









目录:
第一章 深度学习概述
第二章 无监督学习GAN
第三章 图像风格跨域转换
第四章 从文本构建逼真的图像
第五章 利用多种生成模型生成图像
第六章 将机器学习带入生产环境
2 无监督学习GAN
2.1.1 GAN的目的(学习生成模型的理由)
- 生成样本;
- 训练并不包含最大似然估计;
- 由于生成器看不到训练数据,过拟合风险更低;
- GAN十分擅长捕获模式的分布。
2.1.2 现实世界的一个比喻
极大极小博弈,对抗性过程(Adversarial Process)
2.1.3 GAN的组成
GAN十分擅长无监督学习和生成数据,其还有强大的表达能力:它可以在潜在空间(向量空间)内执行算数运算,并将其转化为对应特征空间内的运算。

下面我们来简单介绍一下生成式对抗网络,主要介绍三篇论文:
- 1)Generative Adversarial Networks;

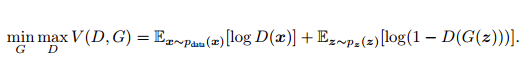

- 2)Conditional Generative Adversarial Nets
第二篇文章想法很简单,就是给 GAN 加上条件,让生成的样本符合我们的预期,这个条件可以是类别标签(例如 MNIST 手写数据集的类别标签),也可以是其他的多模态信息(例如对图像的描述语言)等。用公式表示就是:
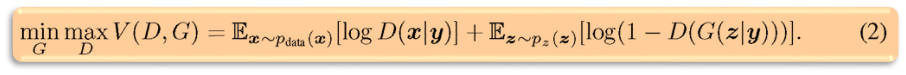


- 3)Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks;
第三篇文章,简称(DCGAN),在实际中是代码使用率最高的一篇文章,本系列文的代码也是这篇文章代码的初级版本,它优化了网络结构,加入了 conv,batch_norm 等层,使得网络更容易训练,网络结构如下:

2.2.1 GAN的应用
- CycleGAN进行图像转换(斑马/马);
- 利用条件GAN进行图像编辑;
- 利用StackGAN自动从文本中制作逼真的图像;
- 利用探索式GAN(Discovery GAN, DiscoGAN)进行图像风格转换;
- 利用SRGAN通过预训练模型提升图像品质,制作高分辨率的图像;
- 通过特征生成逼真图像:arXiv:1605.05396, 2016
- 预测下一帧视频或者动态生成视频:http://carlvondrick.com/tinyvideo/
2.2.2 在Keras上利用DCGAN实现图像生成
Deep Convolution Generative Adversarial Network, DCGAN:arXiv:1511.06434
https://github.com/jacobgil/keras-dcgan
- 在判别器中使用步数卷积代替池化层,在生成器中使用小数步数卷积代替池化层;
- 在生成器和判别器中均使用批规范化;
- 消除架构中较深的全连接隐藏层,并且在最后只使用简单的平均值池化;
- 在生成器的输出层使用Tanh,在其他层使用ReLU;
- 在判别器的所用层中使用Leaky ReLU;
2.2.3 利用TensorFlow实现SSGAN
半监督学习生成对抗网络(Semi-Supervised Learning Generative Adverarial Network, SSGAN)最初的动机是利用生成器生成样本的能力来提高图像分类任务的性能,提高判别器的范化能力,其关键思想是将其中一个网络同时当作分类器和判别器进行训练。
https://github.com/gitlimlab/SSGAN-Tensorflow
The loss of this multi-task learning framework can be decomposed into the supervised loss
,
and the GAN loss of a discriminator
,
During the training phase, we jointly minimize the total loss obtained by simply combining the two losses together.

2.3 GAN模型的挑战
2.3.1 启动及初始化问题
判别器损失十分接近0,那么可以确信模型出现了问题;通常会使用一些策略如故意停止某个网络的学习过程或者减小学习率,使得另一个网络可以追赶上来;
2.3.2 模型坍塌
生成器可能会在某种情况下重复生成完全一致的图像,这与模型启动具有较大关联;
2.3.3 计数方面的问题
2.3.4 角度方面的问题
2.3.5 全局结构方面的问题

