







Tensorflow学习笔记:基础篇(9)——Mnist手写集完结版(Embedding Visualization)
前序
— 前文中,我们说了过拟合现象,通过Dropout的方法进行缓解。
— 今天是我们三层全连接神经网络的最后一篇博文,我们先来回忆一下这一系列我们做了些什么:
单层神经网络 —> 三层神经网络 —> 交叉熵函数 —> Optimizer —> Dropout —> Tensorboard
— 我们针对这个神经网络进行反复修改与优化,将准确率从0.91一步步提升至0.98,大家有没有发现,我们到目前为止得到的结果一直是一个准确率这个数字,有人似乎会好奇这些图片真的能分类的这么准吗,我们能够在Tensorboard可视化界面中看到分类完成后效果吗,答案是可以的。
— 这也引出了我们今天要做的事情:Embedding Visualization。有人会问,这是个什么玩意呢?
— 这个是Tensorflow针对moist手写数据集做的一个可视化项目,这个在Tensorflow没更新前,官网上是有的,现在出来1.4版本后,被删减掉了,我帮大家把这个网址重新找出来,供大家进行参考学习。
Reference:TensorBoard: Embedding Visualization
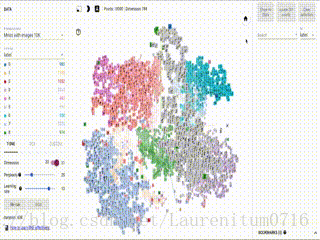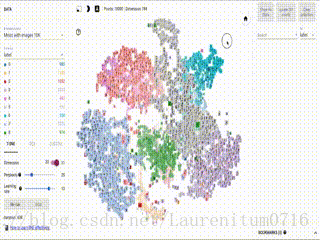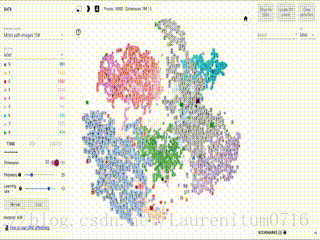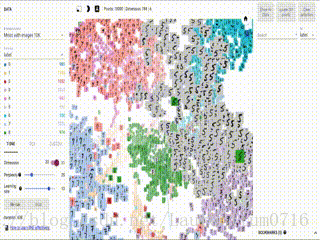
这幅动图就是我从Tensorflow官网上抓取下来的,大家可以看到一个个数字图片通过模型训练后,能够进行扎堆归类,一个数字的聚集在一块区域,用一个颜色显示,大家是不是觉得很赞呢,那么这效果究竟是怎么实现的呢~~
Setup
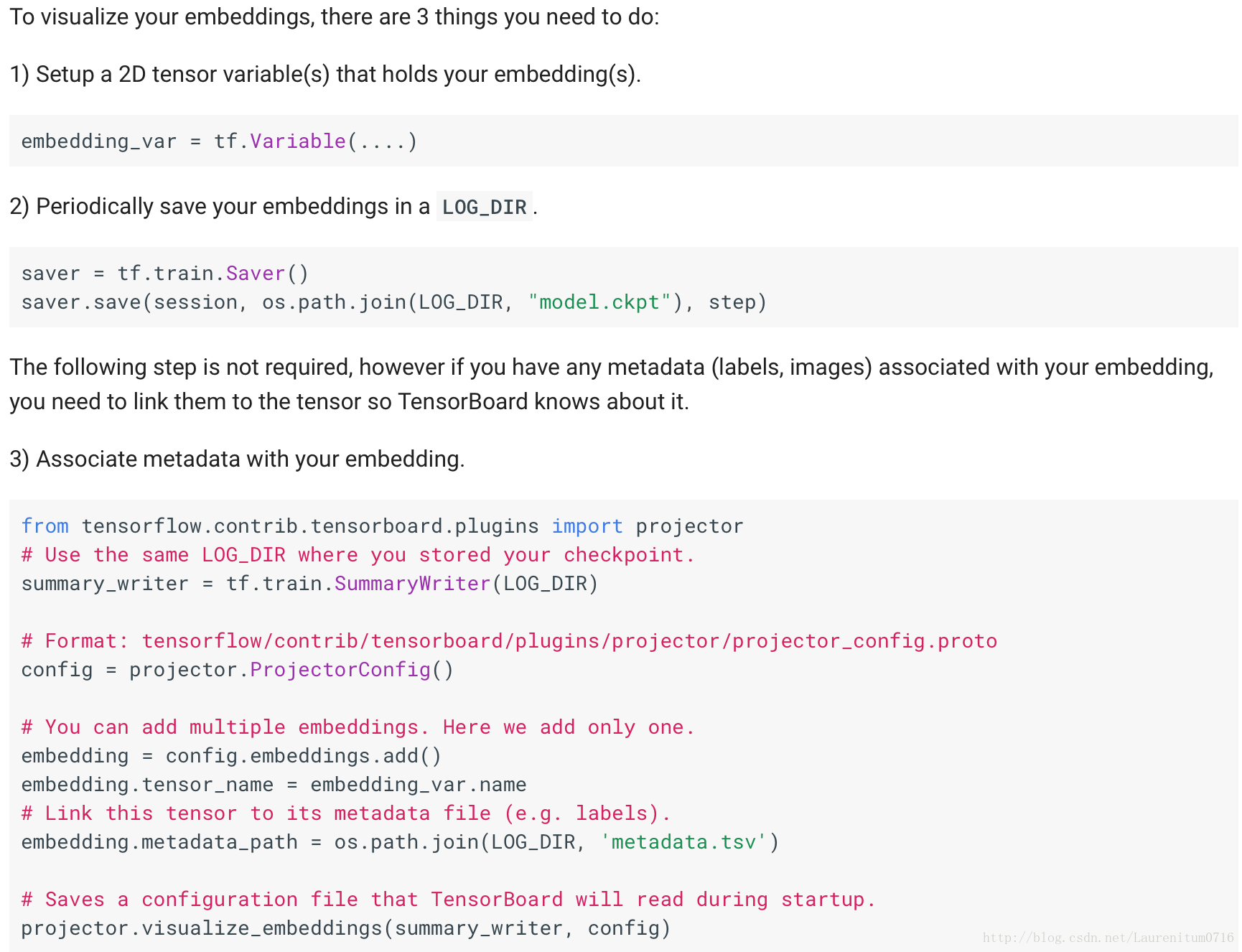
Mnist手写数据集的1w个测试集图片,被随机顺序存放在sprite image中,排列顺序为100x100,这里我给出了下载链接:sprite image
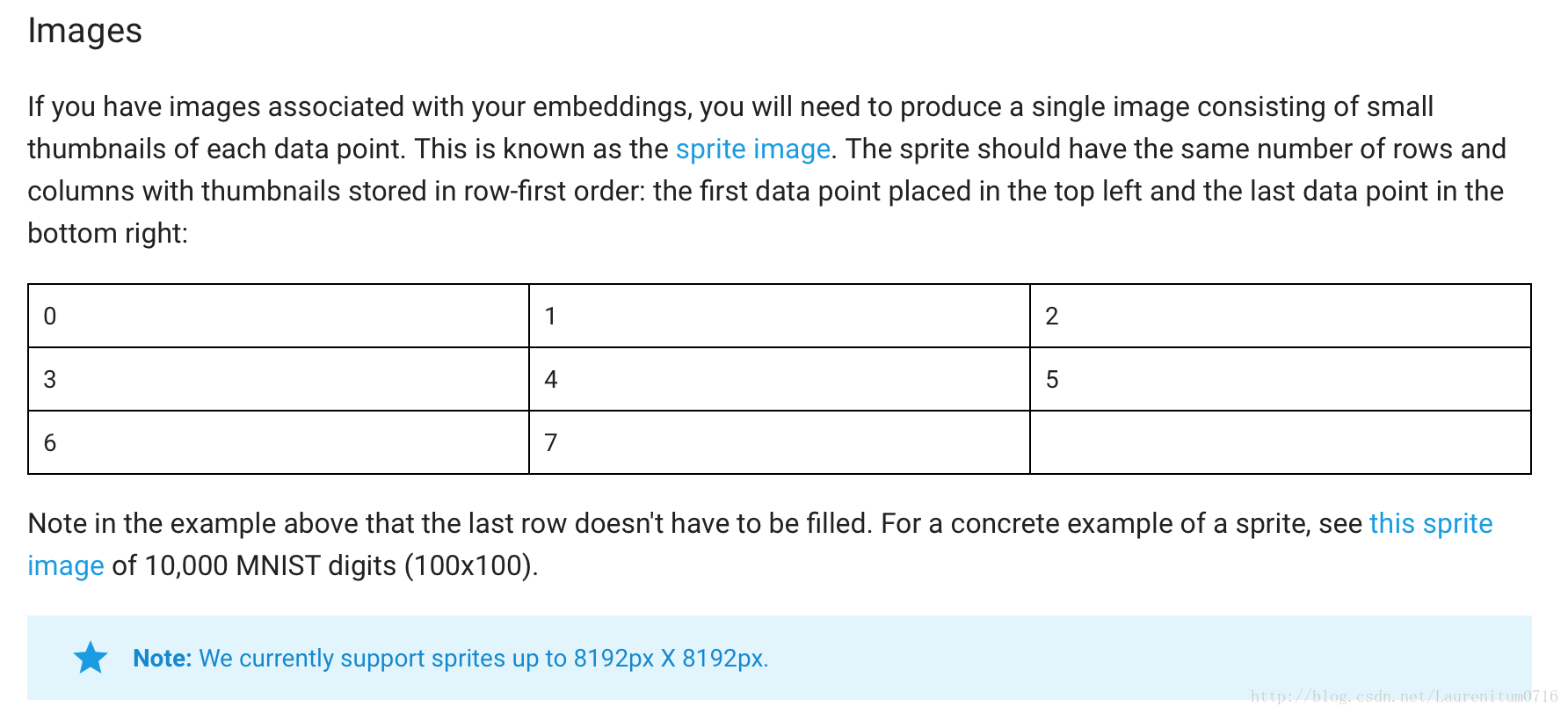

接下来,我们只需要按照官方文档,在之前的神经网络中修改即可。
准备工作
在程序的根目录中新建一个projector文件夹,就像这样:

在projector文件夹中再新建一个projector同名文件夹和一个data文件夹:

将刚才的mnist_10k_sprite.png的数据集图片放在data文件夹中:

并且保证projector的同名文件夹中清空(第一次创建不存在此问题,如第二次运行程序,请先清空,否则程序会报错)

