







声明:本篇文章是本人课程作业的内容,只提供平时学习参考使用,请勿转载。
介绍:数据挖掘
来源:kaibo_lei_ZZU
本片文章是使用分类算法KNN,和SVM支持向量机分类算法,对Wine数据集进行分类的实现。
1.1 wine数据集
Wine葡萄酒数据集是来自UCI上面的公开数据集,这些数据是对意大利同一地区种植的葡萄酒进行化学分析的结果,这些葡萄酒来自三个不同的品种。该分析确定了三种葡萄酒中每种葡萄酒中含有的13种成分的数量。从UCI数据库中得到的这个wine数据记录的是在意大利某一地区同一区域上三种不同品种的葡萄酒的化学成分分析。数据里含有178个样本分别属于三个类别,这些类别已经给出。每个样本含有13个特征分量(化学成分),分析确定了13种成分的数量,然后对其余葡萄酒进行分析发现该葡萄酒的分类。

数据集中包含两个数据文件
Wine.data 包含所有数据的数据文件
Wine.names 数据集描述文件
我对这些数据集的处理,以及数据集分析和分类实现使用的环境是MATLAB R2017a。
1.2 wine数据集属性描述
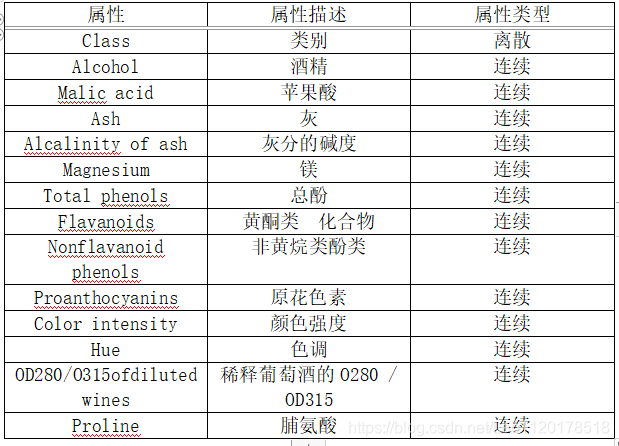
在wine数据集中,这些数据包括了三种酒中13种不同成分的数量。文件中,每行代表一种酒的样本,共有178个样本;一共有14列,其中,第一个属性是类标识符,分别是1/2/3来表示,代表葡萄酒的三个分类。后面的13列为每个样本的对应属性的样本值。剩余的13个属性是,酒精、苹果酸、灰、灰分的碱度、镁、总酚、黄酮类化合物、非黄烷类酚类、原花色素、颜色强度、色调、稀释葡萄酒的OD280/OD315、脯氨酸。其中第1类有59个样本,第2类有71个样本,第3类有48个样本。
具体属性描述如下表:
1.3 原始数据集展示
原始数据文件是wine.data形式的文件,这些data文件的内容是以纯文本和逗号分隔格式编码的数据。该类型文件为使用者提供了很好的分析功能,有助于实时数据研究,存储,管理和分析。
这里只展示原始数据文件中前20条数据。

1.4数据处理
由于我们下载的源数据中可能存在各种各样的数据,因此不经任何处理就进入处理数据很可能违背数据质量三要素的要求。用这样的数据在进行后续的数据挖掘,其可靠性可能会有很大的偏差。我们首先需要做的就是处理数据中的缺失数据或异常值。我们需要提高数据质量,对下载的原始数据进行数据清理过程。
首先进行的数据清洗的步骤相对较为简单与清晰,第一步需要进行偏差检测,即检查导致偏差的因素,并识别离散值与噪声值。然后进行数据清洗,即处理缺失值与噪声。在本数据集中由于数据都是连续的,而且通过对数据集的分析可以发现,数据集中一共有178个样本,由于数据源文件中的每个样本的数据都是完整的,没有空缺值等,所以我没有对该数据源文件进行数据的清理工作。
原始数据集中是178个样本值,14列属性值,但是第一列是类别标识号,所以我们需要把这一列数据拿出单独作为对比列,作为一个1781的矩阵。然后把剩余的属性作为一个待处
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









