







文章目录
7-1 邻接矩阵表示法创建无向图
采用邻接矩阵表示法创建无向图G ,依次输出各顶点的度。
输入格式:
输入第一行中给出2个整数i(0<i≤10),j(j≥0),分别为图G的顶点数和边数。
输入第二行为顶点的信息,每个顶点只能用一个字符表示。
依次输入j行,每行输入一条边依附的顶点。
输出格式:
依次输出各顶点的度,行末没有最后的空格。
输入样例:
5 7
ABCDE
AB
AD
BC
BE
CD
CE
DE
输出样例:
2 3 3 3 3
参考代码
#include<bits/stdc++.h>
using namespace std;
int tu[15][15] = {0};
int i, j;
int search(int x) {
int c = 0;
for(int k = 0; k < i; k++)
if(tu[x][k])
c++;
return c;
}
int main(){
map<char, int> m;
char a, b;
scanf("%d %d",&i,&j);
getchar();
for(int k = 0; k <i; k++) {
cin>>a;
m[a] = k;
}
getchar();
while(j--) {
scanf("%c%c",&a,&b);
getchar();
tu[m[a]][m[b]] = 1;
tu[m[b]][m[a]] = 1;
}
cout<<search(0);
for(int k = 1; k < i; k++)
cout<<' '<<search(k);
return 0;
}
代码解析
7-2 邻接表创建无向图
采用邻接表创建无向图G ,依次输出各顶点的度。
输入格式:
输入第一行中给出2个整数i(0<i≤10),j(j≥0),分别为图G的顶点数和边数。
输入第二行为顶点的信息,每个顶点只能用一个字符表示。
依次输入j行,每行输入一条边依附的顶点。
输出格式:
依次输出各顶点的度,行末没有最后的空格。
输入样例:
5 7
ABCDE
AB
AD
BC
BE
CD
CE
DE
输出样例:
2 3 3 3 3
参考代码
#include <stdio.h>
#define MAXVEX 10
#define INFINITY 65535
typedef struct {
char vexs[MAXVEX];
int edges[MAXVEX][MAXVEX];
int n, e;
} MGraph;
void CreateMGraph(MGraph *G) {
int i, j, x, y;
char a, b;
scanf("%d %d", &G->n, &G->e);
getchar();
for (i = 0; i < G->n; i++) {
scanf("%c", &G->vexs[i]);
}
for (i = 0; i < G->n; i++) {
for (j = 0; j < G->n; j++) {
G->edges[i][j] = INFINITY;
}
}
for (i = 0; i < G->e; i++) {
getchar();
scanf("%c%c", &a, &b);
for (j = 0; j < G->n; j++) {
if (a == G->vexs[j]) x = j;
if (b == G->vexs[j]) y = j;
}
G->edges[x][y] = G->edges[y][x] = 1;
}
}
int main() {
MGraph *G = (MGraph *) malloc(sizeof(MGraph));
int i, j, sum = 0;
CreateMGraph(G);
for (i = 0; i < G->n; i++) {
sum = 0;
for (j = 0; j < G->n; j++) {
if (G->edges[i][j] == 1)
sum++;
}
if (i != 0) printf(" ");
printf("%d", sum);
}
return 0;
}
代码解析
7-3 图深度优先遍历
编写程序对给定的有向图(不一定连通)进行深度优先遍历,图中包含n个顶点,编号为0至n-1。本题限定在深度优先遍历过程中,如果同时出现多个待访问的顶点,则优先选择编号最小的一个进行访问,以顶点0为遍历起点。