代码示例
1、数据准备
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector
# 载入数据集
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
#图片数量
image_num = 10000
#文件路径
DIR = "F://untitled/"#设置文件路径(这是我的程序文件位置,大家自行做修改),之后生成metadata文件时会用到
#载入图片
embedding = tf.Variable(tf.stack(mnist.test.images[:image_num]), trainable=False, name='embedding')
#tf.stack(mnist.test.images[:image_num])中的image_num可以控制测试图片个数,最大为10000,我这里取值为10000
# 批次
n_batch = 100
sess = tf.Session()
#这里我们今天直接开启session,替换之前在后面用的with tf.Session() as sess
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var) ##直方图2、准备好placeholder
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')3、初始化参数/权重
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name='W1')
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.relu(tf.matmul(x, W1) + b1, name='L1')
L1_drop = tf.nn.dropout(L1, keep_prob)
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1), name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.relu(tf.matmul(L1_drop, W2) + b2, name='L2')
L2_drop = tf.nn.dropout(L2, keep_prob)
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)4、计算预测结果
prediction = tf.nn.softmax(tf.matmul(L2, W3) + b3)5、计算损失值
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss', loss)6、初始化optimizer
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
with tf.name_scope('train'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
init = tf.global_variables_initializer()
sess.run(init)
merged = tf.summary.merge_all()7、生成metadata文件
程序会在新建的projector的文件夹中的projector子文件夹中会生成一个metadata.tsv文件
# 生成metadata文件
with open(DIR + 'projector/projector/metadata.tsv', 'w') as f:
labels = sess.run(tf.argmax(mnist.test.labels[:], 1))
for i in range(image_num):
f.write(str(labels[i]) + '\n')
#下段代码,按照Tensorflow文档进行操作
projector_writer = tf.summary.FileWriter(DIR + 'projector/projector', sess.graph)
saver = tf.train.Saver()
config = projector.ProjectorConfig()
embed = config.embeddings.add()
embed.tensor_name = embedding.name
embed.metadata_path = DIR + 'projector/projector/metadata.tsv'
embed.sprite.image_path = DIR + 'projector/data/mnist_10k_sprite.png'
embed.sprite.single_image_dim.extend([28, 28])
#将下载下来的数据集图片以28x28的像素进行分隔,分隔成一个个数字图片
projector.visualize_embeddings(projector_writer, config)
7、指定迭代次数,并在session执行graph
for epoch in range(2001):
sess.run(tf.assign(lr, 0.001 * (0.95 ** (epoch / 50))))
batch_xs, batch_ys = mnist.train.next_batch(n_batch)
