中每个阶段的优化利用前一阶段的结果来初始化。
其次,我们依赖于保守的归一化梯度下降(NGD)优化器
- 与Adam 等更复杂的方法相比,该优化器自然被限制在接近其初始点
- 在逐渐丰富的潜在空间上的谨慎优化的这种组合完全避免了额外的正则化项
- 并且在所有任务中保持整个过程简单且恒定
我们评估了我们的方法上采样,修复,去噪和deartifacting在广泛的退化水平,其结果达到了SOTA方法的结果,即使在每个独立的优化器上;并且在这些任务的组合上我们是优于其他任务的,因为我们不改变超参数。
四.贡献
-
我们提出了一个强大的3阶段StyleGAN图像恢复框架。我们的优化技术保持:1)当退化水平高时,具有强的真实感;2)当它们低时高保真度。我们的方法是完全无监督的,不需要每个任务的训练,并且可以处理不同级别的不同任务,而无需调整超参数。
-
我们证明了所提出的方法的有效性,根据不同的和组成的退化。我们开发了一个基准的合成图像恢复任务,使他们的退化水平易于控制,小心,以避免不切实际的假设。我们的方法优于现有的无监督[13,40]和基于扩散的[32]方法
(StyleGAN反演取得了很大进展:反转生成过程以推断生成给定图像的潜在参数)
这些方法通过添加额外的参数来对其进行优化来扩展预训练的StyleGAN模型(通常称为W)的学习潜在空间。最常见的方法是为每个层使用不同的潜在代码[3](称为W+)。在[46]中也探索了超越W+,其建议微调生成器参数,并且[44]对于每个卷积滤波器使用不同的潜在代码。我们建立在这些技术的基础上,通过开发一种专门设计用于强大的图像恢复的反演方法。(待总结)
我们的方法不同之处在于,它解决了鲁棒性和组合性。
五.本方法内容
通过避免任何正则化损失,实现了鲁棒性。
其他基于StyleGAN的图像恢复方法仅用于特定情况(例如恢复旧照片),这些方法要想恢复各种退化的组合,则需要对每种退化都使用特定任务的编码器,而我们的方法完全无监督,适用于各种图像域。
去噪扩散恢复模型(DDRM)[32]表明,预训练的DDPM可以用于无监督恢复任务,但仅限于具有加性高斯噪声的线性逆问题。相比之下,我们的方法更灵活,因为它只需要退化函数的可微近似,这可以是非线性的。
5.1原本的StyleGAN图像恢复方法
StyleGAN反演尝试恢复最佳匹配(未知)地面实况图像yclean的图像xclean。为此,我们的目标是搜索潜在码w ∈ W,使得xclean = G(w)在某个图像距离函数下最佳匹配yclean。所产生的最小化问题,
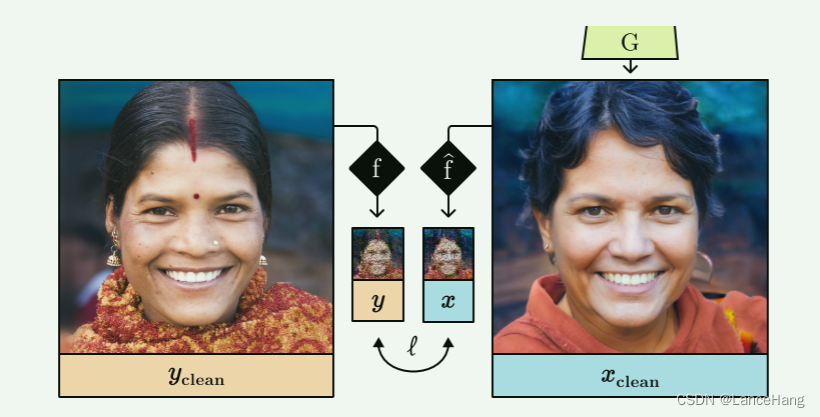
使用StyleGAN的无监督图像恢复尝试通过找到与此目标匹配的生成图像xclean来恢复退化的目标图像y = f(yclean),该生成图像xclean曾经也退化了x = f(xclean)(sec.这里,f是退化函数f的可微近似,yclean是(未知的)地面实况图像。(可理解为:要恢复的图像为y,y恢复后的图像为yclean,但我们没有yclean,却能利用StyleGAN去找到与yclean匹配的生成图像xclean,这个xclean是通过搜索潜在码w得到,在某个图像距离函数下xclean与yclean最接近。且xclean曾经退化为x,这个x=f^(xclean),这样就能通过某种关系找到y)
因此可以看出该方法的目标是找到w,
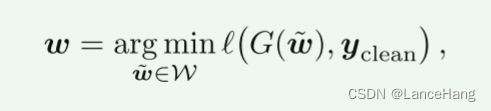
在图像恢复中,地面实况图像yclean是未知的:而是给出目标图像y = f(yclean),即(非单射的、潜在不可微的)退化函数f的结果。假设可以构造一个可微近似f ≈ f,则通过求解
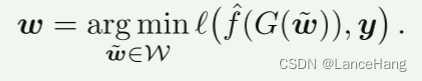
这样思想就可以推广到多种退化的组合,去求解(一种f^就是一种退化函数)