输入格式:
输入第一行为两个整数n和e,分别表示图的顶点数和边数,其中n不超过20000,e不超过50。接下来e行表示每条边的信息,每行为两个整数a、b,表示该边的端点编号,但各边并非按端点编号顺序排列。
输出格式:
输出为一行整数,每个整数后一个空格,即该有向图的深度优先遍历结点序列。
输入样例1:
3 3
0 1
1 2
0 2
输出样例1:
0 1 2
输入样例2:
4 4
0 2
0 1
1 2
3 0
输出样例2:
0 1 2 3
参考代码
#include<bits/stdc++.h>
using namespace std;
int book[20005];
vector<int> v[20005];
void dfs(int cur) {
cout << cur << " ";
book[cur] = 1;
int len = v[cur].size();
for (int i = 0;i < len;i++) {
if (book[v[cur][i]] == 0) {
dfs(v[cur][i]);
}
}
}
int main() {
int n, e;
cin >> n >> e;
int a, b;
for (int i = 1;i <= e;i++) {
cin >> a >> b;
v[a].push_back(b);
}
for (int i = 0;i < n;i++) {
sort(v[i].begin(), v[i].end());
}
for(int i=0;i<n;i++){
if(book[i]==0)
dfs(i);
}
}
代码解析
7-4 单源最短路径
请编写程序求给定正权有向图的单源最短路径长度。图中包含n个顶点,编号为0至n-1,以顶点0作为源点。
输入格式:
输入第一行为两个正整数n和e,分别表示图的顶点数和边数,其中n不超过20000,e不超过1000。接下来e行表示每条边的信息,每行为3个非负整数a、b、c,其中a和b表示该边的端点编号,c表示权值。各边并非按端点编号顺序排列。
输出格式:
输出为一行整数,为按顶点编号顺序排列的源点0到各顶点的最短路径长度(不含源点到源点),每个整数后一个空格。如源点到某顶点无最短路径,则不输出该条路径长度。
输入样例:
4 4
0 1 1
0 3 1
1 3 1
2 0 1
输出样例:
1 1
参考代码
代码解析
7-5 列出连通集
给定一个有N个顶点和E条边的无向图,请用DFS和BFS分别列出其所有的连通集。假设顶点从0到N−1编号。进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。
输入格式:
输入第1行给出2个整数N(0<N≤10)和E,分别是图的顶点数和边数。随后E行,每行给出一条边的两个端点。每行中的数字之间用1空格分隔。
输出格式:
按照"{ v1,v2,… vk }"的格式,每行输出一个连通集。先输出DFS的结果,再输出BFS的结果。
输入样例:
8 6
0 7
0 1
2 0
4 1
2 4
3 5
输出样例:
{ 0 1 4 2 7 }
{ 3 5 }
{ 6 }
{ 0 1 2 7 4 }
{ 3 5 }
{ 6 }
参考代码
#include<stdio.h>
#include<stdlib.h>
//c语言の谋杀事件
//存储结构
typedef int vertex;
#define MaxSize 10
int Visited_DFS[MaxSize];
int Visited_BFS[MaxSize];
typedef struct ENode{
vertex V1,V2;
}*Edge;
typedef struct GNode{
int Nv;
int Ne;
int G[MaxSize][MaxSize];
}*MGraph;
//队列类型定义
typedef struct QNode{
int Data[10];
int front;
int rear;
}*Queue;
//初始化
Queue InitQ(){
Queue Q;
Q=(Queue)malloc(sizeof(struct QNode));