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, optimizer], feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.0}, options=run_options, run_metadata=run_metadata)
projector_writer.add_run_metadata(run_metadata, 'step%03d' % epoch)
projector_writer.add_summary(summary, epoch)
if epoch % 100 == 0:
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0})
learning_rate = sess.run(lr)
print("Iter" + str(epoch) + ", Testing accuracy:" + str(test_acc) + ", Learning rate:" + str(learning_rate))
saver.save(sess, DIR + 'projector/projector/a_model.ckpt', global_step=1001)
projector_writer.close()
sess.close()#因为这次没有用with tf.Session() as less,需要在最后加上本条语句
运行结果
迭代2000次,最终准确率为0.9721

我们可以看到,在刚开始保持为空的文件夹中,生成了些数据文件:
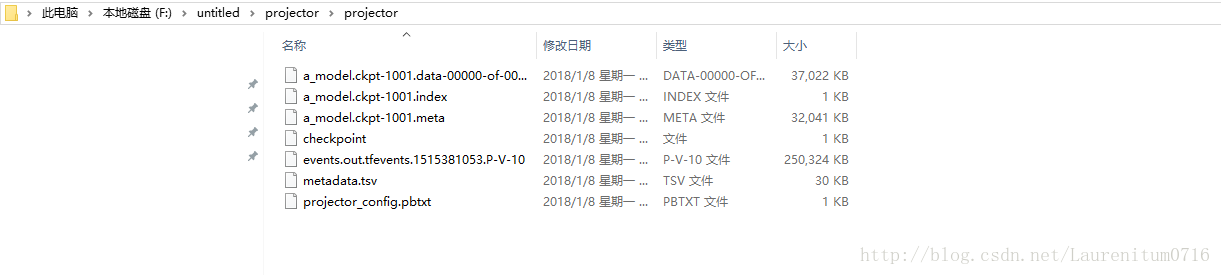
其中以P-V-10的文件类型为Tensorboard数据文件,在Tensorboard打开,与之前不同的是,标签中多了一项Projector,里面就是我们的1w张测试集图片,每张图片包含一个手写数字,密密麻麻堆叠在一起:
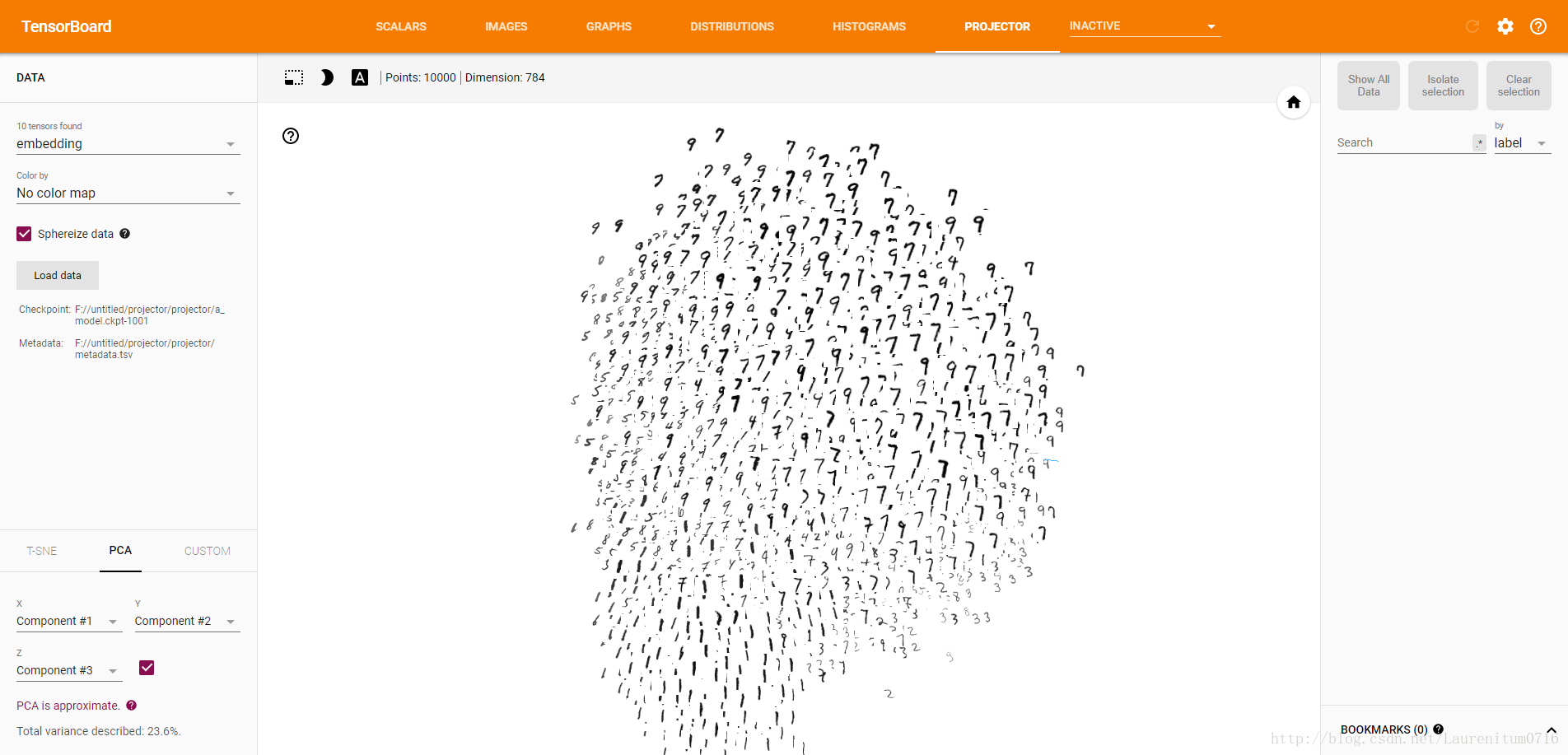
接下来,我们要做的就是进行分类识别,在这之前,我们选取左边栏中的Color,选取label 10 colors:
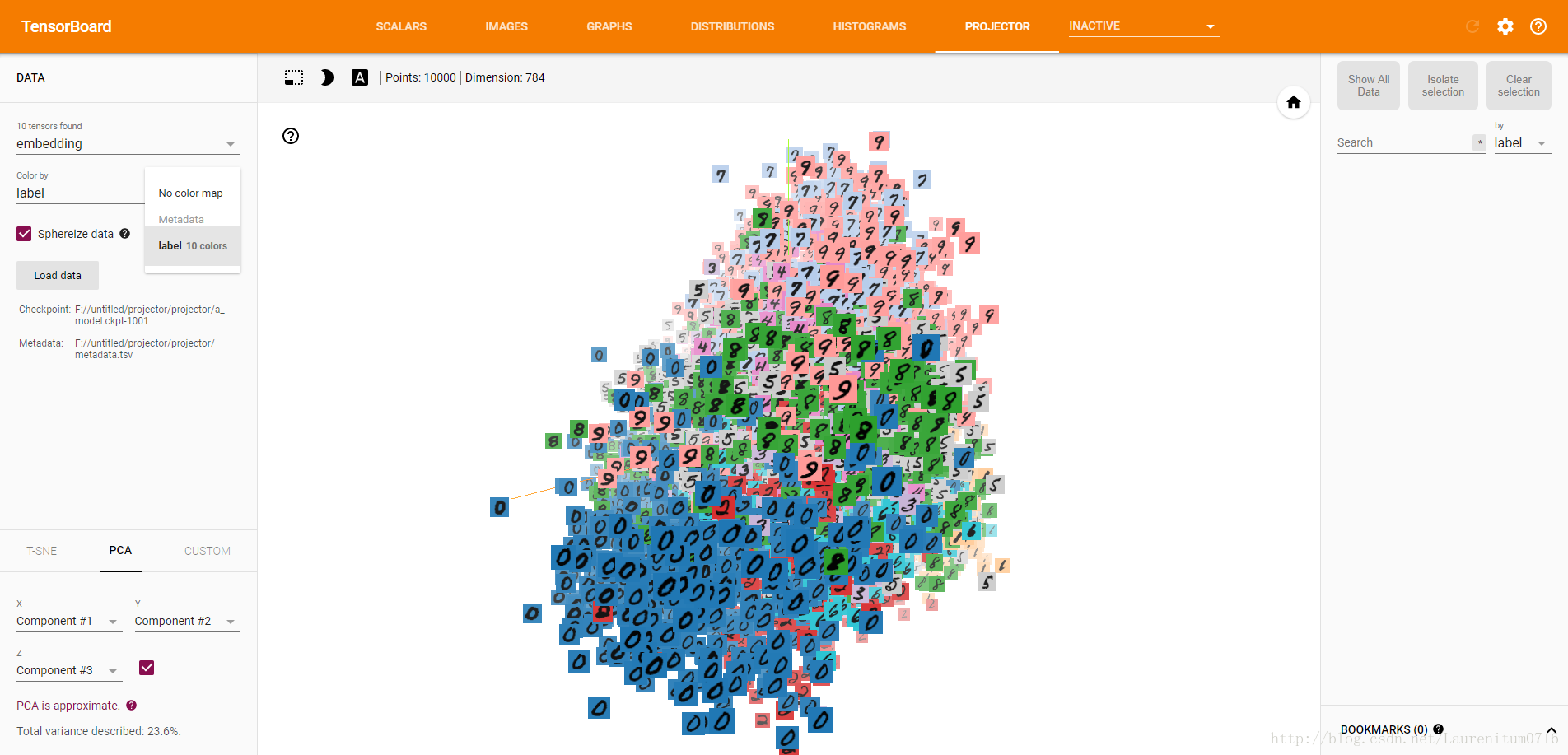
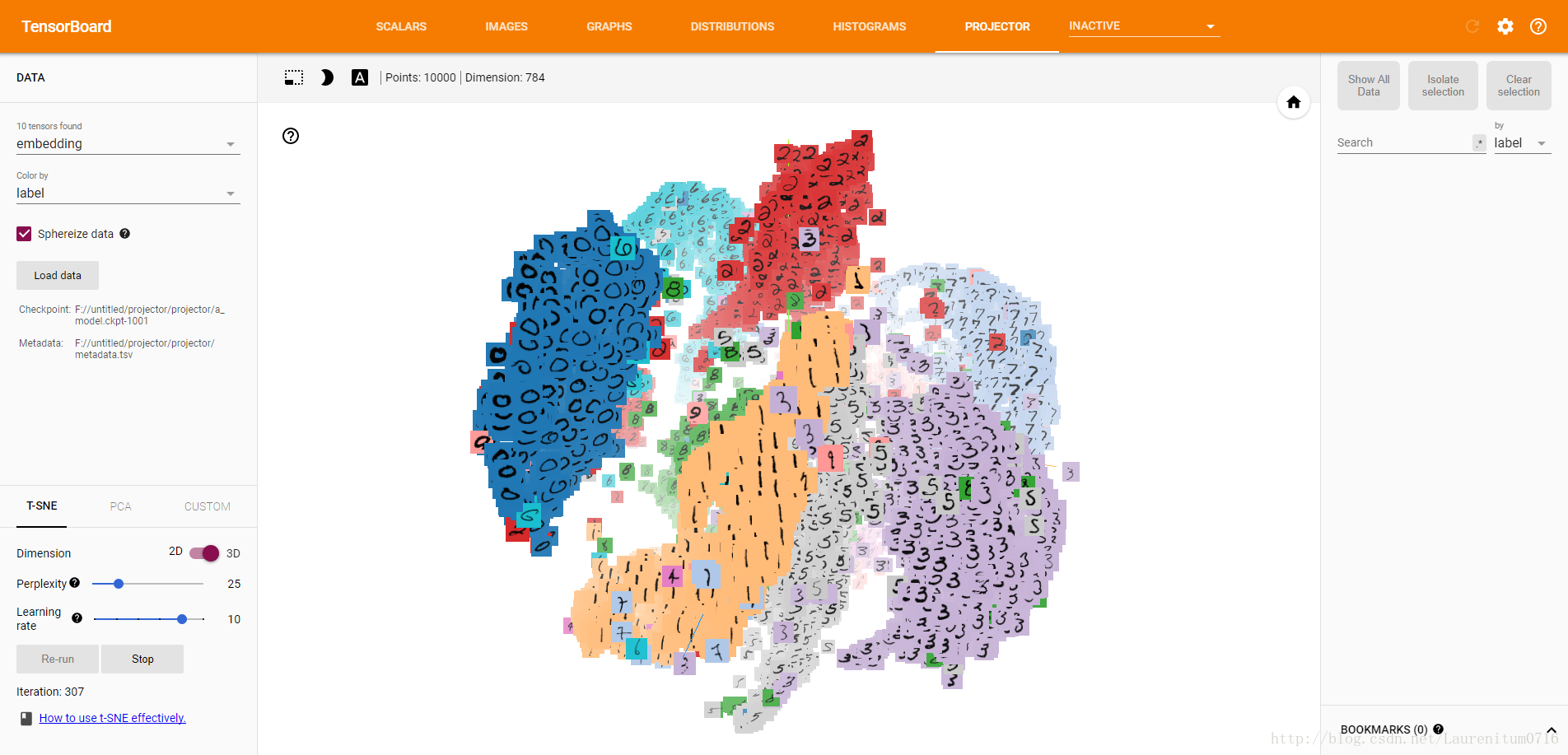
随后,我们点击左边栏下方的T-SNE,程序就会自动运行,界面中会产生动画效果,开始分类,左下角的Iteration为迭代次数,这是Iteration = 307时的分类效果:
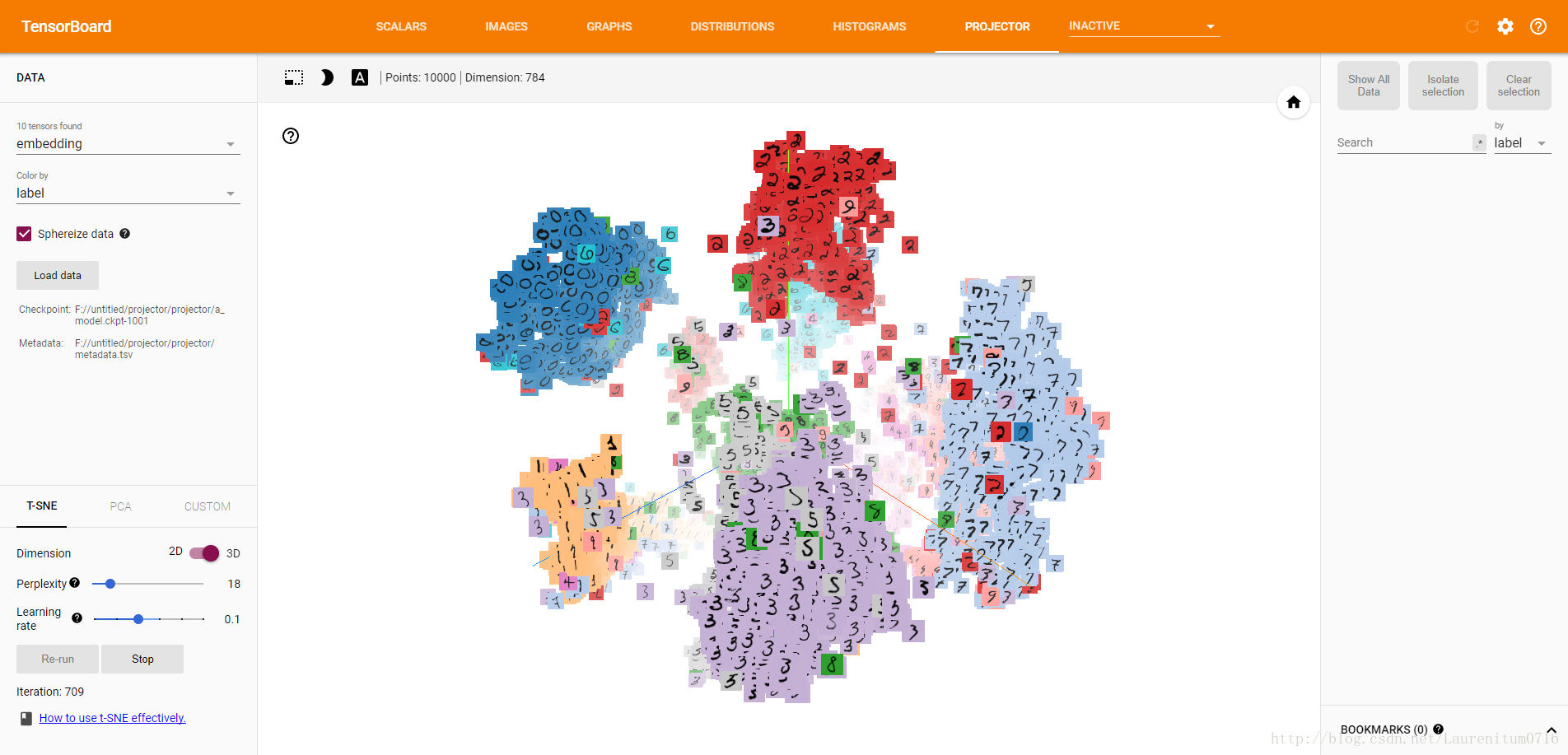
当Iteration = 709时,分类已经基本成型,由于我们模型的准确率为0.97,因此可以看到个别的数字出现分类错误的情况。
