







0x00
本篇为自己学习Python爬虫的总结,其中包括一些网站运行原理和Python编码的注意事项。整理成文,一来加深自己对代码的认识,二来或许能为他人提供一些参考。
0x01 Python基础
作为一门抽象程度比较高的语言,Python的学习曲线还是比较平缓的。以下为Python语法的学习资源。
http://www.w3cschool.cc/python/python-tutorial.html
http://www.liaoxuefeng.com/wiki/001374738125095c955c1e6d8bb493182103fac9270762a000
第一个链接的“基础教程”部分刷完后,便基本可以动手写东西了。如果基础较差,想多找些内容加深印象,可看第二个链接,或者《Python简明教程》、《Python核心编程》。
另外,编码规范可参考Google的Python风格规范。
tips :
1、复合类型:列表、元祖和字典
在C语言中,常用的序列为数组和链表,这是从实现的角度进行分类。数组可以当栈、队列或者树使用,这是从逻辑意义的角度进行分类。Python语言的抽象层度较高,语法自带的复合类型也更贴近逻辑而不是实现。
2、回调函数
Python中一切皆对象。函数对象通过函数名引用。以下是Python中回调函数的示例。
def f() :
print("callback")
def reg_module(function) :
function()
if __name__ == "__main__" :
reg_module(f)
0x02 库
实现爬虫的功能,主要涉及以下库:urllib/requests,re/BeautifulSoup。
以下为访问www.sina.com.cn时截取到的数据包。

开始为TCP的三次握手。标志位分别为SYN,SYN|ACK,ACK。
随后,为客户端发送的HTTP请求。
接下来通过chrome开发者工具分析网页获取过程。
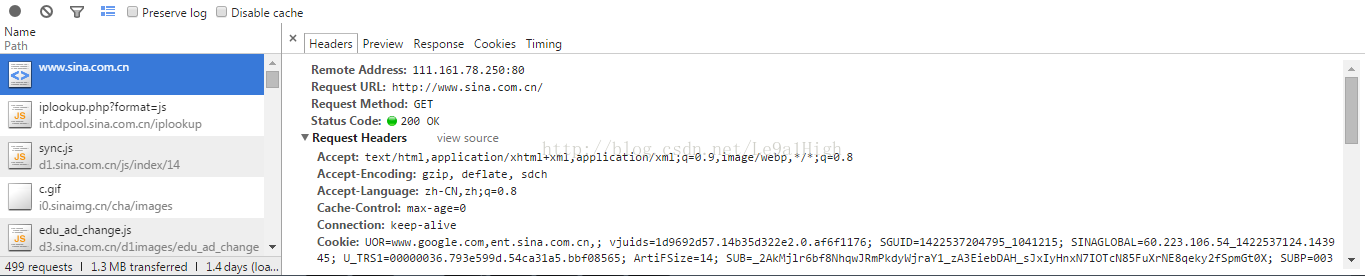
最初请求”www.sina.com.cn”,与wireshark分析得到的结果一致。浏览器接受到html文档后进行解析,分析后可得到需要下载的新URL地址。总体过程流程图如下。
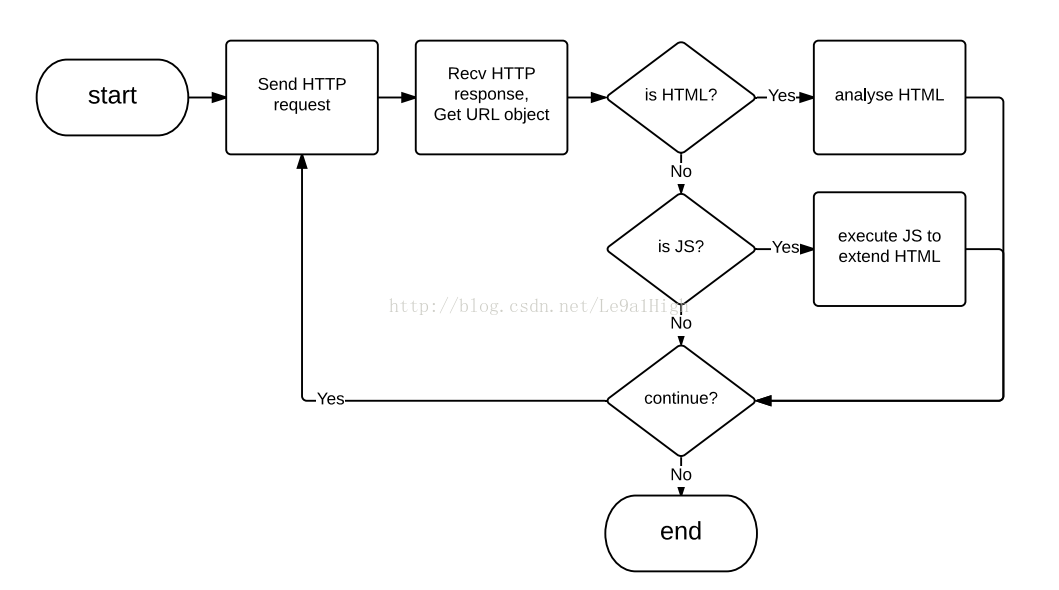
收发HTTP报文的过程,可用urllib/requests完成。解析HTML文档,可使用正则库re,或者专用的HTML解析库BeautifulSoup。解析JS的过程先不模拟。
0x03 可能遇到的问题
Python中的代码块通过缩进表示。后跟代码块的语句,以冒号结尾。代码块至少需要一条语句。若代码块为空,则填写pass(空语句)。
定义变量名时不应重名。写代码时犯过这样的错误:定义了一个名为str的字符串变量。之后的代码调用str()函数时失败。
字符串涉及两种类型:str和bytes。后者为其二进制表示,前者为字符序列。

urllib获取到的报文是bytes类型,BeautifulSoup和re库只能处理str类型的串。另外,编码方式如果错误会出现乱码。有时会出现不管utf-8解码还是gbk解码均有乱码,这点尚未搞清原因。
0x04 进一步学习的内容
1、对报文构建方式的分析
有时模拟浏览器行为,可通过构建相同的HTTP请求包实现。此时HTTP请求中涉及多个参数字段的值。构建请求包时,需分析这些字段的逻辑意义,数据从何而来或如何计算得出。
2、JS
当网页需通过JS扩展时如何实现
参考内容:















 203
203











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