Q->front=Q->rear=0;
return Q;
}
int IsEmpty(Queue Q){
return Q->front==Q->rear;
}
//入队
void AddQ(Queue Q,vertex V){
if((Q->rear+1)%MaxSize!=Q->front)
{ Q->rear=(Q->rear+1)%MaxSize;
Q->Data[Q->rear]=V;
}
}
//出队
int DeleteQ(Queue Q){
if(Q->front==Q->rear) return -1;
else {
Q->front=(Q->front+1)%MaxSize;
return Q->Data[Q->front];
}
}
//初始化图
MGraph InitGraph(int N){
MGraph Graph;
Graph=(MGraph)malloc(sizeof(struct GNode));
Graph->Nv=N;
Graph->Ne=0;
int V,W;
for(V=0;V<Graph->Nv;V++)
for(W=0;W<Graph->Nv;W++)
Graph->G[V][W]=0;
for(V=0;V<Graph->Nv;V++){
Visited_DFS[V]=0;
Visited_BFS[V]=0;
}
return Graph;
}
//插入边
void InsertEdge(MGraph Graph,Edge E){
Graph->G[E->V1][E->V2]=1;
Graph->G[E->V2][E->V1]=1;
}
//构造图
MGraph CreateGraph(MGraph Graph,int Ne){
Graph->Ne=Ne;
Edge E;
if(Graph->Ne!=0){
E=(Edge)malloc(sizeof(struct ENode));
for(int i=0;i<Graph->Ne;i++){
scanf("%d %d",&E->V1,&E->V2);
InsertEdge(Graph,E);
}
}
return Graph;
}
void DFS(MGraph Graph,vertex V){
printf(" %d",V);
Visited_DFS[V]=1;
vertex W;
for(W=0;W<Graph->Nv;W++)
if(!Visited_DFS[W]&&Graph->G[V][W]==1)
DFS(Graph,W);
}
void total_DFS(MGraph Graph){
vertex V;
for(V=0;V<Graph->Nv;V++){
if(Visited_DFS[V]==0)
{ printf("{");
DFS(Graph,V);
printf(" }");
printf("\n");}
}
}
void BFS(MGraph Graph,vertex V){
Queue Q;
Q=InitQ();
AddQ(Q,V);
Visited_BFS[V]=1;
printf(" %d",V);
vertex W;
while(!IsEmpty(Q)) {
V=DeleteQ(Q);
for(W=0;W<Graph->Nv;W++){
if(!Visited_BFS[W]&&Graph->G[V][W]==1){
printf(" %d",W);
AddQ(Q,W);
Visited_BFS[W]=1;
}
}
}
}
void total_BFS(MGraph Graph){
vertex V;
for(V=0;V<Graph->Nv;V++){
if(Visited_BFS[V]==0)
{ printf("{");
BFS(Graph,V);
printf(" }");
printf("\n");}
}
}
int main(){
int N,E;
MGraph Graph;
scanf("%d%d",&N,&E);
Graph=InitGraph(N);
Graph=CreateGraph(Graph,E);
total_DFS(Graph);
total_BFS(Graph);
return 0;
}
代码解析
7-6 哈利·波特的考试