好啦,到此为止,这一系列我们用三层全连接网络实现对MNIST手写数据集的分类就告一段落了。下一个系列,将是Tensorflow对CNN卷积神经网络的介绍。
完整代码
import tensorflow as tf
from tensorflow.examples.tutorials.mnist import input_data
from tensorflow.contrib.tensorboard.plugins import projector
mnist = input_data.read_data_sets("MNIST_data", one_hot=True)
#图片数量
image_num = 10000
#文件路径
DIR = "F://untitled/"
#载入图片
embedding = tf.Variable(tf.stack(mnist.test.images[:image_num]), trainable=False, name='embedding')
# 批次
n_batch = 100
sess = tf.Session()
def variable_summaries(var):
with tf.name_scope('summaries'):
mean = tf.reduce_mean(var)
tf.summary.scalar('mean', mean)
with tf.name_scope('stddev'):
stddev = tf.sqrt(tf.reduce_mean(tf.square(var - mean)))
tf.summary.scalar('stddev', stddev)
tf.summary.scalar('max', tf.reduce_max(var))
tf.summary.scalar('min', tf.reduce_min(var))
tf.summary.histogram('histogram', var) ##直方图
with tf.name_scope('input'):
x = tf.placeholder(tf.float32, [None, 784], name='x_input')
y = tf.placeholder(tf.float32, [None, 10], name='y_input')
keep_prob = tf.placeholder(tf.float32, name='keep_prob')
lr = tf.Variable(0.001, dtype=tf.float32, name='learning_rate')
#显示图片
with tf.name_scope('input_reshape'):