这里,假设每个子函数fi具有可微近似Φ fi^,并且合成的阶数是已知的。(即退化的程度是知道的)
从本方法可以看出,结果是很好的,但保真度较低(不容易找到匹配的退化目标。)
保真度最常见的改进方法是:1)执行潜在扩展[3],即求解具有更多自由度的w+ ∈ W+; 2)使用像Adam [33]这样性能更好的优化器。这些技术既提高了保真度,又破坏了现实主义,激发了正则化损失的使用,必须针对不同的任务仔细调整
5.2鲁棒的StyleGAN恢复
重新审视无监督StyleGAN优化流水线的每一部分,即潜在扩展、优化器和损失函数。
5.2.1潜在扩展
受初始化是最佳正则化[46]的直觉启发,我们提出了一个三阶段的潜在扩展,其中每个阶段由前一个阶段的结果初始化
见图3。3.给定生成器中具有NL层的预训练StyleGAN2 [31]模型,我们表示用于调制卷积权重θl ∈ R512×512的层l ∈ [1,NL]处的样式向量sl i ∈ R512。假设1 × 1滤波器以简化符号1,每个特征图像素pl ∈ R512由下式处理:
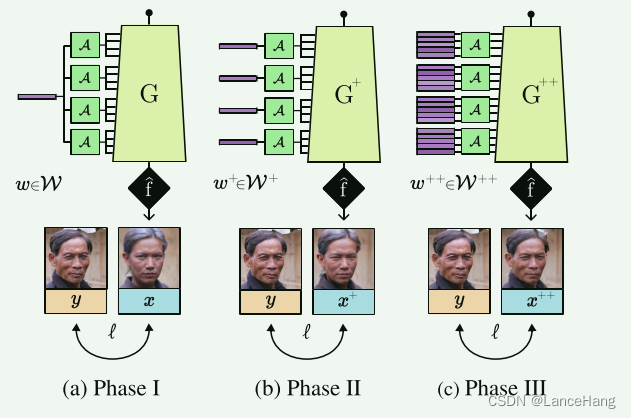
(a)阶段I使用全局潜在码w,导致预测X。(b)阶段II执行逐层潜在扩展,得到矩阵w+和预测x+。©阶段III执行逐滤波器的潜在扩展,得到张量w++和最终预测x++。

(即共有NL层,第l+1层的第i个像素的输出特征为:上一层对应像素的卷积权重和样式向量组合,乘以上一层的输出特征)(这个i到底是什???)
第一阶段
执行全局样式调制(图1A)。3-(a)),并求解跨所有层共享的单个潜在向量w ∈ W = R512,如等式3-(a)中所示。(三)、在优化之前,w被初始化为训练集上的W的平均值,即,E ~ w∈W[~ w]。这里,样式调制矢量sli是可以写成
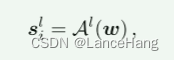
Al是对应的仿射投影层(其乘以权重矩阵并添加偏置)。
图1A