哈利·波特要考试了,他需要你的帮助。这门课学的是用魔咒将一种动物变成另一种动物的本事。例如将猫变成老鼠的魔咒是haha,将老鼠变成鱼的魔咒是hehe等等。反方向变化的魔咒就是简单地将原来的魔咒倒过来念,例如ahah可以将老鼠变成猫。另外,如果想把猫变成鱼,可以通过念一个直接魔咒lalala,也可以将猫变老鼠、老鼠变鱼的魔咒连起来念:hahahehe。
现在哈利·波特的手里有一本教材,里面列出了所有的变形魔咒和能变的动物。老师允许他自己带一只动物去考场,要考察他把这只动物变成任意一只指定动物的本事。于是他来问你:带什么动物去可以让最难变的那种动物(即该动物变为哈利·波特自己带去的动物所需要的魔咒最长)需要的魔咒最短?例如:如果只有猫、鼠、鱼,则显然哈利·波特应该带鼠去,因为鼠变成另外两种动物都只需要念4个字符;而如果带猫去,则至少需要念6个字符才能把猫变成鱼;同理,带鱼去也不是最好的选择。
输入格式:
输入说明:输入第1行给出两个正整数N (≤100)和M,其中N是考试涉及的动物总数,M是用于直接变形的魔咒条数。为简单起见,我们将动物按1~N编号。随后M行,每行给出了3个正整数,分别是两种动物的编号、以及它们之间变形需要的魔咒的长度(≤100),数字之间用空格分隔。
输出格式:
输出哈利·波特应该带去考场的动物的编号、以及最长的变形魔咒的长度,中间以空格分隔。如果只带1只动物是不可能完成所有变形要求的,则输出0。如果有若干只动物都可以备选,则输出编号最小的那只。
输入样例:
6 11
3 4 70
1 2 1
5 4 50
2 6 50
5 6 60
1 3 70
4 6 60
3 6 80
5 1 100
2 4 60
5 2 80
输出样例:
4 70
参考代码
代码解析
7-7 家庭房产
给定每个人的家庭成员和其自己名下的房产,请你统计出每个家庭的人口数、人均房产面积及房产套数。
输入格式:
输入第一行给出一个正整数N(≤1000),随后N行,每行按下列格式给出一个人的房产:
编号 父 母 k 孩子1 … 孩子k 房产套数 总面积
其中编号是每个人独有的一个4位数的编号;父和母分别是该编号对应的这个人的父母的编号(如果已经过世,则显示-1);k(0≤k≤5)是该人的子女的个数;孩子i是其子女的编号。
输出格式:
首先在第一行输出家庭个数(所有有亲属关系的人都属于同一个家庭)。随后按下列格式输出每个家庭的信息:
家庭成员的最小编号 家庭人口数 人均房产套数 人均房产面积
其中人均值要求保留小数点后3位。家庭信息首先按人均面积降序输出,若有并列,则按成员编号的升序输出。
输入样例:
10
6666 5551 5552 1 7777 1 100
1234 5678 9012 1 0002 2 300
8888 -1 -1 0 1 1000
2468 0001 0004 1 2222 1 500
7777 6666 -1 0 2 300
3721 -1 -1 1 2333 2 150
9012 -1 -1 3 1236 1235 1234 1 100
1235 5678 9012 0 1 50
2222 1236 2468 2 6661 6662 1 300
2333 -1 3721 3 6661 6662 6663 1 100
输出样例:
3
8888 1 1.000 1000.000
0001 15 0.600 100.000
5551 4 0.750 100.000
参考代码
代码解析
7-8 森森美图
森森最近想让自己的朋友圈熠熠生辉,所以他决定自己写个美化照片的软件,并起名为森森美图。众所周知,在合照中美化自己的面部而不美化合照者的面部是让自己占据朋友圈高点的绝好方法,因此森森美图里当然得有这个功能。 这个功能的第一步是将自己的面部选中。森森首先计算出了一个图像中所有像素点与周围点的相似程度的分数,分数越低表示某个像素点越“像”一个轮廓边缘上的点。 森森认为,任意连续像素点的得分之和越低,表示它们组成的曲线和轮廓边缘的重合程度越高。为了选择出一个完整的面部,森森决定让用户选择面部上的两个像素点A和B,则连接这两个点的直线就将图像分为两部分,然后在这两部分中分别寻找一条从A到B且与轮廓重合程度最高的曲线,就可以拼出用户的面部了。 然而森森计算出来得分矩阵后,突然发现自己不知道怎么找到这两条曲线了,你能帮森森当上朋友圈的小王子吗?