1) 训练难。由于GAN模型中的判别和生成模型需要进行相互对抗,如果在训练之初就获得了一个相当准确的判别模型,能够区分大量生成的模型样本,那么生成模型所的损失值将会变得极大,从而使得模型参数无法正常更新。要解决这一问题,需要修改模型的损失函数,更好的平衡GAN中的判别和生成模型,使得其能够在这种情况下正常更新参数。目前两种常用的方法:
(i)采用近似的生成模型损失;
(ii)调整判别模型的分类边界,标注1-α为真实样本,0+β为模型样本。当α、β取值大于0时,判别器更倾向于使得生成器要么产生真实样本,要么继续产生与上一轮相似的模型样本(具体见Salimans et al. 2016)
2) 解空间大导致收敛结果不够理想。由于GAN本身没有任何约束,由于其解空间极大因此对真实样本分布的拟合不容易收敛到一个较好的结果。目前两类常用的解决方法:1)在输入z上加入一定的约束条件,例如,加入条件约束的CGAN;
2)减小生成模型的映射空间,例如,只学习残差的LAGAN;
3) Model collapse。GAN模型经常容易遇到多个输入z对应同一模型样本的情况。图 9展示了一个典型model collapse的例子:对于目标为二维环状点阵的图像,GAN容易一次收敛到一个模式上去,从而导致无法还原二维环状点阵图像。在其他图像生成的应用中,model collapse问题还容易使得产生的图像多样性不足。
一种可能的解决方法是调换目标函数中的优化顺序,先优化生成模型后优化判别模型,特别是在模型优化的初期,容易使得生成模型产生更多的可能模型样本而少受到判别模型的约束。
其他可能的解决方法是采用minibatch features进行训练:这种方法将真实样本和模型样本分割为小块,分块地由块内的特征情况进行判别(具体见Salimans et al. 2016)。
另外,在unrolled GANs中(Metz et al. 2016)提到:不用在判别模型达到最优后再优化生成模型,用少量迭代步优化,再优化生成模型,采取这种方式也可以有效避免model collapse问题;

典型的model collapse问题 4) GAN在图像的生成结果上还存在无法准确计数、生成图像的视角存在偏差以及全局结构模糊的问题。如图 10所示,生成的动物图像存在多个脑袋,在一个平面上同时展示多个维度以及类似头、手、足错位的结构问题。这些问题目前还制约着GAN的发展,需留待未来的工作提出对应的解决方案。
2.4 提高GAN训练效果的方法:
2.4.1 特征匹配
2.4.2 小批量
2.4.3 历史平均
2.4.4 单测标签平滑
0/1××××××>[0, 0.1, ......, 0.9, 1]
2.4.5 输入规范化
图像规范化到[-1, 1]范围,并用Tanh作为生成器最后的激活函数;
2.4.6 批规范化
核心思想是针对真实数据和生成数据构建不同的Batch,每个Batch只能全是真实数据或者生成数据;当此无法实现时,可使用实例规范化(对每个样本减去平均值再除以标准差);
2.4.7 利用ReLU和MaxPool避免稀疏梯度
如果梯度稀疏,GAN稳定性会受到影响,Leaky ReLU对生成器和判别器都会有很多帮助;
对于下采样场景组合使用平均值池化/Conv2d/stride;
对于上采样场景组合使用PixelShuffle/ConvTranspose2d/stride;
https://arxiv.org/abs/1609.05158
2.4.8 优化器和噪声
针对生成器使用ADAM优化器,针对判别器使用SGD,并在生成器的不同层去除输入来作为噪声的来源;
2.4.9 不要仅根据统计信息平衡损失
Improved GAN (NIPS-2016 workshop):
https://github.com/openai/improved-gan
该工作主要给出了5条有助于GAN稳定训练的经验:
(1) 特征匹配:让生成器产生的样本与真实样本在判别器中间层的响应一致,即使判别器从真实数据和生成数据中提取的特征一致,而不是在判别器网络的最后一层才做判断,有助于提高模型的稳定性;其实验也表明在一些常规方法训练GAN不稳定的情况中,若用特征匹配则可以有效避免这种不稳定;
(2) Minibatch Discrimination:在判别器中,不再每次对每一个生成数据与真实数据的差异性进行比较,而是一次比较一批生成数据与真实数据的差异性。这种做法提高了模型的鲁棒性,可以缓解生成器输出全部相似或相同的问题;
(3) Historical Averaging:受fictitious play的游戏算法启发,作者提出在生成器和判别器的目标函数中各加一个对参数的约束项其中θ[i]表示在时刻i的模型参数,该操作可以在一些情况下帮助模型达到模型的平衡点;
(4) 单边标签平滑 (One-sided Label Smoothing):当向GAN中引入标签数据时,最好是将常规的0、1取值的二值标签替换为如0.1,0.9之类的平滑标签,可以增加网络的抗干扰能力;但这里之所以说单边平滑,是因为假设生成数据为0.1而非0的话会使判别器的最优判别函数的形状发生变化,会使生成器偏向于产生相似的输出,因此对于取值0的标签保持不变,不用0.1一类的小数据替换,即为单边标签平滑;
(5) Virtual Batch Normalization:VBN相当于是BN的进阶版,BN是一次对一批数据进行归一化,这样的一个副作用是当“批”的大小不同时,BN操作之后的归一化常量会引起训练过程的波动,甚至超过输入信号z的影响(因z是随机噪声);而VBN通过引入一个参考集合,每次将当下的数据x加入参考集合构建一个新的虚拟的batch,然后在这个虚拟的batch上进行归一化,如此可以缓解原始BN操作所引起的波动问题。















 1962
1962











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