第二阶段
执行逐层潜在扩展,并求解潜在矩阵w+ ∈ W+ = R^(NL×512)。w+的每一行都被初始化为w。这个阶段的风格调制成为
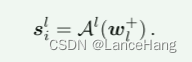
第三阶段
执行滤波器方式的潜在扩展,并且求解潜在张量w++ ∈ W++ = R^(NF×NL×512),其中不同的潜在码用于每个卷积滤波器,并且其中NF是这样的滤波器的数量。w++的每个子矩阵被初始化为w+。这个阶段的风格调制成为
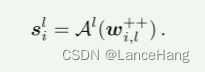
(总结:所以潜在扩展就是优化找合适的潜在码w,这里分为三个阶段,第一阶段针对全局,找到适用所有退化的单个潜在向量w;第二阶段逐层潜在扩展,找到潜在矩阵w+;第三阶段滤波器方式的潜在扩展,找到潜在张量w++)
疑问:w+把每一行都初始化为w,这里每一行代表什么?既然已经初始化了w,那么是通过什么方法计算之后的w+呢?第三阶段为什么要加入滤波器?
5.2.2优化器
没有用多数方法用到的Adam找w,而是用较弱的归一化梯度下降NGD,这是SGD的一个简单变体,在每一步之前对梯度进行归一化:
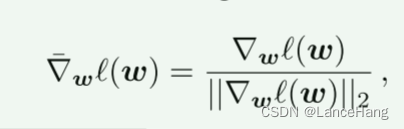
在潜在扩展之后,我们分别归一化每个潜在代码(即,W+和W++的每一行)。NGD保持损失规模不变性,这是Adam的一个关键属性,它避免了损失函数变化后的学习率调整。
5.2.3损失函数
staple损失函数是LPIPS [63]感知损失与L2或L1 [4]像素损失的组合。由于更多分辨率损失函数更有鲁棒性,可用于:
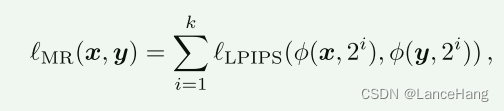
φ(x,2^i)使用平均池化以 2i的因子下采样,并且我们针对1024×1024的图像分辨率设置k = 6。所有分辨率的权重相等,给出最终的损失函数,其中λL1 = 0.1

5.3该方法的伪码

G+和G++分别表示修改为接受w+ ∈ W+和w++ ∈ W++后的合成网络G。学习率和步骤数等超参数被明确提供,因为它们在所有任务中保持不变。
六、基准恢复鲁棒性
本节首先描述了在所有实验中使用的所提出的退化模型以及它们的可微分逼近,并解释了他们如何组合在一起。
6.1单个的退化
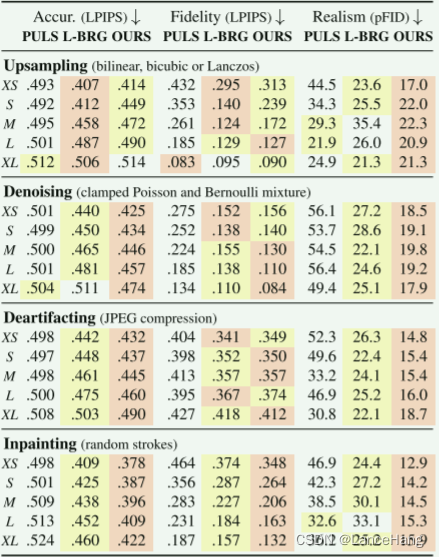
对常见的四种图像退化源进行实验:上采样、修复、去噪和去伪像。合成模型用于促进在不同退化水平下的比较。在五个水平下测试每种退化,其被称为超小(XS)、小(S)、中等(M)、大(L)和超大(XL)。下面将以相同的顺序为每个任务提供每个退化级别的参数。图4示出了在XS和XL水平处的所有四个降级的示例,