为了解题方便,我们做出以下补充说明:
图像的左上角是坐标原点(0,0),我们假设所有像素按矩阵格式排列,其坐标均为非负整数(即横轴向右为正,纵轴向下为正)。
忽略正好位于连接A和B的直线(注意不是线段)上的像素点,即不认为这部分像素点在任何一个划分部分上,因此曲线也不能经过这部分像素点。
曲线是八连通的(即任一像素点可与其周围的8个像素连通),但为了计算准确,某像素连接对角相邻的斜向像素时,得分额外增加两个像素分数和的 √2 倍减一。例如样例中,经过坐标为(3,1)和(4,2)的两个像素点的曲线,其得分应该是这两个像素点的分数和(2+2),再加上额外的(2+2)乘以( √2−1),即约为5.66。
输入格式:
输入在第一行给出两个正整数N和M(5≤N,M≤100),表示像素得分矩阵的行数和列数。
接下来N行,每行M个不大于1000的非负整数,即为像素点的分值。最后一行给出用户选择的起始和结束像素点的坐标(X start,Y start)和(X end,Y end )。4个整数用空格分隔。
输出格式:
在一行中输出划分图片后找到的轮廓曲线的得分和,保留小数点后两位。注意起点和终点的得分不要重复计算。
输入样例:
6 6
9 0 1 9 9 9
9 9 1 2 2 9
9 9 2 0 2 9
9 9 1 1 2 9
9 9 3 3 1 1
9 9 9 9 9 9
2 1 5 4
输出样例:
27.04
参考代码
代码解析
7-9 哥尼斯堡的“七桥问题”
哥尼斯堡是位于普累格河上的一座城市,它包含两个岛屿及连接它们的七座桥,如下图所示。
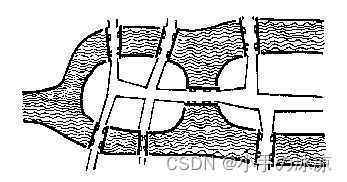
可否走过这样的七座桥,而且每桥只走过一次?瑞士数学家欧拉(Leonhard Euler,1707—1783)最终解决了这个问题,并由此创立了拓扑学。
这个问题如今可以描述为判断欧拉回路是否存在的问题。欧拉回路是指不令笔离开纸面,可画过图中每条边仅一次,且可以回到起点的一条回路。现给定一个无向图,问是否存在欧拉回路?
输入格式:
输入第一行给出两个正整数,分别是节点数N (1≤N≤1000)和边数M;随后的M行对应M条边,每行给出一对正整数,分别是该条边直接连通的两个节点的编号(节点从1到N编号)。
输出格式:
若欧拉回路存在则输出1,否则输出0。
输入样例1:
6 10
1 2
2 3
3 1
4 5
5 6
6 4
1 4
1 6
3 4
3 6
输出样例1:
1
输入样例2:
5 8
1 2
1 3
2 3
2 4
2 5
5 3
5 4
3 4
输出样例2:
0
参考代码
代码解析
7-10 公路村村通
现有村落间道路的统计数据表中,列出了有可能建设成标准公路的若干条道路的成本,求使每个村落都有公路连通所需要的最低成本。
输入格式:
输入数据包括城镇数目正整数N(≤1000)和候选道路数目M(≤3N);随后的M行对应M条道路,每行给出3个正整数,分别是该条道路直接连通的两个城镇的编号以及该道路改建的预算成本。为简单起见,城镇从1到N编号。
输出格式:
输出村村通需要的最低成本。如果输入数据不足以保证畅通,则输出−1,表示需要建设更多公路。
输入样例:
6 15
1 2 5
1 3 3
1 4 7
1 5 4
1 6 2
2 3 4
2 4 6
2 5 2
2 6 6
3 4 6
3 5 1
3 6 1
4 5 10
4 6 8
5 6 3
输出样例:
12
参考代码
代码解析
7-11 旅游规划
有了一张自驾旅游路线图,你会知道城市间的高速公路长度、以及该公路要收取的过路费。现在需要你写一个程序,帮助前来咨询的游客找一条出发地和目的地之间的最短路径。如果有若干条路径都是最短的,那么需要输出最便宜的一条路径。
输入格式:
输入说明:输入数据的第1行给出4个正整数N、M、S、D,其中N(2≤N≤500)是城市的个数,顺便假设城市的编号为0~(N−1);M是高速公路的条数;S是出发地的城市编号;D是目的地的城市编号。随后的M行中,每行给出一条高速公路的信息,分别是:城市1、城市2、高速公路长度、收费额,中间用空格分开,数字均为整数且不超过500。输入保证解的存在。