image_shaped_input = tf.reshape(x, [-1, 28, 28, 1])
tf.summary.image('input', image_shaped_input, 10)
with tf.name_scope('layer'):
with tf.name_scope('Input_layer'):
with tf.name_scope('W1'):
W1 = tf.Variable(tf.truncated_normal([784, 500], stddev=0.1), name='W1')
variable_summaries(W1)
with tf.name_scope('b1'):
b1 = tf.Variable(tf.zeros([500]) + 0.1, name='b1')
variable_summaries(b1)
with tf.name_scope('L1'):
L1 = tf.nn.relu(tf.matmul(x, W1) + b1, name='L1')
L1_drop = tf.nn.dropout(L1, keep_prob)
with tf.name_scope('Hidden_layer'):
with tf.name_scope('W2'):
W2 = tf.Variable(tf.truncated_normal([500, 300], stddev=0.1), name='W2')
variable_summaries(W2)
with tf.name_scope('b2'):
b2 = tf.Variable(tf.zeros([300]) + 0.1, name='b2')
variable_summaries(b2)
with tf.name_scope('L2'):
L2 = tf.nn.relu(tf.matmul(L1_drop, W2) + b2, name='L2')
L2_drop = tf.nn.dropout(L2, keep_prob)
with tf.name_scope('Output_layer'):
with tf.name_scope('W3'):
W3 = tf.Variable(tf.truncated_normal([300, 10], stddev=0.1), name='W3')
variable_summaries(W3)
with tf.name_scope('b3'):
b3 = tf.Variable(tf.zeros([10]) + 0.1, name='b3')
variable_summaries(b3)
prediction = tf.nn.softmax(tf.matmul(L2_drop, W3) + b3)
