



 本文介绍了一种名为Sequencer的新模型,它利用LSTM代替self-attention机制来处理计算机视觉任务,并展示了在高分辨率图像上的优秀性能。Sequencer在ViT的基础上替换self-attention层为BiLSTM层,进一步引入二维LSTM结构,增强了模型的空间建模能力。
本文介绍了一种名为Sequencer的新模型,它利用LSTM代替self-attention机制来处理计算机视觉任务,并展示了在高分辨率图像上的优秀性能。Sequencer在ViT的基础上替换self-attention层为BiLSTM层,进一步引入二维LSTM结构,增强了模型的空间建模能力。
0. Abstract
在计算机视觉领域,ViT利用了self-attention机制在视觉下游任务中取得很好的效果,而例如MLP-Mixer以及一些经过特别设计的CNN也达到了与ViT媲美性能。在这种背景下,我们会疑惑适合计算机视觉领域的归纳偏置是什么(inductive bias)?
文章从一个新的视角探索LSTM在计算机视觉领域的可行性,提出了Sequencer,利用LSTM代替self-attention进行长程时序建模。文章继续挖掘LSTM的潜力,提出了一种二维的LSTM结构(分为水平和垂直方向),提高了性能。
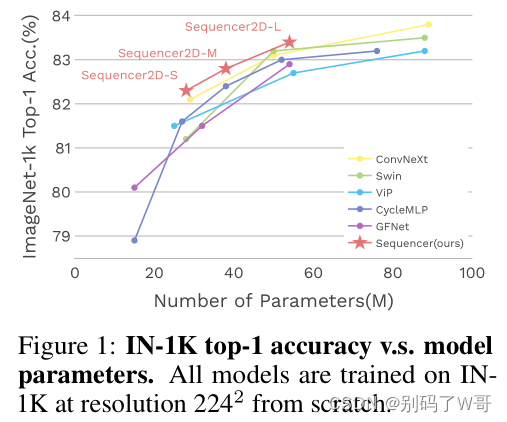
1. Introduction
ViT(Vision Transformer)借鉴于NLP领域的Transformer结构在图像下游任务实现了很好的性能,它的成功被认为是self-attention结构具有长程依赖建模能力。但是:
-
MLP-Mixer(多层感知机)
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/95ed1de942860ceadb7255bebafc87a1.png)
-
特别设计的CNN架构(大核卷积等)
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/fd9cdfc893699bb671827405227b1633.png)
这些结构的成功,表明self-attention不是ViT成功的关键。文章提出的Sequencer,采用了ViTs的结构,但是将self-attention层替换为BiLSTM层(双向LSTM)。而受启发于ViP(Vision Permutator),文章设计的BiLSTM2D对图片patch进行了水平和垂直的建模,达到了性能和精度提升。
- ViP
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/442c76b37c61995ee807c5295314e6ee.png)
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/e72412b1356fff8c7c59d362ee030c23.png)
在探索LSTM于CV领域的可用性上,文章也发现了Sequencer展现出很好的分辨率适应性,这很好的防止在inference阶段分辨率倍增造成的精度衰退。同时,Sequencer在高分辨率数据的fine-tuning达到了超越Swin-B的精度,并且更加的lightweight。
2. Related works
-
self-attention族
- iGPT:causal self-attention的自回归预训练,应用于低分辨率图片任务
