







 本文介绍如何使用Python爬虫抓取贝壳网的二手房数据,通过分析请求方式和参数,验证爬虫思路,展示完整代码,最终将数据存储为CSV文件。文章提醒在采集时注意频率和可能使用代理IP以确保爬虫稳定性。
本文介绍如何使用Python爬虫抓取贝壳网的二手房数据,通过分析请求方式和参数,验证爬虫思路,展示完整代码,最终将数据存储为CSV文件。文章提醒在采集时注意频率和可能使用代理IP以确保爬虫稳定性。
前言
本文是该专栏的第3篇,后面会持续分享python爬虫案例干货,记得关注。
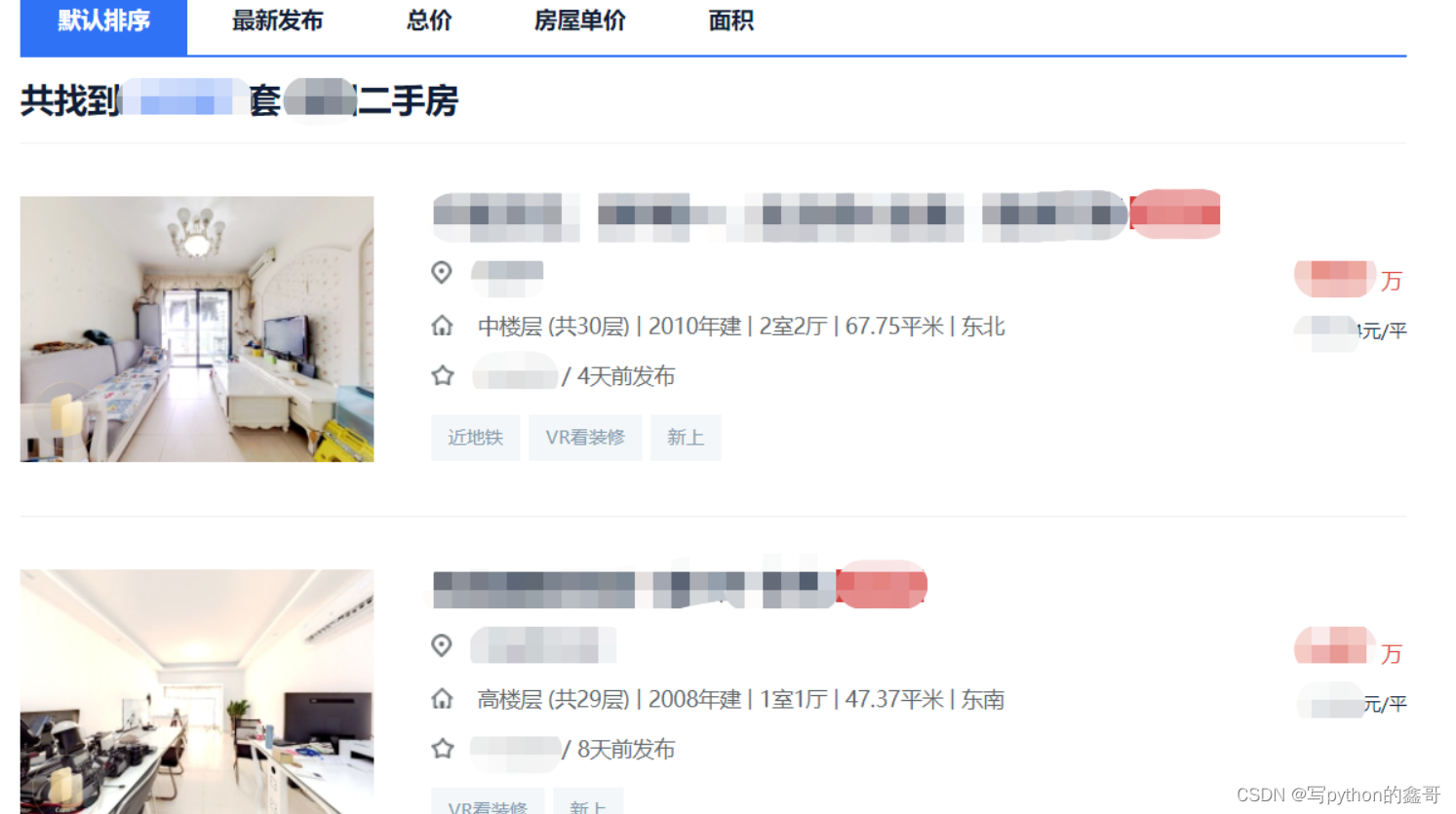
本文以某二手房网为例,如下图所示,采集对应城市的二手房源数据。具体思路和方法跟着笔者直接往下看正文详细内容。(附带完整代码)
正文
地址:aHR0cHM6Ly9zei5rZS5jb20vZXJzaG91ZmFuZy8=
目标:采集对应城市的二手房源数据
1. 请求方式和参数分析
浏览器打开目标链接之后,直接F12键启动控制台,并点击控制台右侧的Preserve log。接下来,用鼠标滑到页面底部的翻页按钮处,并随机点击几次翻页按钮。观察控制台右侧的Network下面的Fetch/XH

 订阅专栏 解锁全文
订阅专栏 解锁全文


















 595
595

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











