







FIFO queue
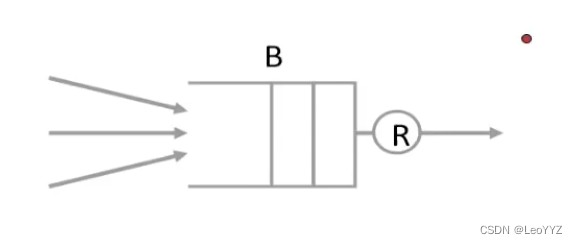
如果有多个flow经过这个queue,
传输速率最高的flow就相当于receive highest usage of this output link
使得其他的flow只能通过这个link发送相对少的多的packets
虽然FIFO queue非常简单,but encourage bad behavior

如图所示
从上到下三个flow,越靠近上的flow传输rate越高
它send out的最终顺序就会是123456
对于一些需要urgent control traffic情况来说不太好 (video traffic)
FIFO does not have any way to distinguish important packets(first arrived one is the most important!)
Strict priorities
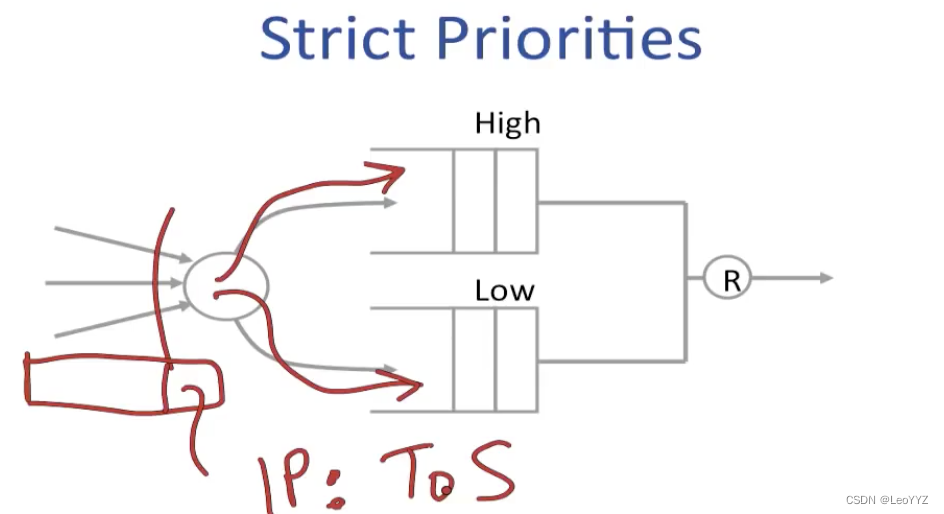
到达的packet的IP header中有ToS section包含了这个packet是否是high priority
比如说我们认为video traffic is more important than emails,video的priority就高于email
或者一些网站中,gold customer的priority > silver customers
在output的出口有一个scheduler,当且仅当high priority queue为empty时,它才允许packets from low priority queue离开
high priority packets不会看到low priority traffic