- ViT:将self-attention应用于图片patch
-
MLP族
- MLP-Mixer:替换ViT的self-attention为全连接层,质疑了self-attention的作用,但不能在推理阶段灵活地对图片进行cope
- CycleMLP:解决了MLP-Mixer的问题,达到input size的自适应
-
其他
- GFNet:利用tokens的傅里叶变换,在频域内通过global filter对tokens进行混合
- PoolFormer:只对tokens进行local pooling,证明简单的local pooling操作也有好效果
-
ReNet(与Sequencer最相关的工作)
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/5463fab314ad3ce252ad47f6d2437051.png)
- 相同点:采用四路循环神经网络,以image patch作为输入
- 不同点:
1)Sequencer是第一个采用LSTM作为token mixing block,而ReNet采用RNN
2)Sequencer采用并行的双向结构,而ReNet采用了串行结构
3)Sequencer在ImageNet上训练,而ReNet只受限于训练小型数据集MNIST
3. Method
3.1. Preliminaries: Long short-term memory
-
LSTM结构简介
-
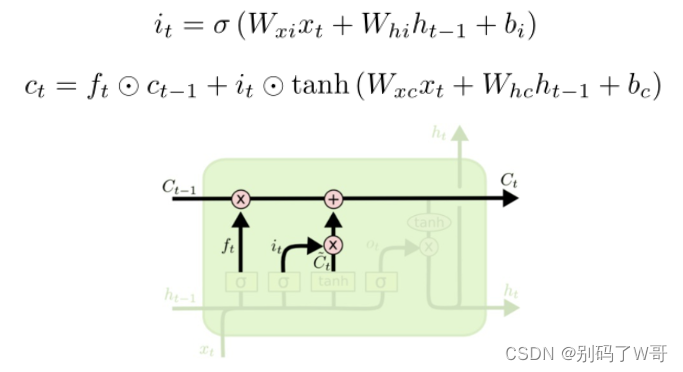
遗忘门:记录应该丢弃当前帧的什么信息(帧间冗余)
![[图片]
[图片]](https://i-blog.csdnimg.cn/blog_migrate/80fab1e5c5ac895e7fe58827b3715f80.png)
-
输入门:擦除冗余信息,并写入当前帧应该被接受的信息,生成一个“日记本”(C)
-
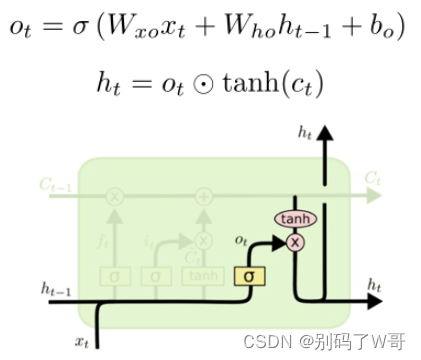
输出门:当前帧信息加上从“日记本”上记录的信息
-
-
双向LSTM —— BiLSTM
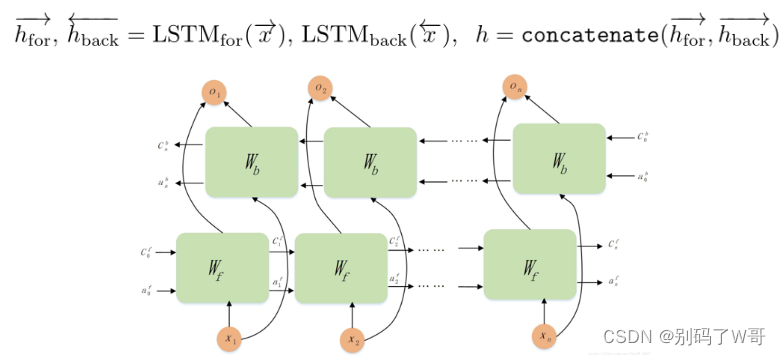
- 用于捕捉双向语义依赖:对于相互邻接的image patch之间的相互依赖进行建模
3.2. Sequencer architecture
-
Overall architecture
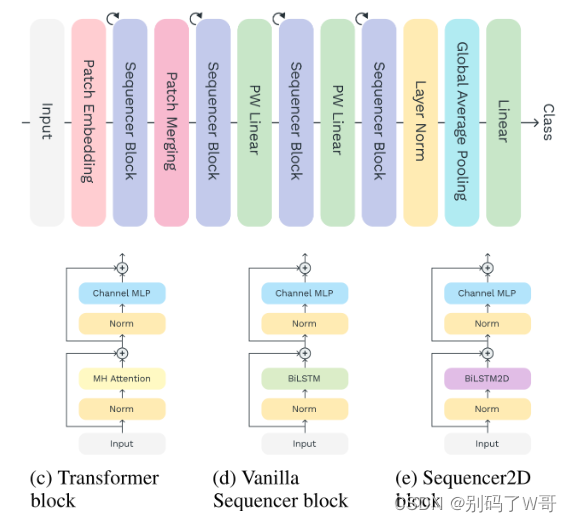
- 对ViT结构的沿用,用LSTM block替换self-attention block
- BiLSTM layer:对高分辨率图像的空间信息mixing比Transformer层更高效
BiLSTM:O(W2C)BiLSTM: O(W^2C)BiLSTM:O(W2C)Transformer:O(W4C)Transformer:O(W^4C)Transformer:O(W4C) - PW Linear(Point-wise卷积,即MLP层):进行通道信息mixing
-
BiLSTM2D layer
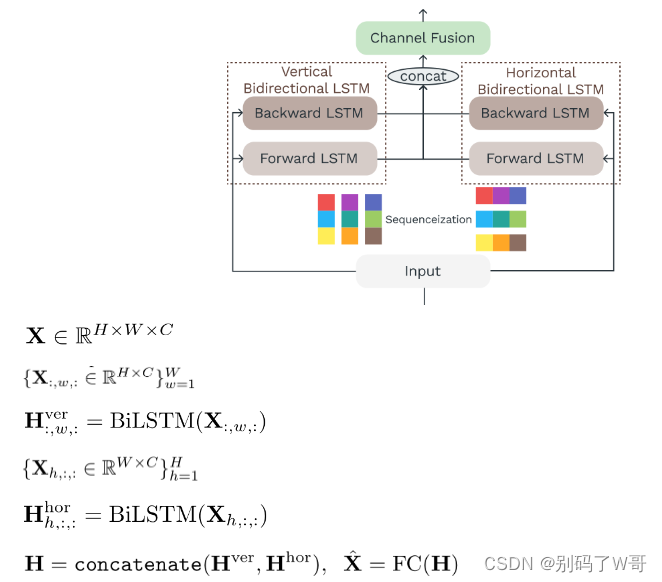
4. Experiments
4.1. IN-1K
- Sequencer2D-S,Sequencer2D-M,Sequencer2D-L → batch_size = 2048, 1536, 1024
