







 本文介绍了如何使用ABBYY FineReader PDF 15的手动绘制区域功能来修正自动识别错误,提高文本识别准确度。通过在OCR编辑器中打开图像,删除并重新绘制图片和文字区域,可以更有效地完成文本识别任务,尤其适用于拍摄质量不佳的图像。
本文介绍了如何使用ABBYY FineReader PDF 15的手动绘制区域功能来修正自动识别错误,提高文本识别准确度。通过在OCR编辑器中打开图像,删除并重新绘制图片和文字区域,可以更有效地完成文本识别任务,尤其适用于拍摄质量不佳的图像。
虽然说ABBYY FineReader PDF 15 文本识别的智能化水平相当高,但也顶不住渣渣的拍摄水平。由于拍摄条件所限,拍摄的图像可能会出现倾斜、歪曲、包含弧度、光线暗等问题。
当我们对这些拍摄缺陷较多的图像进行文本识别时,就可能会出现区域划分错误的问题,比如将文本区域划分为图片、表格等,影响后续文本识别的准确度。在本文中,我们会学习如何对这些错误的区域进行修正,以提高识别的准确度。
一、使用OCR编辑器功能
首先,ABBYY FineReader PDF 15的区域识别功能属于智能OCR文字识别的功能,因此,需要单击“在OCR编辑器中打开”选项,打开指定的图像文件。
图1:在OCR编辑器中打开
待图像载入完成后,ABBYY FineReader PDF 15会自动开启智能识别程序。如图2所示,由于图像拍摄时有点倾斜,导致红色箭头指示的文字出现了一些识别失误,被识别为图片区域了,需手动修正一下。
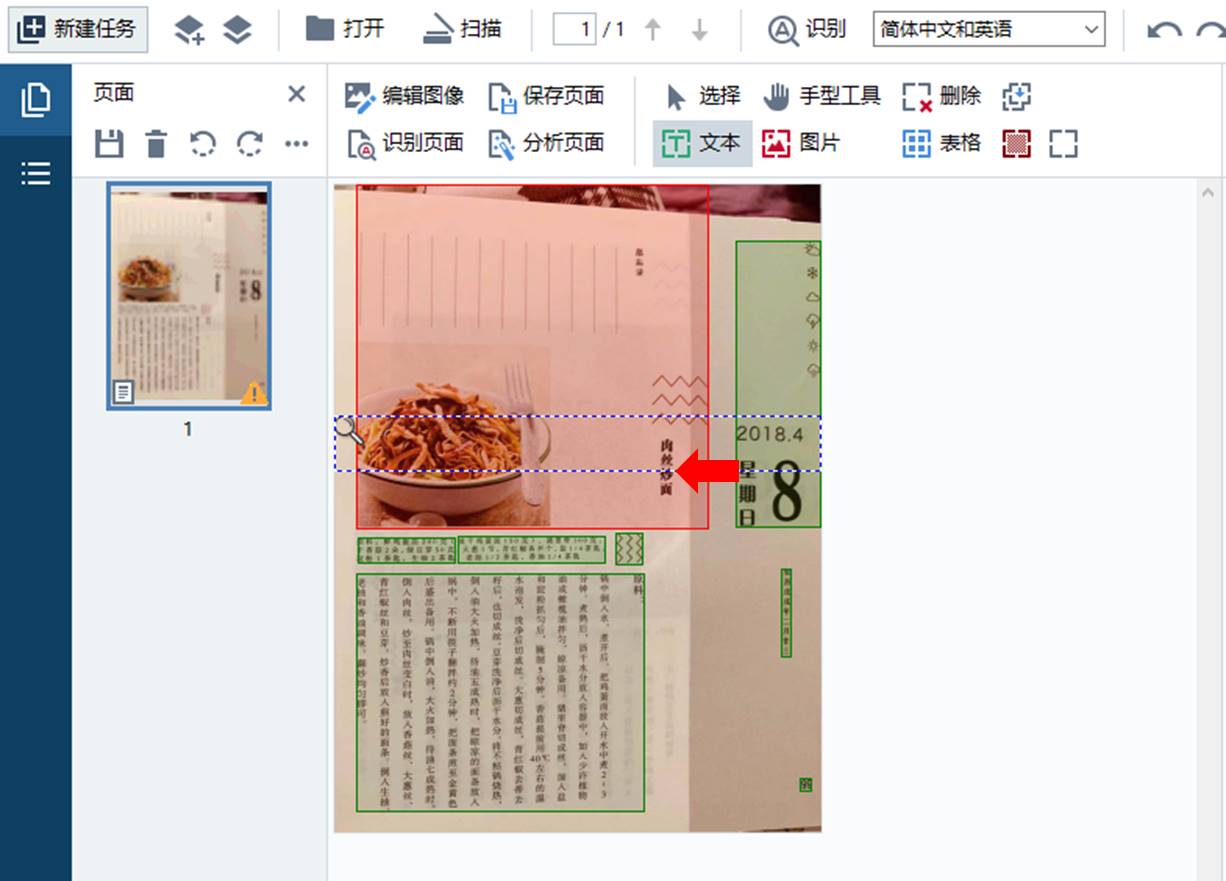
图2:自动识别区域
二、手动绘制区域
在手动绘制区域前,我们需要先删除当前的区域属性。具体的操作是,如图3所示,右击区域,并在其快捷菜单中选择“删除”。
接着,就可以重新手动绘制区域。
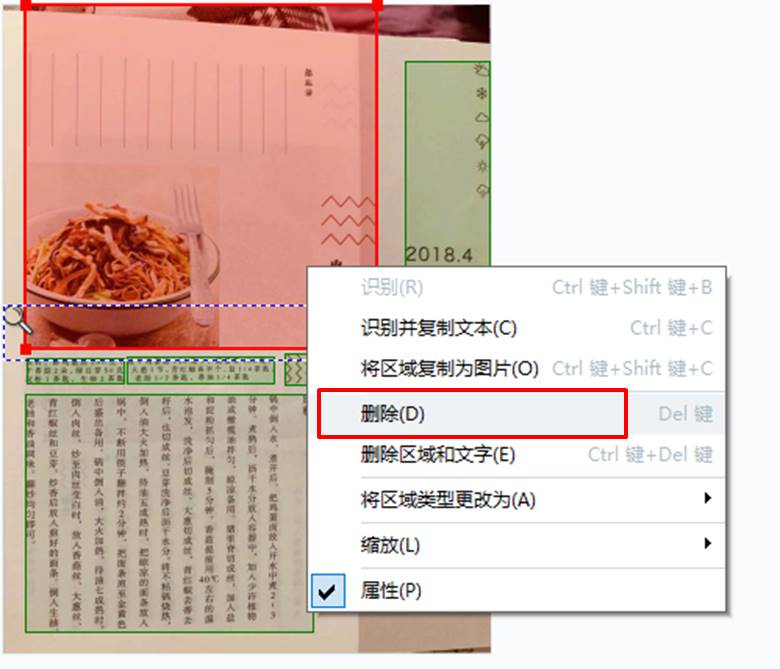
图3:删除原有区域
1.绘制图片区域
首先,先重新绘制图片区域。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