输出格式:
在一行里输出路径的长度和收费总额,数字间以空格分隔,输出结尾不能有多余空格。
输入样例:
4 5 0 3
0 1 1 20
1 3 2 30
0 3 4 10
0 2 2 20
2 3 1 20
输出样例:
3 40
参考代码
代码解析
7-12 关键活动
假定一个工程项目由一组子任务构成,子任务之间有的可以并行执行,有的必须在完成了其它一些子任务后才能执行。“任务调度”包括一组子任务、以及每个子任务可以执行所依赖的子任务集。
比如完成一个专业的所有课程学习和毕业设计可以看成一个本科生要完成的一项工程,各门课程可以看成是子任务。有些课程可以同时开设,比如英语和C程序设计,它们没有必须先修哪门的约束;有些课程则不可以同时开设,因为它们有先后的依赖关系,比如C程序设计和数据结构两门课,必须先学习前者。
但是需要注意的是,对一组子任务,并不是任意的任务调度都是一个可行的方案。比如方案中存在“子任务A依赖于子任务B,子任务B依赖于子任务C,子任务C又依赖于子任务A”,那么这三个任务哪个都不能先执行,这就是一个不可行的方案。
任务调度问题中,如果还给出了完成每个子任务需要的时间,则我们可以算出完成整个工程需要的最短时间。在这些子任务中,有些任务即使推迟几天完成,也不会影响全局的工期;但是有些任务必须准时完成,否则整个项目的工期就要因此延误,这种任务就叫“关键活动”。
请编写程序判定一个给定的工程项目的任务调度是否可行;如果该调度方案可行,则计算完成整个工程项目需要的最短时间,并输出所有的关键活动。
输入格式:
输入第1行给出两个正整数N(≤100)和M,其中N是任务交接点(即衔接相互依赖的两个子任务的节点,例如:若任务2要在任务1完成后才开始,则两任务之间必有一个交接点)的数量。交接点按1N编号,M是子任务的数量,依次编号为1M。随后M行,每行给出了3个正整数,分别是该任务开始和完成涉及的交接点编号以及该任务所需的时间,整数间用空格分隔。
输出格式:
如果任务调度不可行,则输出0;否则第1行输出完成整个工程项目需要的时间,第2行开始输出所有关键活动,每个关键活动占一行,按格式“V->W”输出,其中V和W为该任务开始和完成涉及的交接点编号。关键活动输出的顺序规则是:任务开始的交接点编号小者优先,起点编号相同时,与输入时任务的顺序相反。
输入样例:
7 8
1 2 4
1 3 3
2 4 5
3 4 3
4 5 1
4 6 6
5 7 5
6 7 2
输出样例:
17
1->2
2->4
4->6
6->7
参考代码
代码解析
7-13 任务调度的合理性
假定一个工程项目由一组子任务构成,子任务之间有的可以并行执行,有的必须在完成了其它一些子任务后才能执行。“任务调度”包括一组子任务、以及每个子任务可以执行所依赖的子任务集。
比如完成一个专业的所有课程学习和毕业设计可以看成一个本科生要完成的一项工程,各门课程可以看成是子任务。有些课程可以同时开设,比如英语和C程序设计,它们没有必须先修哪门的约束;有些课程则不可以同时开设,因为它们有先后的依赖关系,比如C程序设计和数据结构两门课,必须先学习前者。
但是需要注意的是,对一组子任务,并不是任意的任务调度都是一个可行的方案。比如方案中存在“子任务A依赖于子任务B,子任务B依赖于子任务C,子任务C又依赖于子任务A”,那么这三个任务哪个都不能先执行,这就是一个不可行的方案。你现在的工作是写程序判定任何一个给定的任务调度是否可行。
输入格式:
输入说明:输入第一行给出子任务数N(≤100),子任务按1~N编号。随后N行,每行给出一个子任务的依赖集合:首先给出依赖集合中的子任务数K,随后给出K个子任务编号,整数之间都用空格分隔。
输出格式:
如果方案可行,则输出1,否则输出0。
输入样例1:
12
0
0
2 1 2
0
1 4
1 5
2 3 6
1 3
2 7 8
1 7
1 10
1 7
输出样例1:
1
输入样例2:
5
1 4
2 1 4
2 2 5