- ↑:fine-tuning
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d97cf252e6e27a5799c44d350591a6ea.png)
4.2. Ablation studies
-
vertical(C1), horizontal(C2) BiLSTM and channel fusion(C3) 对Sequencer2D是必要的
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/d157b6ebf048de491b476f0918a5a06d.png)
-
双向LSTM能达到好效果
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/1711fbd4f25a1af4165d2245e1ead50e.png)
-
Hidden dimension设置为D=C/4
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/e50b9a42dbbe016ba3e6870b274f3884.png)
-
2D结构是必要的
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/4de82700f8aa179e29180aca371c3f3c.png)
- VSequencer-S:原始的双向LSTM block(没有级联结构)
- VSequencer(H)-S:原始的双向LSTM block
- VSequencer(PE)-S:加上position embedding原始双向LSTM block
- Sequencer2D-S:加上2D结构(水平+垂直)
-
LSTM相比其他循环结构更好
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/4e6bd5adca132ea7498e979aaf793003.png)
4.3. Analysis(优势)
-
强大的分辨率自适应能力
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/ef599f3724a4fadf64e751d845424459.png)
-
相比于其他模型,Sequencer输入分辨率越高,其内存效率和吞吐量就越高
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/8345802aeea4d3751947d0d3987be5a3.png)
-
Sequencer中的LSTMs可以对长程依赖进行建模,并且识别足够长的垂直或水平区域
![[图片]](https://i-blog.csdnimg.cn/blog_migrate/10f7a25a9ce3f03e52a3d987de666963.png)
5. Conclusions
- self-attention的长程依赖建模可以通过LSTM实现
- 实验展示了Sequencer有很好的精度-参数tradeoffs,但模型吞吐量表现糟糕
- LSTM在CV的尝试引导我们去探索什么是适合CV领域的归纳偏置

















 321
321

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









