







二手房挂牌房源,是我们分析房地产价格分布和走势的重要参考依据。那么,我们应该如何爬取这些房源数据,并用于数据分析和可视化呢?今天我们以贝壳二手房为例,来介绍一下基本的步骤。
一、操作环境
1. 浏览器:Safari浏览器(版本:17.31)
2. Python版本:Python3.12
3. 开发环境:Pycharm 2023.3(Community Edition)
4. 操作系统:MacOS 14.3(Sonoma)
二、网页解析
1. 打开某城市的房源界面(本文以“合肥市”为例)
合肥二手房_合肥二手房出售买卖信息网【合肥贝壳找房】 https://hf.ke.com/ershoufang/rs/
https://hf.ke.com/ershoufang/rs/
2. 观察网页布局:属于典型的“分页列表式”、“静态网页”。
这类网页的爬取策略,一般是:获取总页码数➡️爬取第1页的数据➡️循环爬取每页的数据
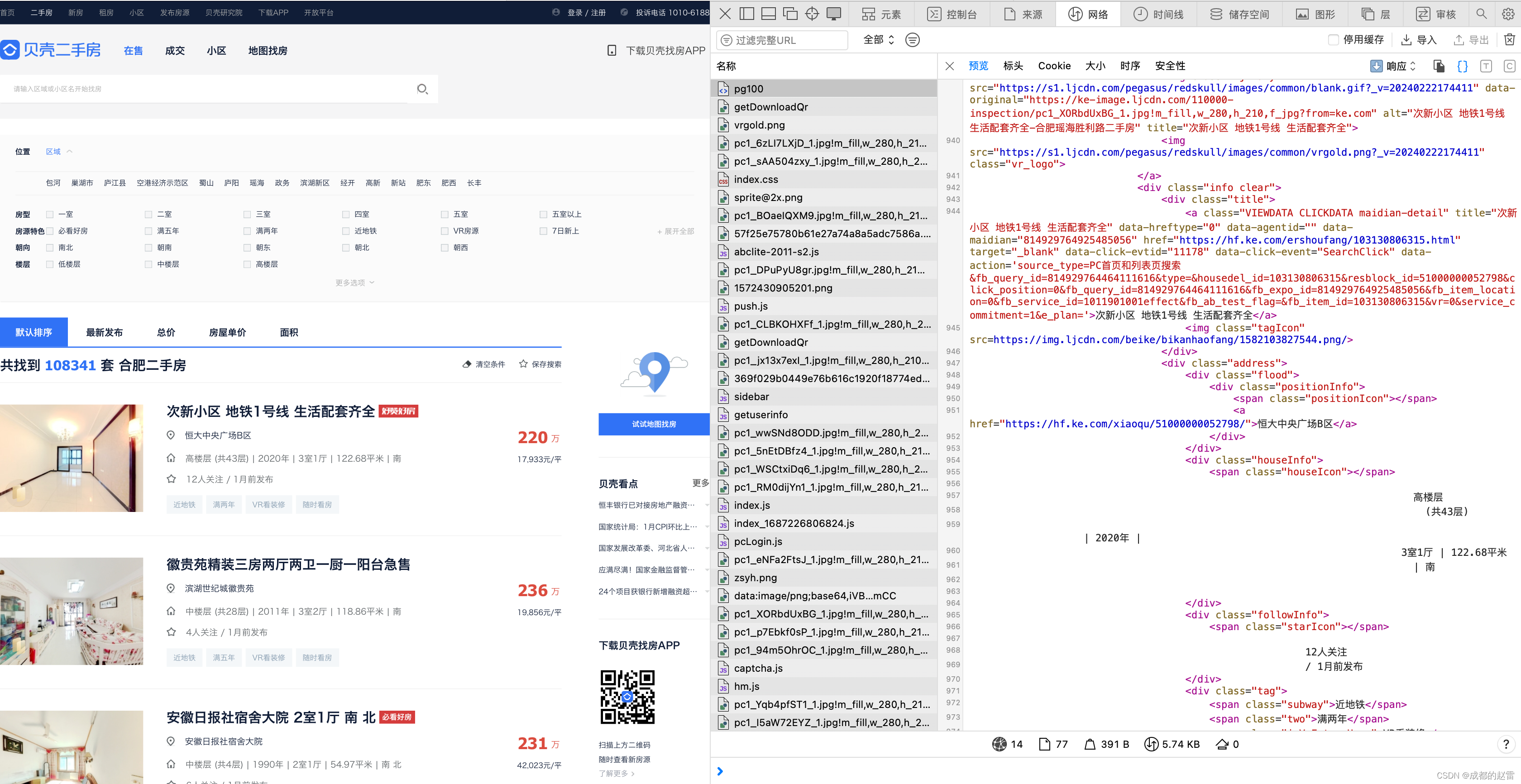
3. 寻找数据源:
页面空白处“点击右键”——“检查元素”,进入开发者工具。选择”网络“标签页,然后刷新网页,获取所有网页加载项。对列表中的所有加载项依次进行预览,寻找数据源地址。
在这里,我们很容易就发现,数据源网址为:https://hf.ke.com/ershoufang/pg100/
其实这就是该网页的网址。这意味着,房源数据就在网页html代码中。
这类网页数据的爬取策略,一般是:爬取网页html代码➡️定位并筛选出数据所在模块➡️循环筛选出每一行数据➡️对每行数据进行清洗、分类整理
4. 估计
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2645
2645

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