6.1.1上采样
整数因子kdown ∈ {2,4,8,16,32}对地面实况图像yclean进行下采样来产生目标y
下采样滤波器是从常用的双线性、双三次和Lanczos滤波器均匀采样的,这提供了粗略但宽范围的混叠轮廓
(问题:这三个滤波器具体是怎样的?)
6.1.2修复
预测图像中缺失的区域。
通过绘制宽度为0.08r的kstroke ∈ {1,5,9,13,17}随机笔划来生成随机掩码,其中r是图像分辨率,每个笔划连接位于图像的外三分之一中的两个随机点。
6.1.3去噪
通过使用泊松噪声和伯努利噪声的混合来生成目标,分别模拟相机中的常见噪声源,即散粒噪声和死(或热)像素。
因为与高斯噪声不同,泊松噪声是非加性的和信号相关的,而伯努利噪声是有偏置的。此外,两者都是不可微的。
使用参数kp ∈ {96,48,24,12,6}和kb ∈ {0.04,0.08,0.16,0.32,0.64},其中kp给出根据泊松分布添加到像素(独立于每个通道)的最可能值,kb是像素的所有通道被黑色替换的概率。
整体噪声模型:
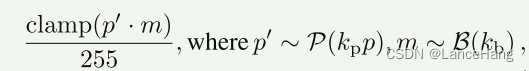
对于地面实况图像像素值p ∈ [0.0,1.0],并且其中clamp(·)使[0,255]之外的所有值饱和。注意,p′只能取离散值。
对于可微近似f^,我们用高斯可逼近代替(不可微的,离散的)泊松噪声。并将伯努利噪声视为未知掩码
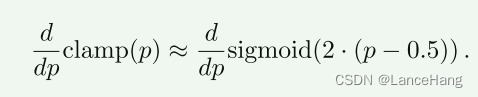
6.1.4去伪像
伪像:图像上不该出现的要素
在质量水平kjpeg ∈ {18,15,12,9,6}下对用libjpeg [2,12]压缩的JPEG图像执行去噪。
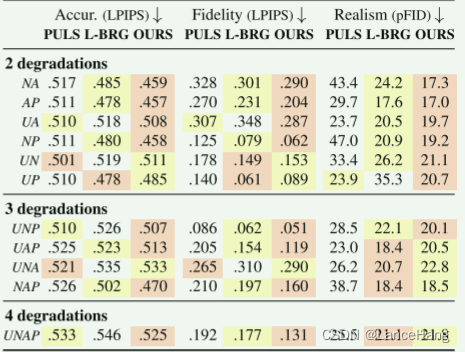
6.2组合的退化
在求w时,假设知道退化的顺序
这里图像恢复过程为
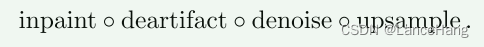
任务组合是用这种顺序(的子序列)创建的。例如,上采样和去伪像形成长度为2的合成。所有组合物均在退化水平培养基(M)下用任务形成。
七.结果
7.1 与其他基于StyleGAN模型相比
退化水平的鲁棒性
学习感知图像块相似度LPIPS越低,表示图像的相似度越好
组合的鲁棒性
其中U为上采样、N为去噪、A为去伪像、P为修复

7.2与扩散模型相比

八.总结
本文提出了一种方法,该方法使基于StyleGAN的图像恢复对退化水平的变化和不同退化的组成都具有鲁棒性。我们提出的方法依赖于一个保守的优化过程,逐步丰富的潜在空间,并完全避免正则化条款。使用一组超参数,我们获得了竞争力,甚至国家的最先进的结果,在几个具有挑战性的情况下相比,为每个任务/水平单独优化的基线。















 711
711











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