# 二次代价函数
# loss = tf.reduce_mean(tf.square(y - prediction))
# 交叉熵代价函数
with tf.name_scope('loss'):
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(labels=y, logits=prediction))
tf.summary.scalar('loss', loss)
# 梯度下降
# optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(loss)
with tf.name_scope('optimizer'):
optimizer = tf.train.AdamOptimizer(lr).minimize(loss)
init = tf.global_variables_initializer()
sess.run(init)
with tf.name_scope('train'):
with tf.name_scope('correct_prediction'):
correct_prediction = tf.equal(tf.argmax(y, 1), tf.argmax(prediction, 1))
with tf.name_scope('accuracy'):
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32))
tf.summary.scalar('accuracy', accuracy)
# 生成metadata文件
if tf.gfile.Exists(DIR + 'projector/projector/metadata.tsv'):
tf.gfile.DeleteRecursively(DIR + 'projector/projector/metadata.tsv')
with open(DIR + 'projector/projector/metadata.tsv', 'w') as f:
labels = sess.run(tf.argmax(mnist.test.labels[:], 1))
for i in range(image_num):
f.write(str(labels[i]) + '\n')
merged = tf.summary.merge_all()
projector_writer = tf.summary.FileWriter(DIR + 'projector/projector', sess.graph)
saver = tf.train.Saver()
config = projector.ProjectorConfig()
embed = config.embeddings.add()
