






系列文章目录
前言
由于很多时候没网路导致看不了小说,所以就用python写了一个爬取小说的
一、爬虫是什么?
是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。
二、使用步骤
1.获取网页源代码
代码如下(示例):
header = {'user-agent': 'Mozilla/5.0'}
req = requests.get('https://www.*****.com/2_2395/', headers=header)
html = req.text
代码就这样,htnl就是url的网页源码
2.获取章节编号
获得网页源码后变要对它进行筛选,来获取我们想要的数据 代码如下:
soup = BeautifulSoup(html, 'html.parser')
for items in soup.find_all('div', id='list')://获取id为list 里面dd标签里面的超链接
item = items.select('dd a')//将数据存到数组里
for it in item:
print(str(it).encode('raw_unicode_escape').decode('GBK'))//打印数组后面加的是反正中文乱码
循环打印出来的结果就是这样
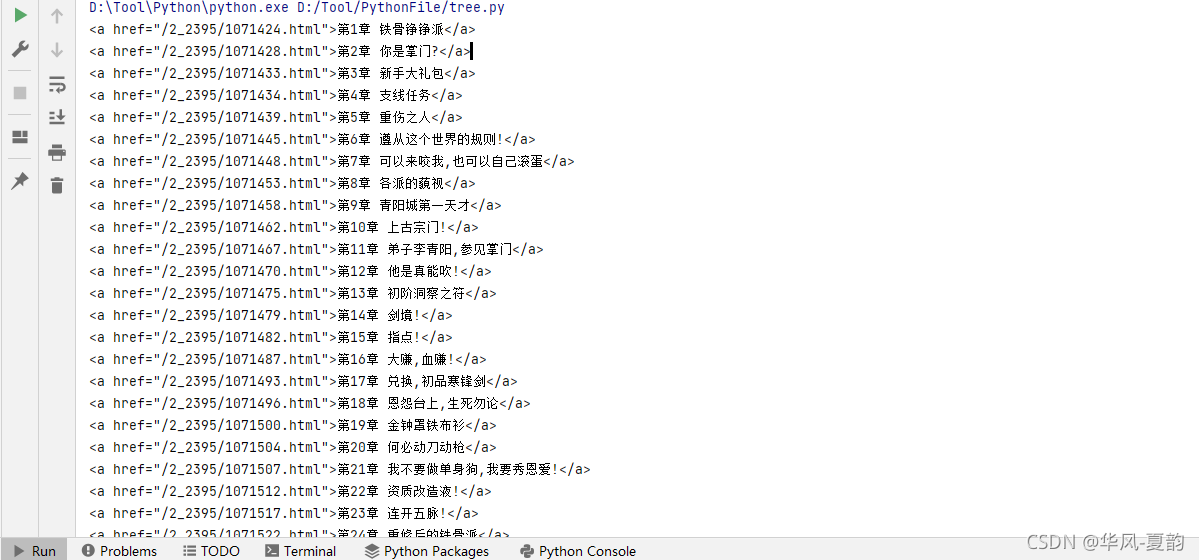
由于我们只需要href里最后一个/后面的章节编号就行,所以在截取一下 代码如下:
for it in item:
itemUrl = str(it).split("\"")[1]
number = itemUrl[itemUrl.rindex('/') + 1:len(itemUrl)] # 截取章节编号
print(number)
代码执行效果如下:
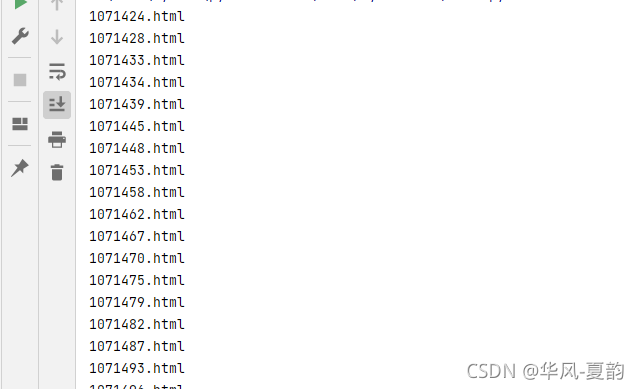
3.获取章节内容
req_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': '__cfduid=d577ccecf4016421b5e2375c5b446d74c1499765327; UM_distinctid=15d30fac6beb80-0bdcc291c89c17-9383666-13c680-15d30fac6bfa28; CNZZDATA1261736110=1277741675-1499763139-null%7C1499763139; tanwanhf_9821=1; Hm_lvt_5ee23c2731c7127c7ad800272fdd85ba=1499612614,1499672399,1499761334,1499765328; Hm_lpvt_5ee23c2731c7127c7ad800272fdd85ba=1499765328; tanwanpf_9817=1; bdshare_firstime=1499765328088',
'Host': 'www.qu.la',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://www.qu.la/book/1265/765108.html',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36'
}
txt_section = 'https://www.biqooge.com/2_2395/'+ number //要下载章节的路径
r = requests.get(txt_section, params=req_header)
r.encoding='GBK'//设置编码否则会中文乱码
//soup转换
soup = BeautifulSoup(r.text, "html.parser")
// 获取章节名称
section_name = str(soup.select('#wrapper .content_read .box_con .bookname h1')[0].text)
// 获取章节文本
section_text = str(soup.select('#wrapper .content_read .box_con #content')[0].text)
//按照指定格式替换章节内容,运用正则表达式并将内容写入txt文件
with io.open("D:\%s.txt" % (section_name ), "a") as f:
f.write(section_name+"\n" + section_text)
print('开始下载' + section_name)
print('下载完成')
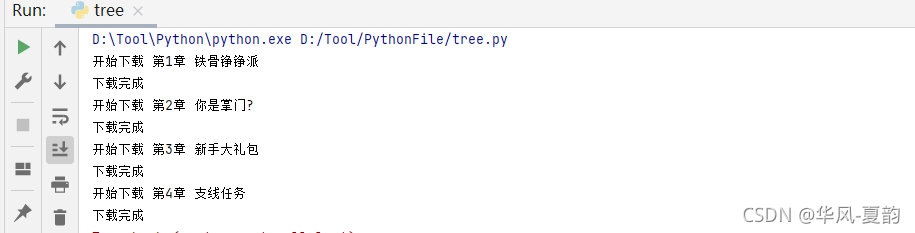
4.附上完整代码如下:
import io
import requests