缺点:仅在high priority需求较小的时候使用,因为不希望starve out lower priority traffic,换句话说,我们不希望completely hog the link
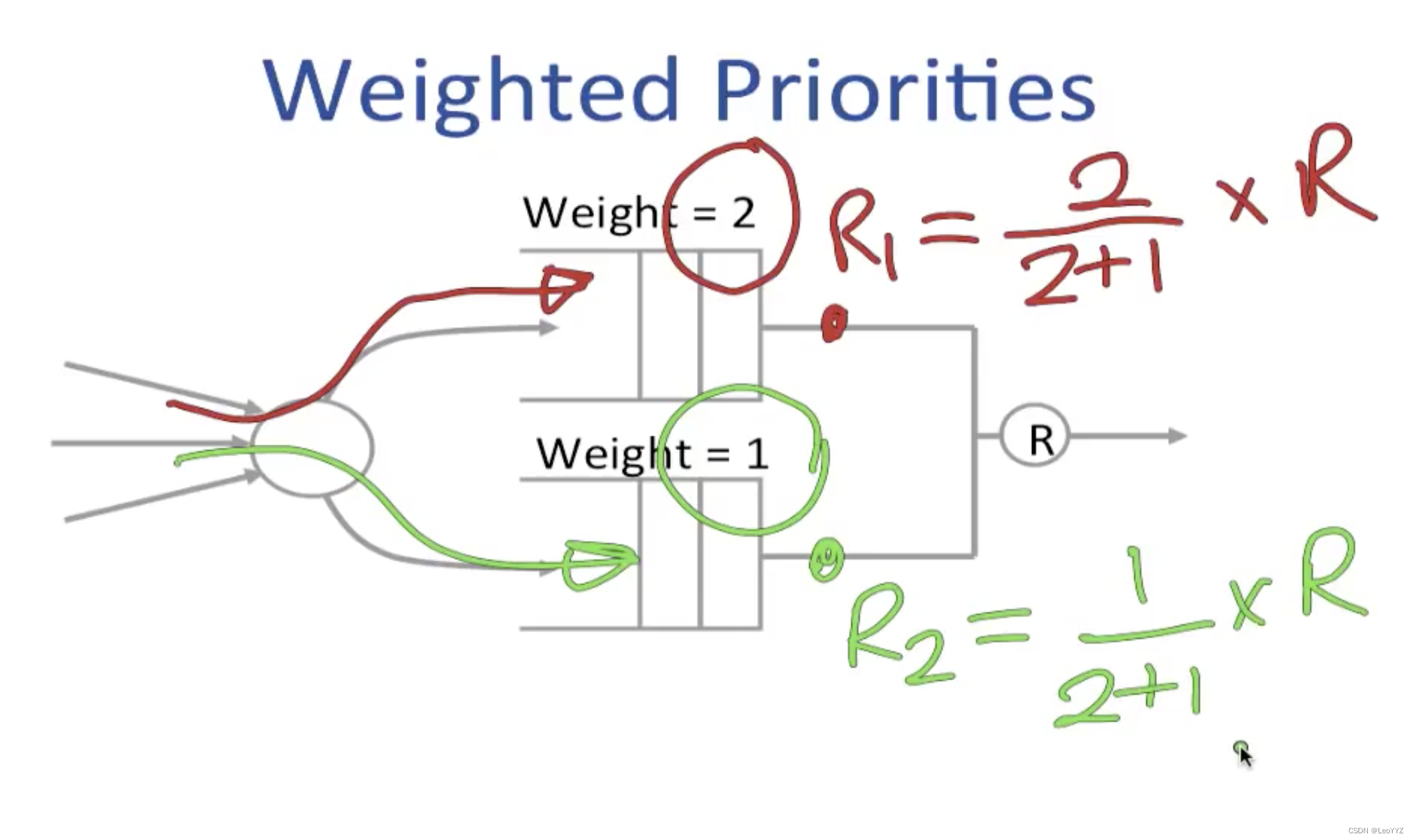
Weighted Priorities
不像strict priority一样严格,而是以一定的比例传输不同priority traffic
扩展到n个flow
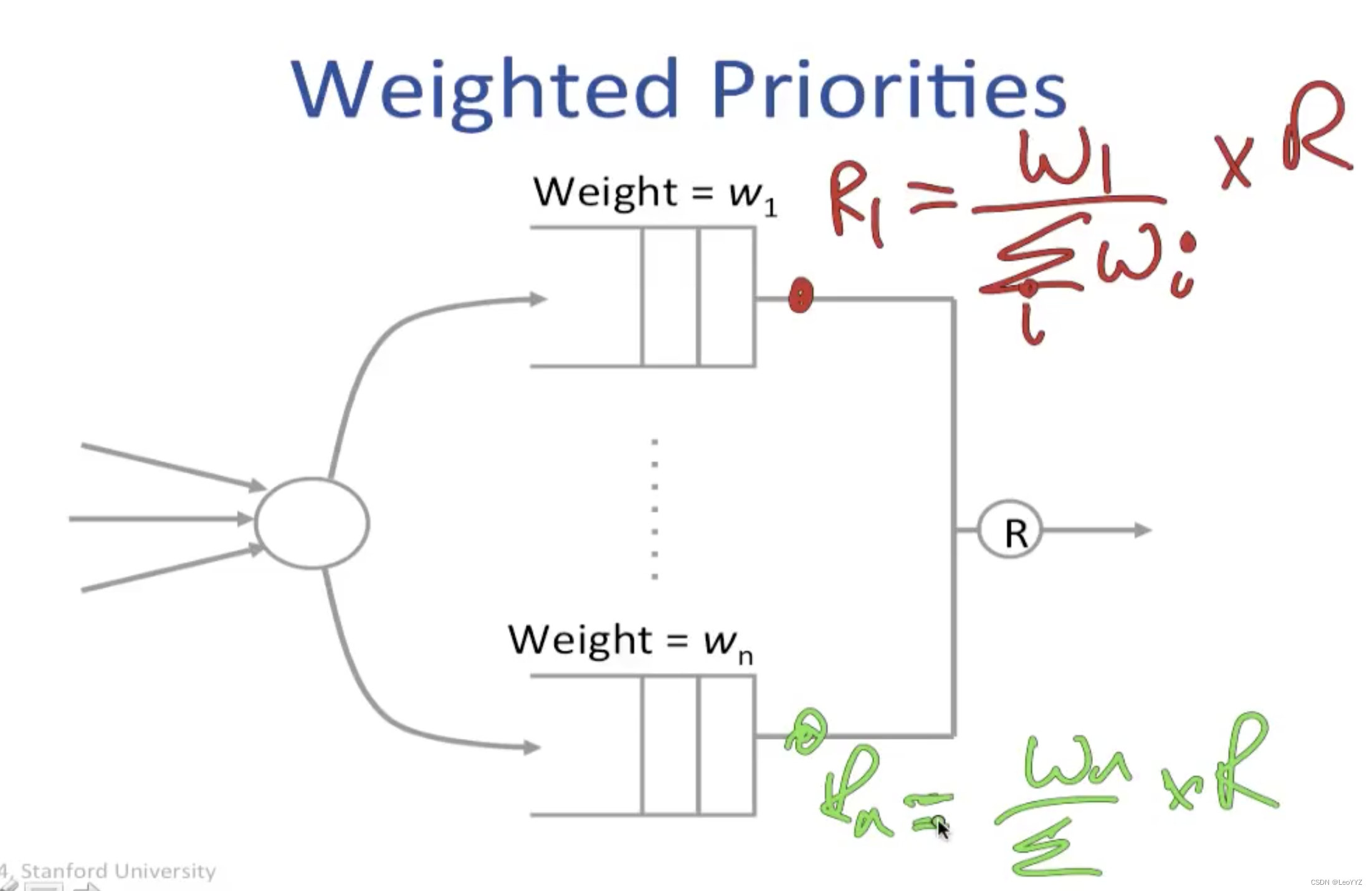
当到达的packet都有相同的长度,它们会visit all queues in turn
我们把经过所有queue称作一个round
但事实上每个packet的长度都不同 (Possibly from 64bytes to 1500bytes)
我们需要考虑到long packets crowded out short ones
Weighted Fair Queueing