embed.tensor_name = embedding.name
embed.metadata_path = DIR + 'projector/projector/metadata.tsv'
embed.sprite.image_path = DIR + 'projector/data/mnist_10k_sprite.png'
embed.sprite.single_image_dim.extend([28, 28])
projector.visualize_embeddings(projector_writer, config)
for epoch in range(2001):
sess.run(tf.assign(lr, 0.001 * (0.95 ** (epoch / 50))))
batch_xs, batch_ys = mnist.train.next_batch(n_batch)
run_options = tf.RunOptions(trace_level=tf.RunOptions.FULL_TRACE)
run_metadata = tf.RunMetadata()
summary, _ = sess.run([merged, optimizer], feed_dict={x: batch_xs, y: batch_ys, keep_prob: 1.0},
options=run_options, run_metadata=run_metadata)
projector_writer.add_run_metadata(run_metadata, 'step%03d' % epoch)
projector_writer.add_summary(summary, epoch)
if epoch % 100 == 0:
test_acc = sess.run(accuracy, feed_dict={x: mnist.test.images, y: mnist.test.labels, keep_prob: 1.0})
learning_rate = sess.run(lr)
print("Iter" + str(epoch) + ", Testing accuracy:" + str(test_acc) + ", Learning rate:" + str(learning_rate))
saver.save(sess, DIR + 'projector/projector/a_model.ckpt', global_step=1001)
projector_writer.close()
sess.close()















 386
386

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}