







声明:本篇文章是本人课程作业的内容,只提供平时学习参考使用,请勿转载。
介绍:数据挖掘
来源:kaibo_lei_ZZU
ILPD数据集
ILPD数据集来自美国加州大学一个统计学习相关的网站上(UCI)数据集的名称叫做Indian Liver Patient Dataset印度肝病患者数据集,这个数据集由三个印度的教授收集自印度安得拉邦的东北部,包含了416个肝癌病人和167个非肝癌病人共计583个肝病患者的病历数据记录。583个病人中包含441名男性病人和142名女性病人,其中任何年龄超过89岁的患者都被列为年龄90。
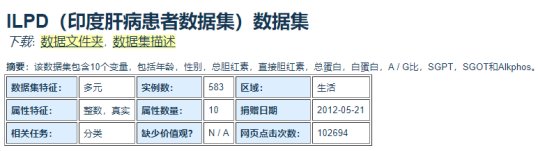
ILPD数据集属性描述
在ILPD数据集中,该数据集包含416个肝脏患者记录和167个非肝脏患者记录。共计10个主要属性,以及583个样本数,里面有肝病患者和非肝病患者的记录。
具体属性描述如下表:

原始数据集展示
该数据集是一个CSV格式的数据文件,一共有538行11列数据。
下图是对原始数据集的前25条数据展示:

数据的第一列代表患者年龄,第二列为患者性别。在这里性别是一个字符串形式的表示,我们在下面的数据分析中需要把数据转换为离散型的数据表示,可以方便我们的数据分析。数据的最后一行表示是否患病,1表示肝癌病人,2表示非肝癌病人。
数据处理
首先进行数据的简单预处理,进行偏差检测,即检查导致偏差的因素,并识别离散值与噪声值。然后进行数据清洗,即处理缺失值与噪声,通过观察数据集我们可以发现在数据集的第二列,性别表示中男性是male表示,女性是female表示,为了能让提高我们的分类准确率,这里需要进行替换,男性male用1表示,female用2来表示。
处理后的数据集表示如下:

1. BP(反向传播)算法实现
BP算法描述
BP算法(Back-propagation),误差反向传播算法,它的基本思想:学习过程由信号的正向传播(求损失)与误差的反向传播(误差回传)两个过程组成。网络的运行流程为:当输入一个样例后,获得该样例的
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 621
621











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