特性:weight usage + weighted fairness + rate guarantees
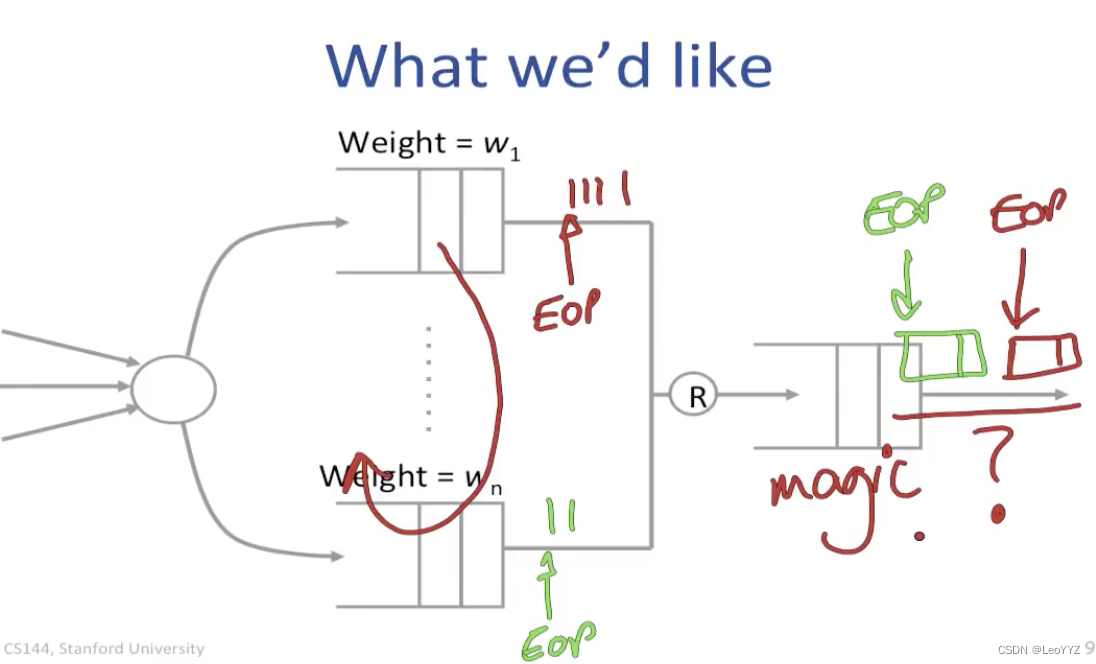
单位时间为round(遍历过每个queue)
第一个问题 如果每个queue serve bit by bit,which round will they finish
假设这个packet的头部是处在round Sk,等到达尾部后处在round Tk (queue service start/end)
Tk = Sk + L/w1
而且 Tk = S(k-1)
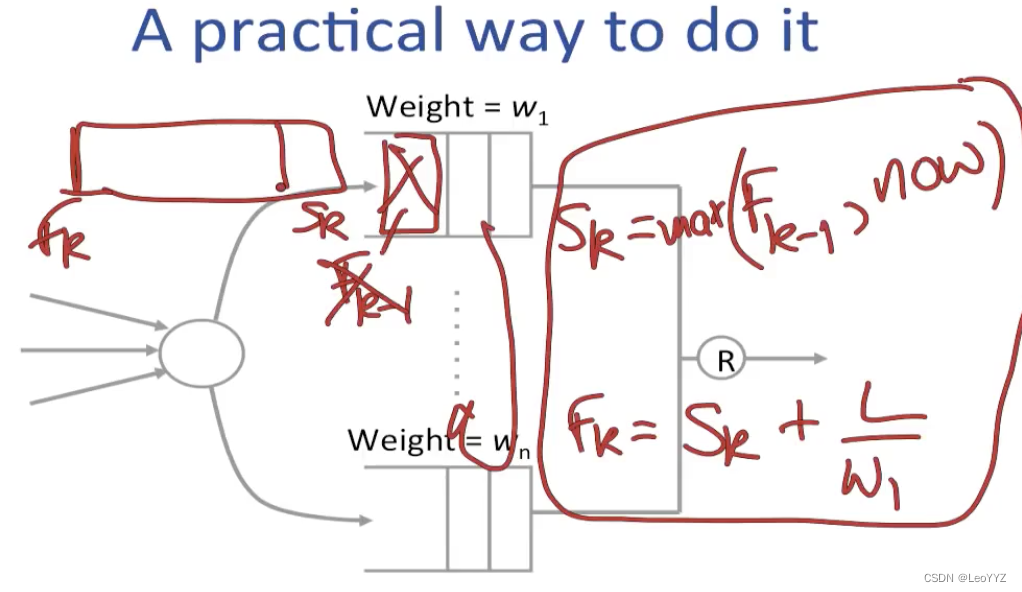
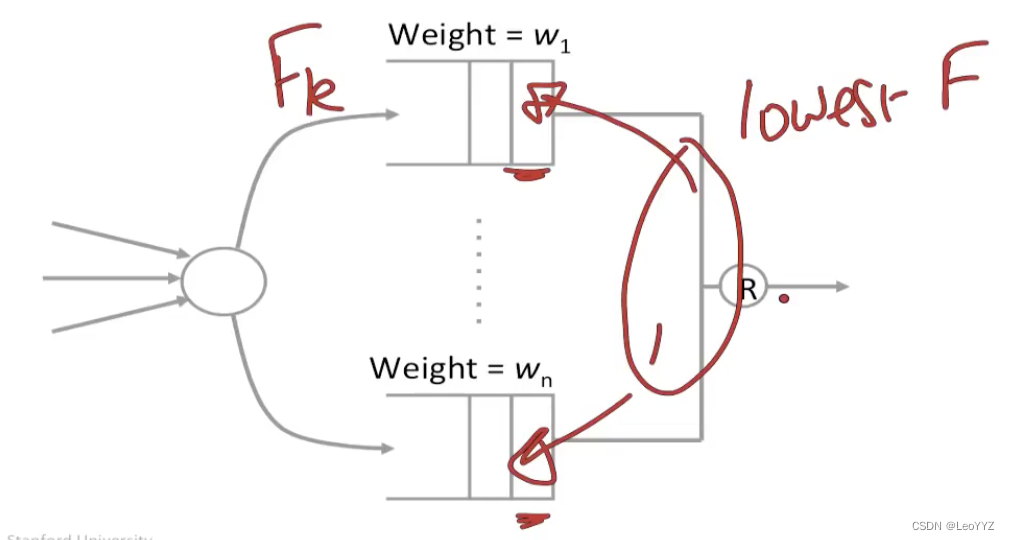
然后在出口的scheduler会选择有最小的Fk的packet
先计算每个arriving packet的Fk,然后output那个Fk最小的