1 3
0
输出样例2:
0
参考代码
代码解析
7-14 最短工期
一个项目由若干个任务组成,任务之间有先后依赖顺序。项目经理需要设置一系列里程碑,在每个里程碑节点处检查任务的完成情况,并启动后续的任务。现给定一个项目中各个任务之间的关系,请你计算出这个项目的最早完工时间。
输入格式:
首先第一行给出两个正整数:项目里程碑的数量 N(≤100)和任务总数 M。这里的里程碑从 0 到 N−1 编号。随后 M 行,每行给出一项任务的描述,格式为“任务起始里程碑 任务结束里程碑 工作时长”,三个数字均为非负整数,以空格分隔。
输出格式:
如果整个项目的安排是合理可行的,在一行中输出最早完工时间;否则输出"Impossible"。
输入样例 1:
9 12
0 1 6
0 2 4
0 3 5
1 4 1
2 4 1
3 5 2
5 4 0
4 6 9
4 7 7
5 7 4
6 8 2
7 8 4
输出样例 1:
18
输入样例 2:
4 5
0 1 1
0 2 2
2 1 3
1 3 4
3 2 5
输出样例 2:
Impossible
参考代码
代码解析
7-15 最短路径
给定一个有N个顶点和E条边的无向图,顶点从0到N−1编号。请判断给定的两个顶点之间是否有路径存在。如果存在,给出最短路径长度。
这里定义顶点到自身的最短路径长度为0。
进行搜索时,假设我们总是从编号最小的顶点出发,按编号递增的顺序访问邻接点。
输入格式:
输入第1行给出2个整数N(0<N≤10)和E,分别是图的顶点数和边数。
随后E行,每行给出一条边的两个顶点。每行中的数字之间用1空格分隔。
最后一行给出两个顶点编号i,j(0≤i,j<N),i和j之间用空格分隔。
输出格式:
如果i和j之间存在路径,则输出"The length of the shortest path between i and j is X.“,X为最短路径长度,
否则输出"There is no path between i and j.”。
输入样例1:
7 6
0 1
2 3
1 4
0 2
1 3
5 6
0 3
输出样例1:
The length of the shortest path between 0 and 3 is 2.
输入样例2:
7 6
0 1
2 3
1 4
0 2
1 3
5 6
0 6
输出样例2:
There is no path between 0 and 6.
参考代码
代码解析
7-16 最短路径算法(Floyd-Warshall)
在带权有向图G中,求G中的任意一对顶点间的最短路径问题,也是十分常见的一种问题。
解决这个问题的一个方法是执行n次迪杰斯特拉算法,这样就可以求出每一对顶点间的最短路径,执行的时间复杂度为O(n 3)。
而另一种算法是由弗洛伊德提出的,时间复杂度同样是O(n 3),但算法的形式简单很多。
在本题中,读入一个有向图的带权邻接矩阵(即数组表示),建立有向图并使用Floyd算法求出每一对顶点间的最短路径长度。
输入格式:
输入的第一行包含1个正整数n,表示图中共有n个顶点。其中n不超过50。
以后的n行中每行有n个用空格隔开的整数。对于第i行的第j个整数,如果大于0,则表示第i个顶点有指向第j个顶点的有向边,且权值为对应的整数值;如果这个整数为0,则表示没有i指向j的有向边。
当i和j相等的时候,保证对应的整数为0。
输出格式:
共有n行,每行有n个整数,表示源点至每一个顶点的最短路径长度。
如果不存在从源点至相应顶点的路径,输出-1。对于某个顶点到其本身的最短路径长度,输出0。
请在每个整数后输出一个空格,并请注意行尾输出换行。
输入样例:
4
0 3 0 1
0 0 4 0
2 0 0 0
0 0 1 0
输出样例:
0 3 2 1
6 0 4 7
2 5 0 3
3 6 1 0














 4153
4153











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