import urllib.request
from bs4 import BeautifulSoup
import re
import os
import time
req_header = {
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'Accept-Encoding': 'gzip, deflate',
'Accept-Language': 'zh-CN,zh;q=0.8',
'Cookie': '__cfduid=d577ccecf4016421b5e2375c5b446d74c1499765327; UM_distinctid=15d30fac6beb80-0bdcc291c89c17-9383666-13c680-15d30fac6bfa28; CNZZDATA1261736110=1277741675-1499763139-null%7C1499763139; tanwanhf_9821=1; Hm_lvt_5ee23c2731c7127c7ad800272fdd85ba=1499612614,1499672399,1499761334,1499765328; Hm_lpvt_5ee23c2731c7127c7ad800272fdd85ba=1499765328; tanwanpf_9817=1; bdshare_firstime=1499765328088',
'Host': 'www.qu.la',
'Proxy-Connection': 'keep-alive',
'Referer': 'http://www.qu.la/book/1265/765108.html',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/59.0.3071.104 Safari/537.36'
}
item = [] #用来存放章节编号
#定义get_text函数
def get_text(name, url, number):
txt_section = url + number # 章节全路径
r = requests.get(txt_section, params=req_header)
r.encoding='GBK'
# soup转换
soup = BeautifulSoup(r.text, "html.parser")
# 获取章节名称
section_name = str(soup.select('#wrapper .content_read .box_con .bookname h1')[0].text)
# 获取章节文本
section_text = str(soup.select('#wrapper .content_read .box_con #content')[0].text)
# 按照指定格式替换章节内容,运用正则表达式
with io.open("D:\%s.txt" % (name), "a") as f:
f.write(section_name+"\n" + section_text)
print('开始下载' + section_name)
print('下载完成')
def get_text01(url, name):
item = []
header = {'user-agent': 'Mozilla/5.0'} # 模拟浏览器,防止被禁 2509
req = requests.get(url, headers=header)
html = req.text
#soup转换
soup = BeautifulSoup(html, 'html.parser')
for items in soup.find_all('div', id='list'):# 获取id为list 里面dd标签里面的超链接
item = items.select('dd a')
del item[:9] #由于笔趣阁的小说页面有固定8章小说会放在第一章前面 所以读取完后删除前9章
for it in item:
itemUrl = str(it).split("\"")[1]
number = itemUrl[itemUrl.rindex('/') + 1:len(itemUrl)] # 截取章节编号
get_text(name, url, number)
#调用get_text01() 要下那本小说点击进去然后将它的URL复制好就行了 name是小说名
get_text01(url='https://www.******.com/2_2395/', name='万古最强宗')
总结
由于是第一次写文章写的不好的地方请各位大佬谅解, 溜了溜了!














 162
162











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