从weighted queueing中我们可以得到
如果是bit by bit的queue
它的rate Ri = (Wi/W)*R(其中W和R都是所有queue的w和r求和)
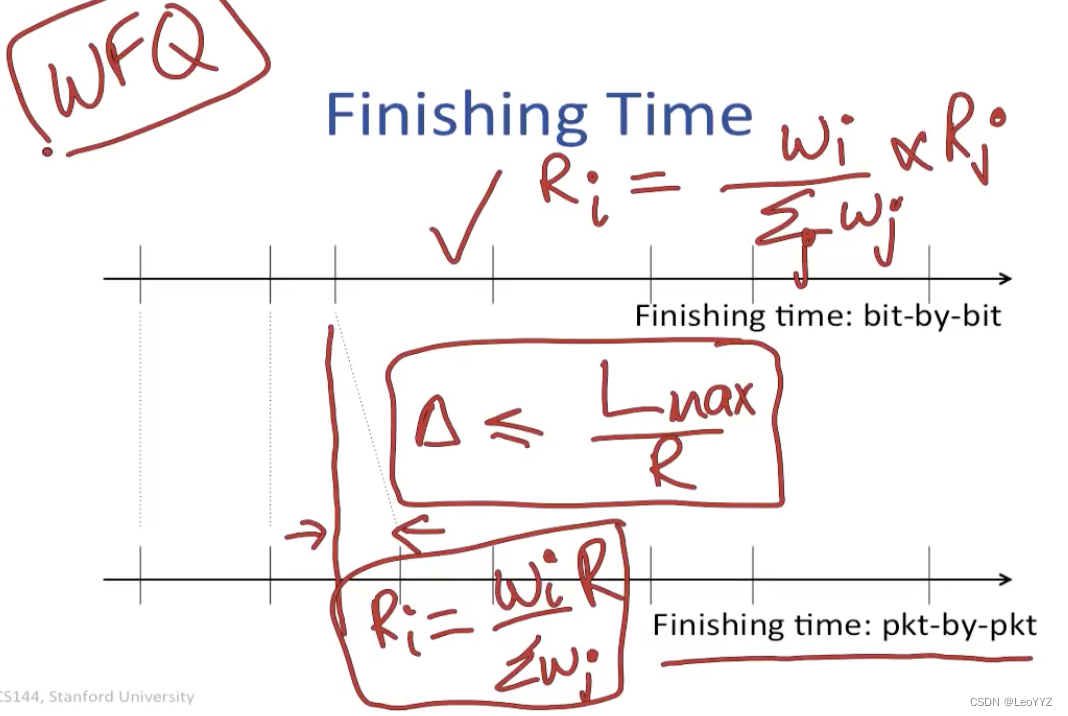
如果是packet by packet的方式 (e.g. weighted fair queue)
和bit-by-bit的差值不会大于Lmax/R (即最长的packet)
虽然p by p的方式会和b by b的有一定variance,但measuring from a long period of time是差不多的
所以也可以用rate Ri = (Wi/W)*R的公式















 5181
5181











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









